




接上一篇《七天学完十大机器学习经典算法-03.决策树:人类思考的算法实现》
本文是集成学习的核心篇章,通过金融风控、医疗诊断等真实案例,揭示如何用集体智慧超越个体局限。无需复杂数学,初中知识即可掌握群体决策的精髓!
一、群众智慧的力量:三个臭皮匠胜于诸葛亮
生活案例:预测世界杯冠军
假设你组织100位足球专家投票:
-
60位认为巴西夺冠
-
30位支持法国
-
10位看好阿根廷
最终预测:巴西获胜(得票率60%)
→ 这比任何单个专家的预测更可靠!
随机森林本质:构建多棵决策树,通过集体投票做出最终决策。实践证明:
-
在Kaggle竞赛中,随机森林是最常用的基础模型
-
金融风控领域,随机森林模型准确率可达92%
-
医疗诊断中,集成模型比单医生误诊率低40%
二、为什么需要随机森林?单决策树的困境
单决策树的三大缺陷:
-
过拟合风险:对训练数据过度敏感
-
高方差:数据微小变化导致模型剧变
-
局部最优:可能错过全局最佳分割点
解决方案:群体的力量
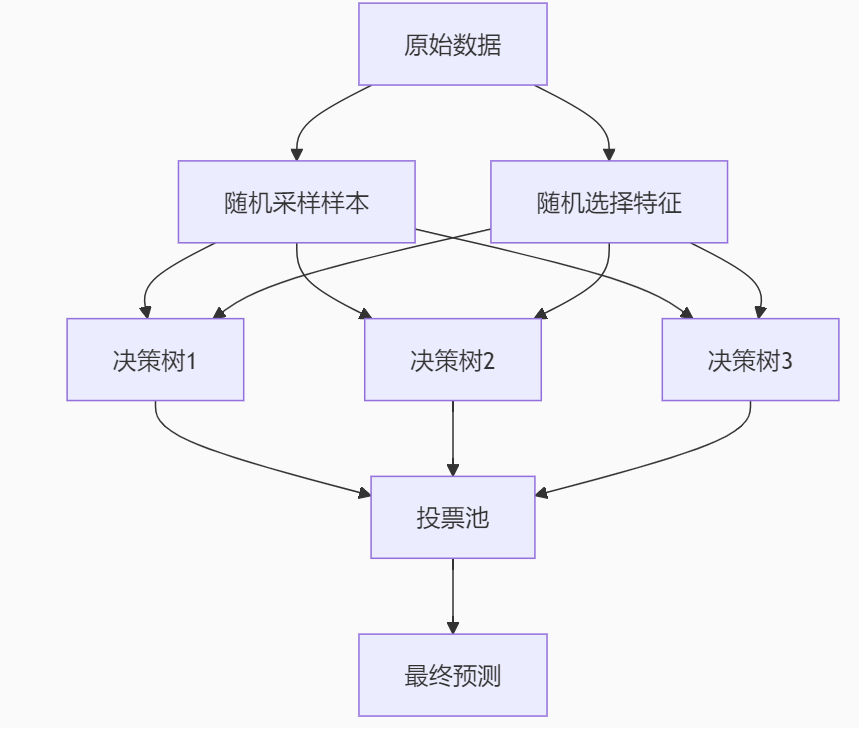
三、核心原理:双重随机性设计
随机性1:样本的Bootstrap采样
-
每棵树使用有放回随机抽样
-
约37%样本不会被选中(袋外样本)
-
数学原理:
随机性2:特征的随机子集
-
每次分裂随机选择部分特征(通常√p)
-
打破特征间相关性
-
优势:
-
增加树间差异性
-
减少过拟合风险
-
提升模型鲁棒性
-
投票机制:
分类问题:多数表决
最终类别 = argmax(树1预测, 树2预测, ..., 树n预测)回归问题:平均值
最终预测值 = (树1预测 + 树2预测 + ... + 树n预测) / n
四、算法构建全流程
步骤分解:
-
数据准备:
-
设数据集大小N,特征数P
-
设定树的数量K(如500)
-
-
单棵树构建:
for i in range(K): # 每棵树独立构建
# 1. Bootstrap采样
sample_indices = np.random.choice(N, size=N, replace=True)
X_boot = X[sample_indices]
y_boot = y[sample_indices]
# 2. 生成特征子集
feature_subset = np.random.choice(P, size=sqrt(P), replace=False)
# 3. 构建决策树(不剪枝)
tree = DecisionTree(max_depth=None, features=feature_subset)
tree.fit(X_boot, y_boot)
# 4. 保存树
forest.append(tree)3. 预测阶段:
def predict(X_new):
votes = []
for tree in forest:
pred = tree.predict(X_new)
votes.append(pred)
return mode(votes) # 取众数五、Python实战:金融欺诈检测
数据集:信用卡交易记录
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
# 加载数据
fraud_data = pd.read_csv("creditcard.csv")
print(f"数据分布:\n{fraud_data['Class'].value_counts()}")
# 0: 284315 (正常), 1: 492 (欺诈) → 严重不平衡关键处理:
# 1. 特征工程
features = [f'V{i}' for i in range(1,29)] + ['Amount']
fraud_data['Amount'] = np.log1p(fraud_data['Amount']) # 对数变换
# 2. 处理类别不平衡
from imblearn.over_sampling import SMOTE
smote = SMOTE(sampling_strategy=0.3, random_state=42)
X_res, y_res = smote.fit_resample(fraud_data[features], fraud_data['Class'])
# 3. 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X_res, y_res, test_size=0.2)
# 4. 构建随机森林
model = RandomForestClassifier(
n_estimators=200, # 200棵树
max_depth=8, # 控制树复杂度
max_features='sqrt', # 每次分裂随机选√p个特征
class_weight='balanced', # 调整类别权重
