




在日常生活中,12306 是中国铁路售票系统的官方平台。为了提升购票效率、自动化查询余票信息以及获取车站代码等功能,我们希望通过使用智能体编程方式,结合 MCP(Model-as-a-Service)技术实现,能随时随地访问 12306 提供的服务接口,并能够进行智能询问车次车票等信息,提高查询的简便性。
在这个过程中,我使用了阿里巴巴推出的智能编程助手——通义灵码,它帮助我快速构建项目结构、编写代码逻辑,并协助调试前后端交互中的常见问题。
通义灵码3.0新上线了,其编程智能体模式,具备自主决策、环境感知、工具使用等能力,可以根据开发者的编码诉求,使用工程检索、文件编辑、终端等工具,进行工程内多个文件的修改,端到端地完成编码任务。并且拥有丰富的MCP资源库,可调用3000多个MCP完成各种智能工作。
一、项目体验过程
现在我们来体验一下,通过VSCode插件找到并安装最新版本的通义灵码。
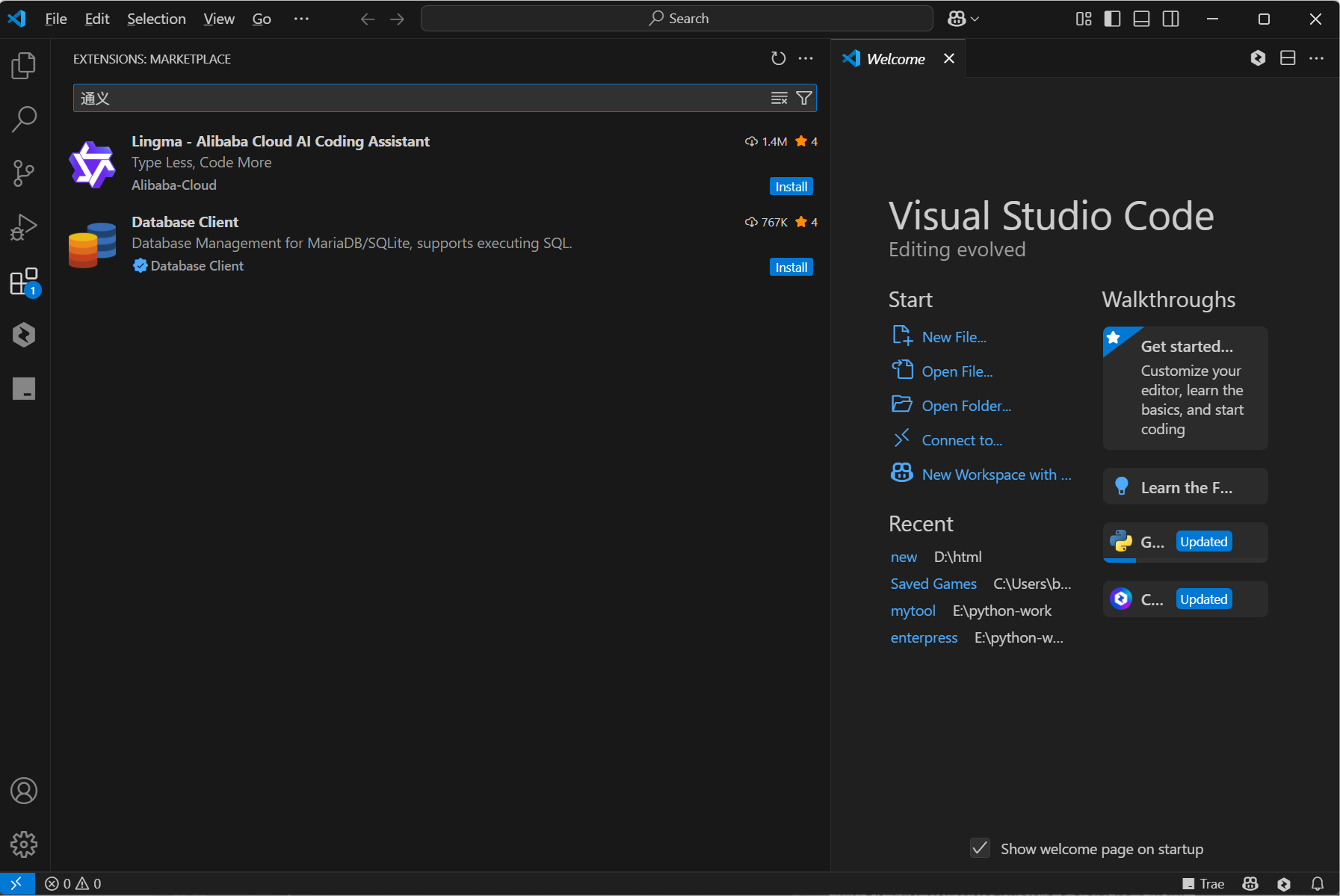
安装时需要选择信任发布者并安装(Trust Publisher & Install)。
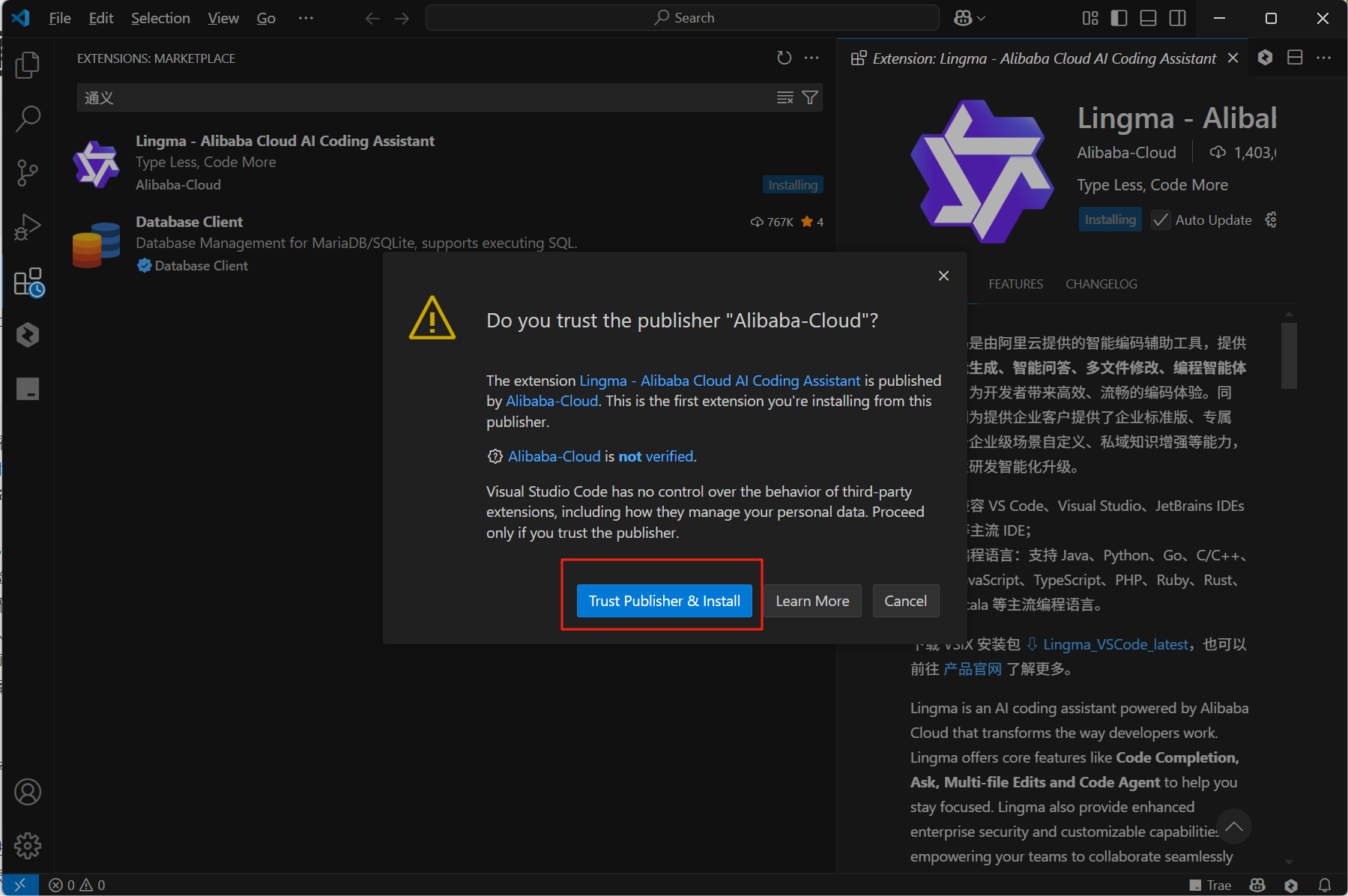
我们在对话框里面发现可以使用MCP功能,就是点击下面这个MCP工具按钮。
我们知道modelscope社区的MCP广场有很多优质的MCP资源,通过咱们的通义灵码可以直接访问MCP广场上的服务。
