



 本文深入解析了两个实用的SQL技巧,一是如何从一张表中选取每个订单号对应时间最早的数据,二是如何根据条件查询并将结果字段按逗号合并。通过具体SQL语句示例,详细解释了over partition by和FOR XML PATH的使用方法,为数据库操作提供了高效解决方案。
本文深入解析了两个实用的SQL技巧,一是如何从一张表中选取每个订单号对应时间最早的数据,二是如何根据条件查询并将结果字段按逗号合并。通过具体SQL语句示例,详细解释了over partition by和FOR XML PATH的使用方法,为数据库操作提供了高效解决方案。
有两个导数据的需求,
1、一张表里面每一个订单号可能对应多条数据,每个单号返回时间最早的那条。
2、根据条件查询某个字段并按照逗号,合并在一起。
表类似结构如下:
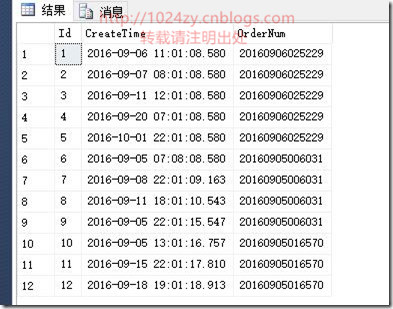
第一条sql:
select c.Id,c.OrderNum, c.CreateTime FROM (select t.*,row_number() over(partition by t.OrderNum order by t.CreateTime ) rn from Payinfo t WHERE t.OrderNum IN('20160906025229','20160905006031','20160905016570')) c WHERE rn = 1;
执行效果如下:
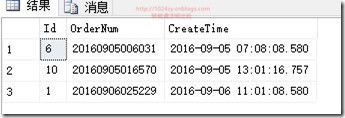
主要知识点:over partition by
over partition by关键字是分析性函数的一部分,它和聚合函数不同的地方在于它能返回一个分组中的多条记录,常用于给结果集分组,如果没有指定那么它把整个结果集作为一个分组 。
Group by 与 over partition by都可以实现分组统计功能.
Group by 根据一列或者多列的值或表达式将选定的行进行一个摘要分组,每一个分组只返回一行。
第二条sql:
SELECT TOP 1 data=STUFF((SELECT ','+ CAST(id AS VARCHAR(10)) FROM Payinfo t WHERE OrderNum IN('20160906025229','20160905006031') FOR XML PATH('')), 1, 1, '')
FROM Payinfo t1
执行效果如下:

主要知识点:FOR XML PATH
将查询结果集以XML形式展现,有了它我们可以简化我们的查询语句实现一些以前可能需要借助函数活存储过程来完成的工作。
有关FOR XML PATH更多知识,我觉得下面这篇文章讲的很好:
灵活运用 SQL SERVER FOR XML PATH

















 756
756

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