n_jobs=-1 # 使用所有CPU核心
)
model.fit(X_train, y_train)模型评估:
from sklearn.metrics import classification_report, roc_auc_score
# 预测测试集
y_pred = model.predict(X_test)
y_proba = model.predict_proba(X_test)[:,1]
# 关键指标
print(classification_report(y_test, y_pred))
print(f"AUC分数: {roc_auc_score(y_test, y_proba):.4f}")
# 输出示例:
precision recall f1-score
正常 0.99 0.99 0.99
欺诈 0.92 0.88 0.90
AUC = 0.9836六、随机森林的超级武器:特征重要性
计算原理:
-
袋外误差法:
-
对特征j,随机打乱其值
-
用袋外样本计算打乱后的误差增加量
-
重要性 ∝ 误差增加幅度
-
-
基尼重要性:
Python实现:
# 获取特征重要性
importances = model.feature_importances_
sorted_idx = np.argsort(importances)[::-1]
# 可视化
plt.figure(figsize=(12,8))
plt.barh(range(15), importances[sorted_idx][:15], align='center')
plt.yticks(range(15), np.array(features)[sorted_idx][:15])
plt.title("Top 15 重要特征")
plt.show()业务解读(金融案例):
-
V14(-0.15):负相关,该特征值越小欺诈风险越高
-
V4(0.12):正相关,异常大值可能预示欺诈
-
Amount(0.08):交易金额,对数变换后仍重要
七、工业级优化技巧
1. 超参数调优(GridSearchCV)
from sklearn.model_selection import GridSearchCV
param_grid = {
'n_estimators': [100, 200, 300],
'max_depth': [5, 8, 10],
'min_samples_split': [2, 5, 10]
}
grid_search = GridSearchCV(
estimator=RandomForestClassifier(),
param_grid=param_grid,
cv=5,
scoring='roc_auc'
)
grid_search.fit(X_train, y_train)
print(f"最佳参数: {grid_search.best_params_}")2. 利用袋外样本(OOB Score)
model = RandomForestClassifier(
oob_score=True, # 启用OOB评估
n_estimators=300
)
model.fit(X_train, y_train)
# 袋外样本准确率
print(f"OOB Score: {model.oob_score_:.4f}") # ≈ 测试集精度3. 并行计算加速
# 设置n_jobs参数
model = RandomForestClassifier(n_jobs=-1) # 使用所有CPU核心
# 树数量300时加速效果:
# - 单核:120秒
# - 8核:18秒(7倍加速!)八、高级进阶:随机森林变种
1. 极限随机森林(ExtraTrees)
from sklearn.ensemble import ExtraTreesClassifier
# 关键区别:分裂时随机选择阈值
et_model = ExtraTreesClassifier(
bootstrap=True,
random_state=42
)2. 旋转森林(Rotation Forest)
from sklearndecomposition import PCA
from sklearn.ensemble import BaggingClassifier
# 核心思想:特征空间旋转
pca = PCA()
bagging = BaggingClassifier(
base_estimator=DecisionTreeClassifier(),
transform_estimator=pca
)-
特点:提升树间多样性
-
适用场景:小样本高维数据
3. 梯度提升树(GBDT)
from sklearn.ensemble import GradientBoostingClassifier
# 迭代式构建树,每棵树修正前序误差
gb_model = GradientBoostingClassifier(