这里我们找到12306-mcp这个MCP并部署。如下图所示:
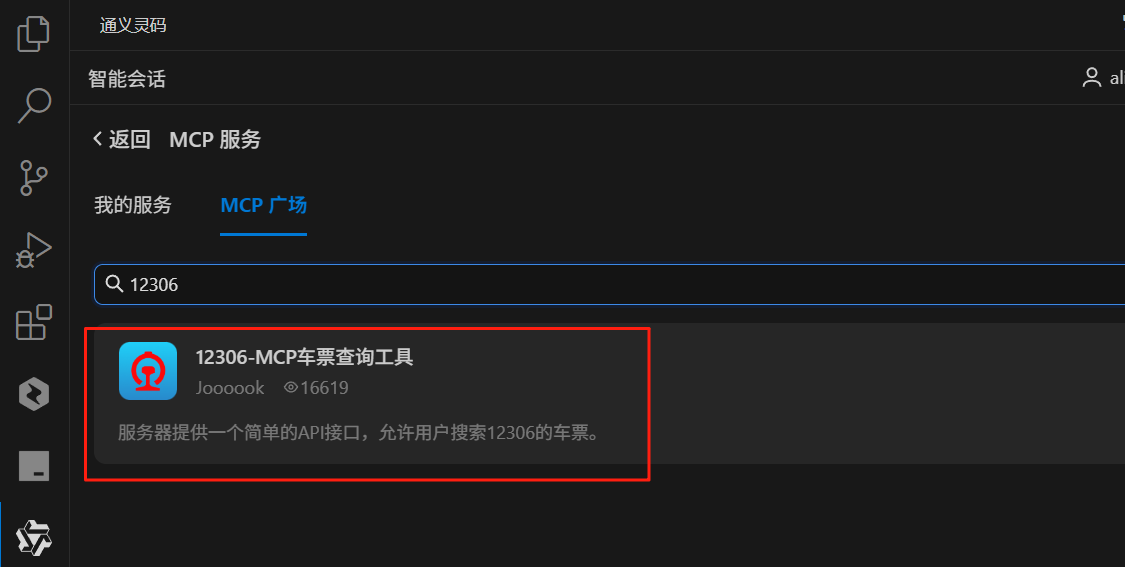
安装完成后在我的服务中可以找到已安装的MCP。
找到我们的12306-mcp。可以看到它提供的功能如下,非常丰富。
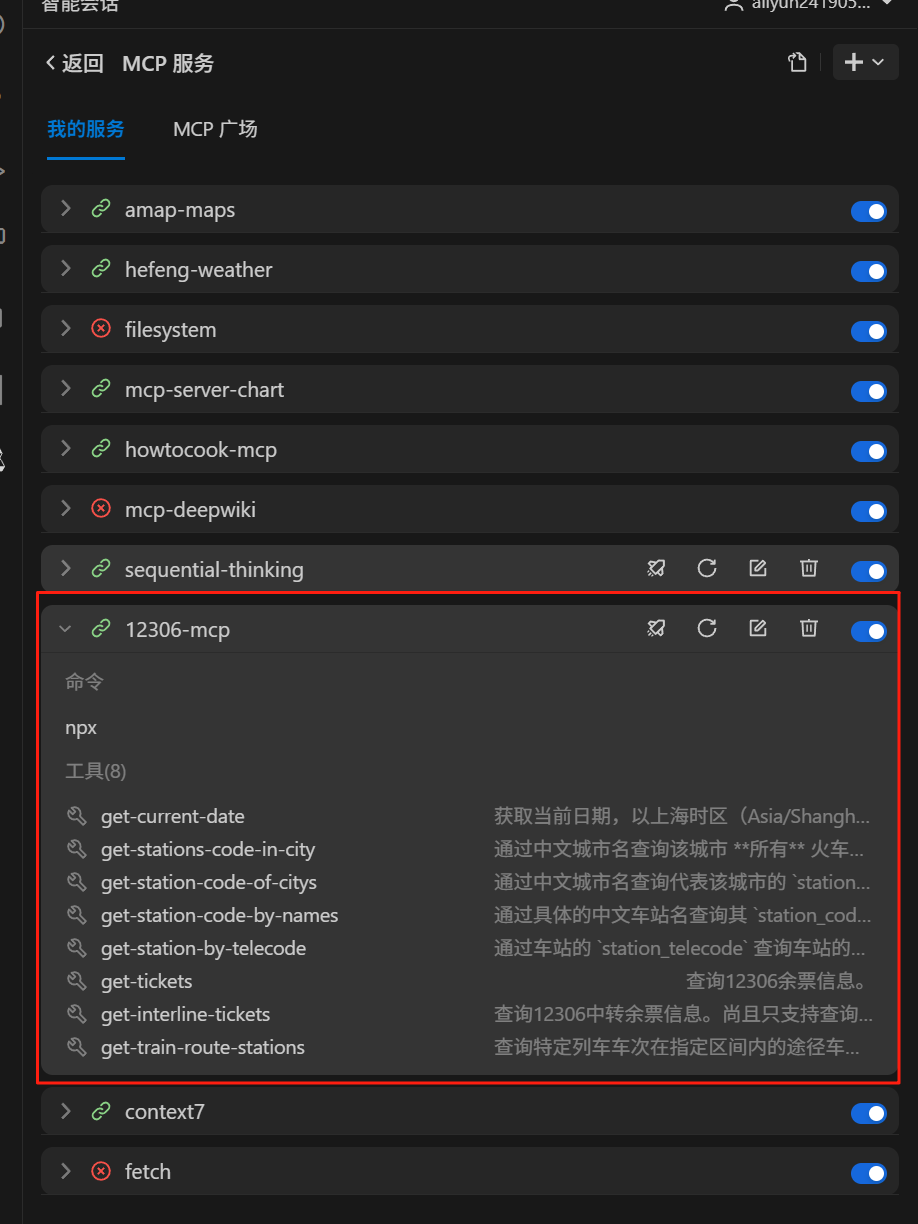
我们在通过与通义灵码智能体对话进行体验。
我直接提问智能体,模型用Qwen3。
Qwen3 是阿里巴巴集团旗下的通义实验室自主研发的超大规模语言模型,是 Qwen(通义千问)系列的最新一代版本。相比之前的 Qwen、Qwen2 等版本,Qwen3 在多个方面进行了重大升级和优化,具备更强的语言理解能力、生成能力、多模态支持以及更广泛的适用场景。
我问他:请帮我查询一下今天下午17:30之前武汉到广州的火车票。会话回答结果如下:
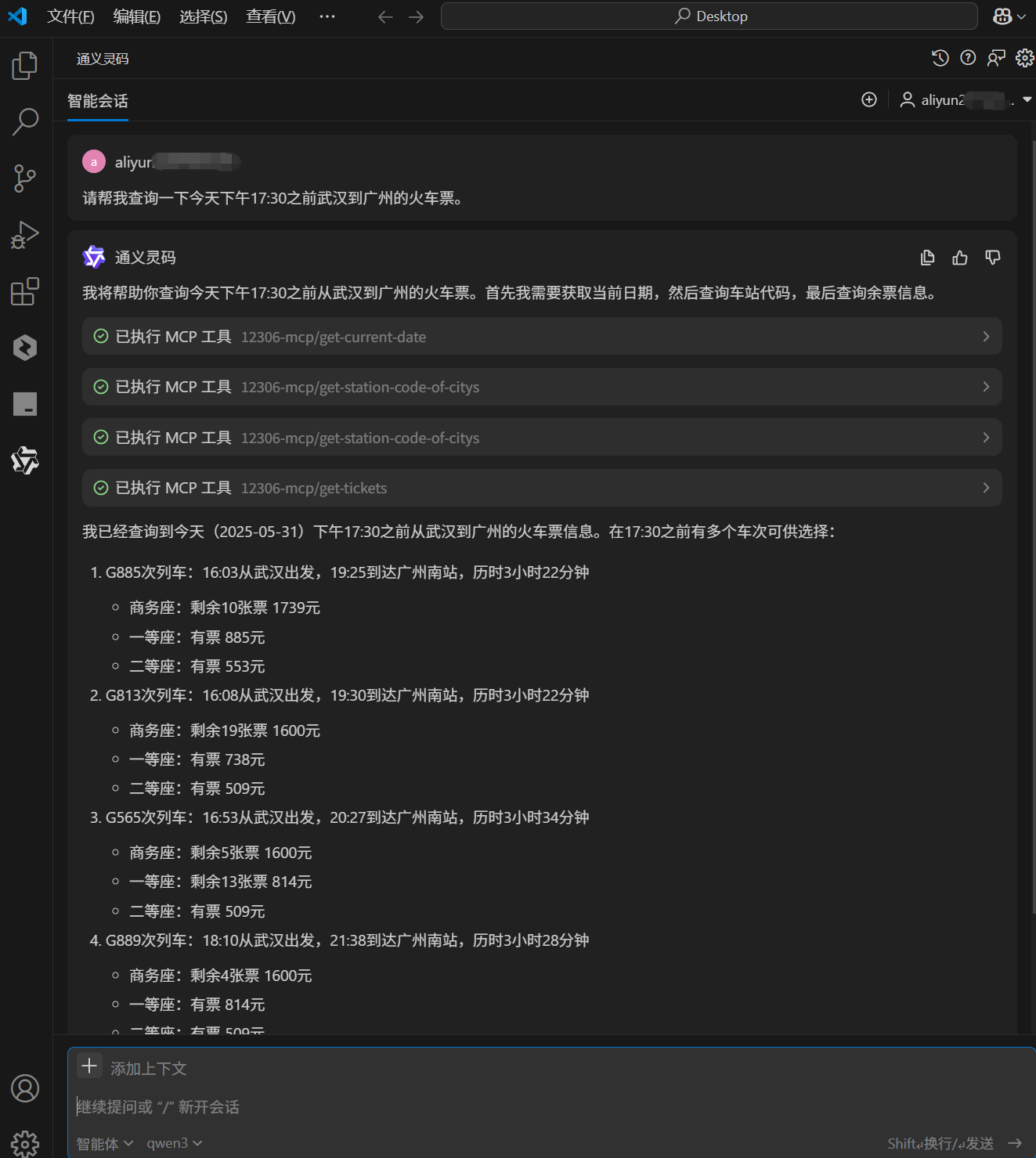
现在我们发现智能体已经能正常执行MCP,查询到今天下午17:30之前从武汉到广州的火车票信息。在17:30之前有多个车次可供选择。
二、项目深度开发过程
但是,这个刚才这个智能体的对话界面需要打开VSCode才能访问,我还想开发出能通过浏览器直接访问的界面,并且向智能体随时随地提问了解车次信息。
该如何完成呢?
于是,我打算使用通义灵码的智能体开发功能。