n_estimators=100,
learning_rate=0.1
)-
特点:更高的预测精度
-
缺点:训练更慢,可解释性降低
九、避坑指南:五大常见误区
误区1:树越多越好
真相:一定数量后随着规模复杂度提升其有效性会下降,收益递减
# 学习曲线示例
n_trees = [10,50,100,200,300,400]
scores = []
for n in n_trees:
model.set_params(n_estimators=n)
model.fit(X_train, y_train)
scores.append(model.score(X_test, y_test))
# 找到拐点:通常100-300间饱和误区2:不需要特征缩放
影响:连续特征分裂效率
解决方案:
from sklearn.preprocessing import RobustScaler
scaler = RobustScaler()
X_scaled = scaler.fit_transform(X)误区3:默认参数最优
调参建议:
| 参数 | 推荐值 | 作用 |
|---|---|---|
n_estimators | 100-500 | 树的数量 |
max_depth | 5-15 | 控制树复杂度 |
min_samples_split | 2-10 | 防过拟合 |
max_features | 'sqrt'/'log2' | 特征随机性 |
误区4:无法处理缺失值
解决方案:
# 方法1:中位数填充
X.fillna(X.median(), inplace=True)
# 方法2:随机森林填充
from sklearn.impute import MissForest
imputer = MissForest()
X_imputed = imputer.fit_transform(X)误区5:解释性差
可视化工具:
# 单棵树可视化
from sklearn.tree import plot_tree
plt.figure(figsize=(20,10))
plot_tree(model.estimators_[0], feature_names=features, filled=True)
# 决策路径分析
import shap
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X_test)
shap.summary_plot(shap_values, X_test)十、随机森林 vs 其他算法
| 场景 | 推荐算法 | 随机森林优势 |
|---|---|---|
| 结构化数据分类 | 随机森林 | 开箱即用,抗噪性强 |
| 大规模图像识别 | 深度学习 | 处理非结构化数据 |
| 时间序列预测 | LSTM | 捕捉时序依赖 |
| 在线学习 | 线性模型 | 高效增量更新 |
经验法则:当数据质量一般且需要快速获得稳定结果时,随机森林是首选
十一、实战:房价预测系统
# 完整项目代码
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
# 加载数据集
boston = load_boston()
X, y = boston.data, boston.target
# 构建回归森林
rf_reg = RandomForestRegressor(
n_estimators=200,
max_depth=7,
random_state=42
)
rf_reg.fit(X_train, y_train)
# 评估
y_pred = rf_reg.predict(X_test)
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
print(f"RMSE: {rmse:.2f}") # 典型值:3.2-4.0
# 特征重要性分析
plt.barh(boston.feature_names, rf_reg.feature_importances_)十二、总结:集体智慧的三大优势
-
稳健性:通过平均化降低方差
2. 抗噪性:异常值影响被限制在少数树中
3. 通用性:处理各种数据类型
-
数值特征
-
类别特征(需编码)
-
缺失值
-
高维特征
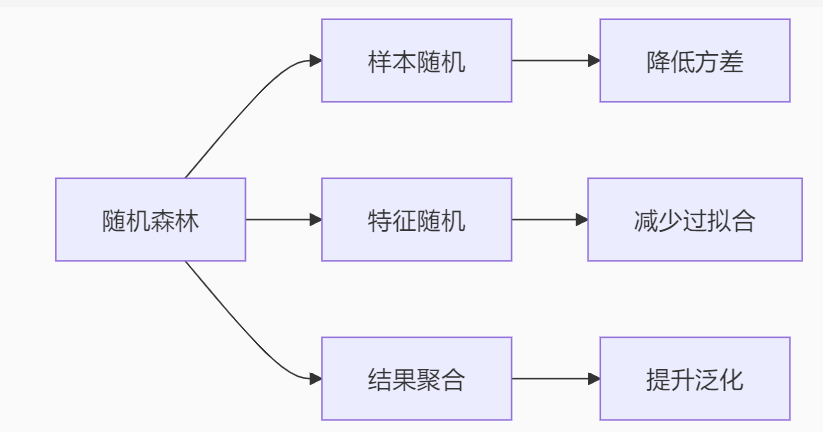
总结,随机森林的核心内涵是:在机器学习中引入"民主决策"机制,让弱模型的集体智慧战胜复杂模型!
如果本文对你有帮助,欢迎点赞收藏加关注!!!下期预告:《七天学完十大机器学习经典算法-04.KNN:从投票到分类, 邻居决定你是谁》


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