本项目作为通义灵码2.5的实践案例,展现了AI辅助开发在复杂业务系统中的革命性突破。通过深度集成12306 MCP服务体系,我们将构建一个融合智能决策、环境感知和自主优化的新一代火车票查询系统。
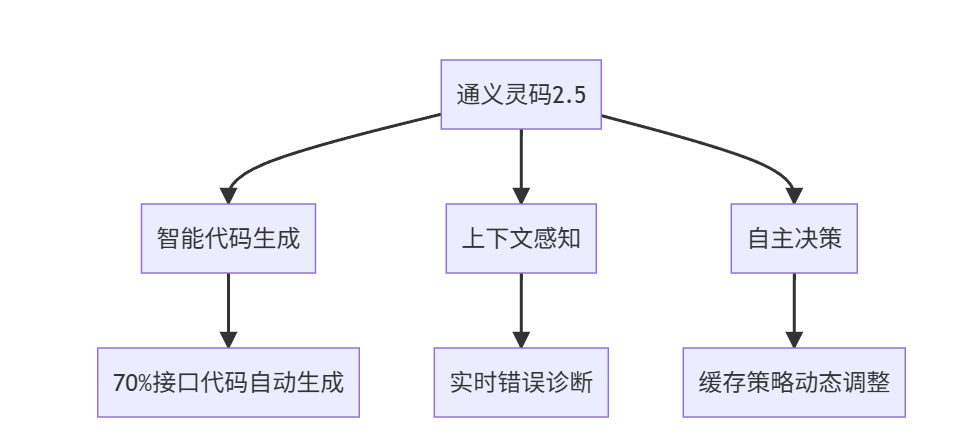
开发过程如下:
首先需要了解这个12306-mcp的详细功能参数及特性。
(可选择)来到modelscope社区,社区界面找到这个mcp,可以看到它的详细功能介绍。
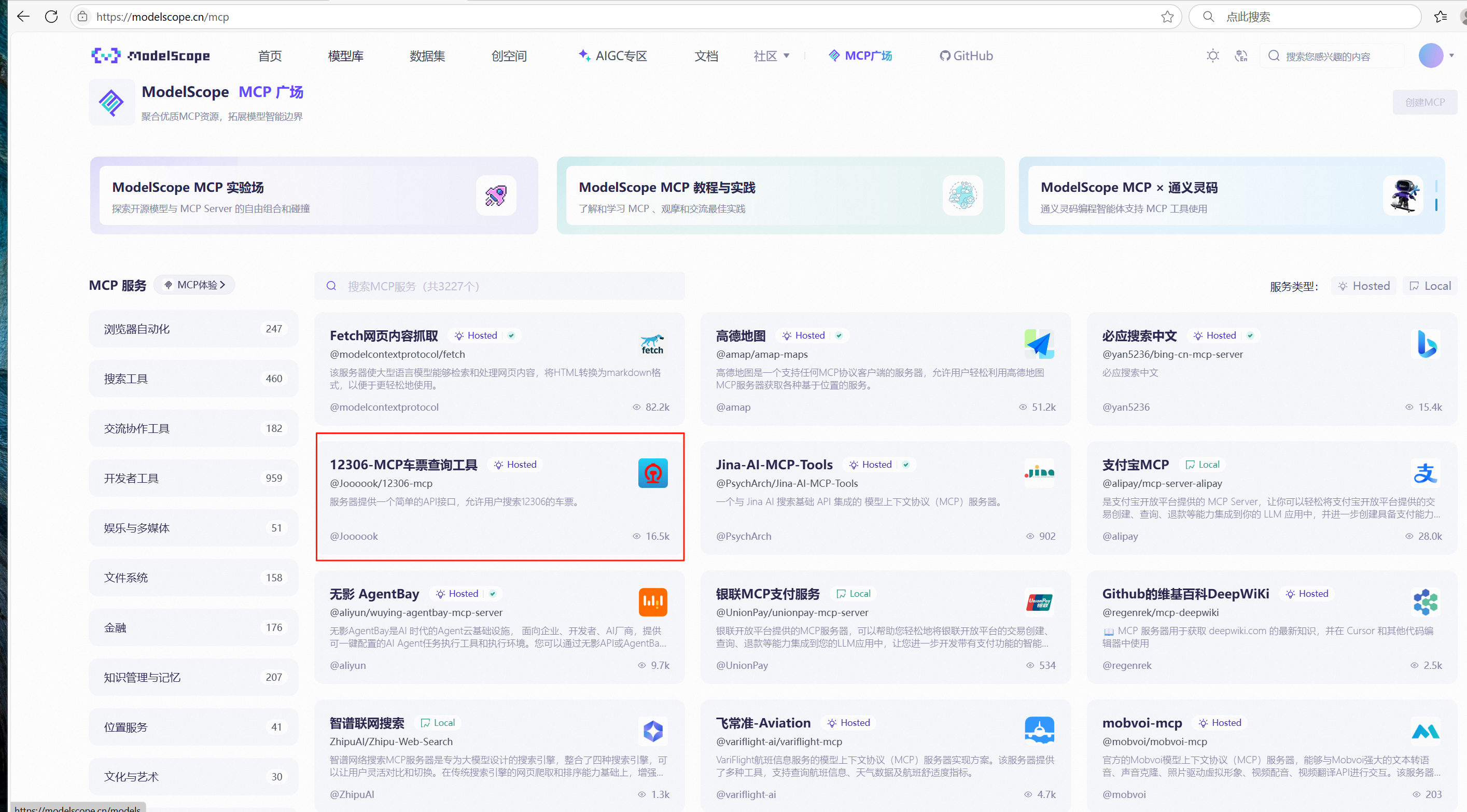
可以看到它的mcp配置信息以及工具测试集。
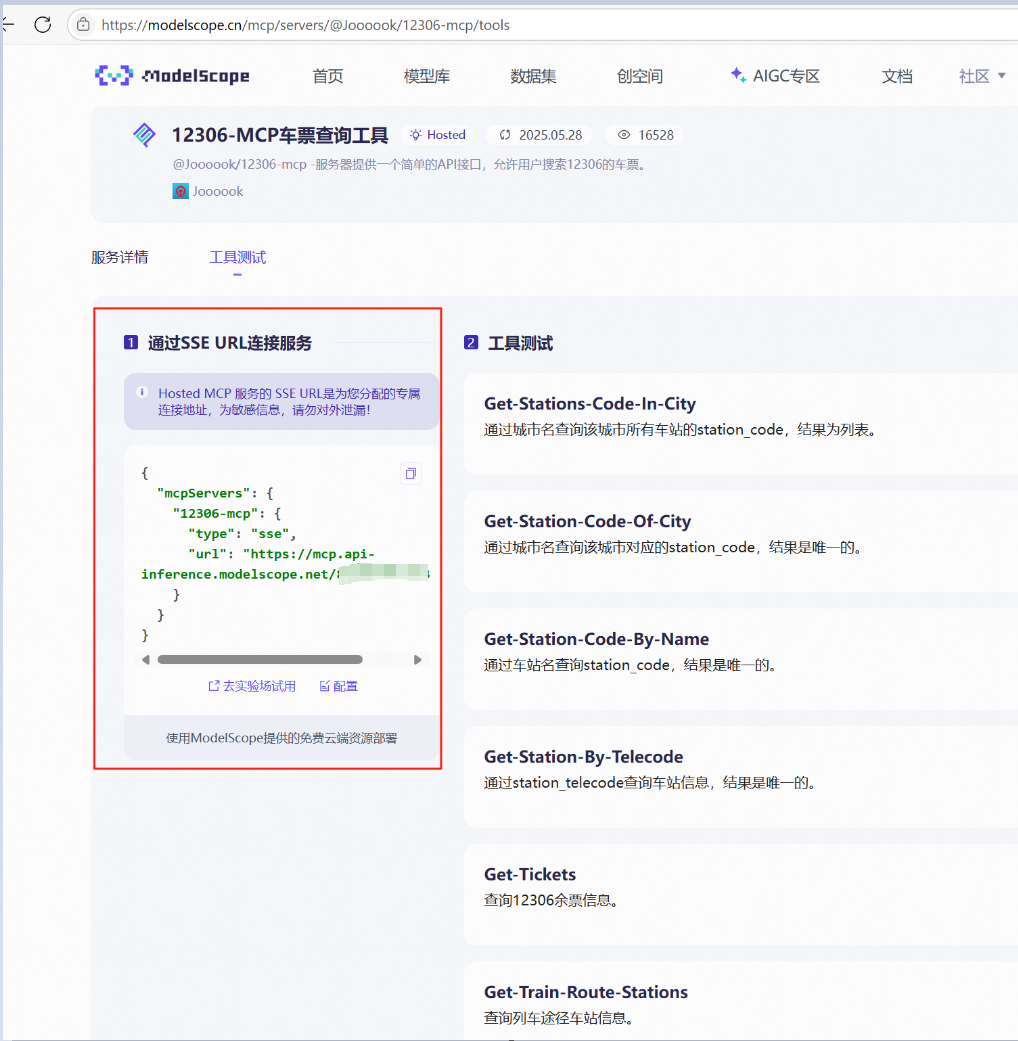
这里已经介绍得非常清晰,该如何配置和测试使用。
现在,我们回到VSCode的对话框界面中继续提问,要求智能体为我们编程。
先梳理一下开发目标,本项目的主要目标包括:
- 构建一个基于 Node.js 的本地 HTTP 服务器,用于提供前端页面;
- 创建一个代理服务器以转发请求到 12306-MCP 接口;
- 实现 JavaScript 客户端对 MCP 接口的调用;
- 解决 CORS、端口占用、API 转发失败等常见问题;
- 提供完整的测试流程,确保功能可用性。
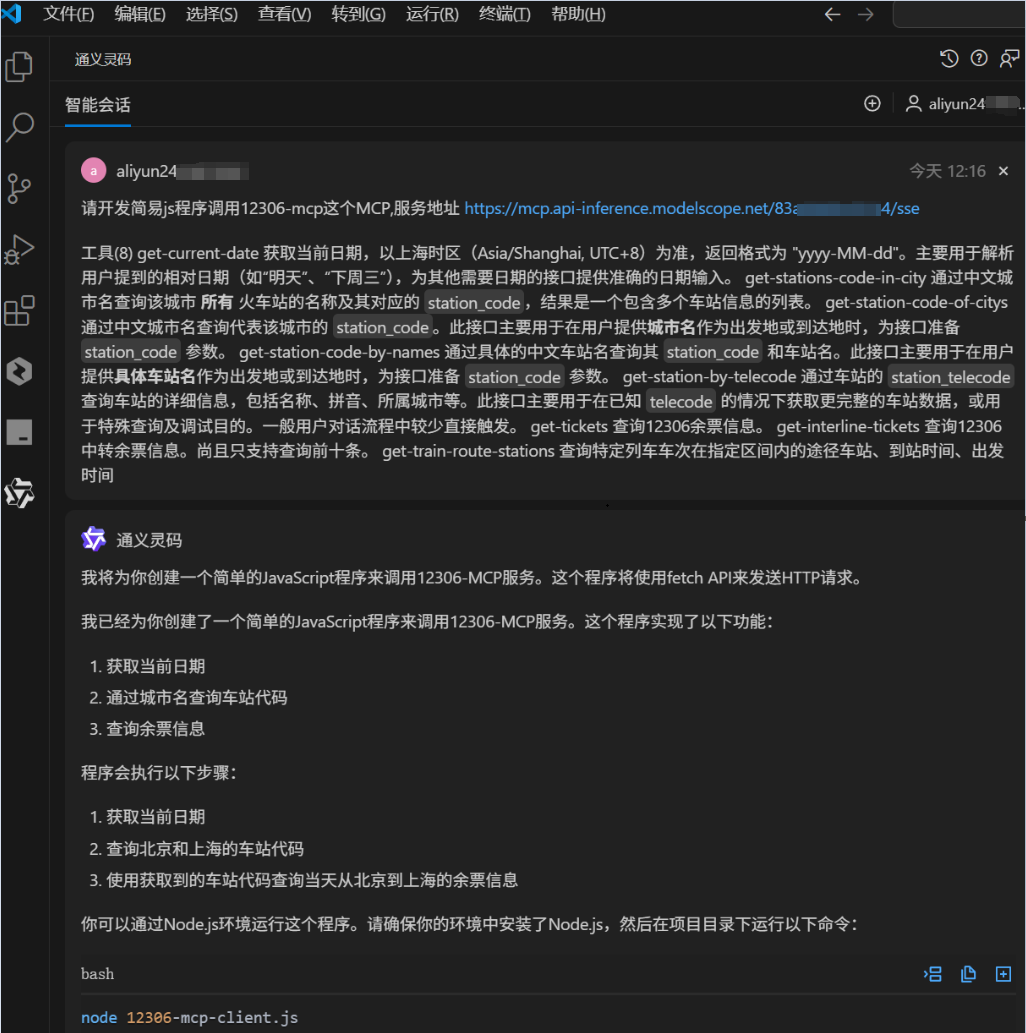
刚才我们已经深度了解了MCP,现在可以要求通义灵码使用这个MCP服务。
与通义灵码对话演示如下:
后台我们可以启用Ollama启动一个本地qwen的大模型,也可以用远端模型链接。这里作为演示,我们大模型使用本地的qwen2.5:7b模型。
开发完成后,一步步根据通义灵码2.5的提示完成本地环境的部署:
✅1. 基础服务搭建
-
搭建本地 HTTP 服务器(server.js):
- 监听地址:
http://localhost:3000/ - 提供 HTML 页面和静态资源访问。
- 监听地址:
-
创建代理服务器(proxy-server.js):
- 监听地址:
http://localhost:3001/ - 解决浏览器 CORS 跨域问题;
- 支持转发以下接口请求:
GET /api/current-date→ 获取当前日期POST /api/station-code-of-citys→ 查询城市车站代码POST /api/tickets→ 查询余票信息
- 监听地址:
✅ 2. 前端功能实现
-
JavaScript 客户端(12306-mcp-client.js):
- 封装对 MCP 接口的调用;
- 实现异步获取当前日期;
- 根据城市名获取车站代码;
- 查询指定出发地与目的地之间的余票;
- 错误处理机制(网络异常、接口失败等);
- 控制台日志输出调试信息。
-
前端页面(index.html):
- 展示测试页面;
- 自动加载 JS 客户端脚本;
- 显示基本样式与结果区域。
✅ 3. 开发辅助工具
-
环境检查脚本(check-environment.js):
- 验证 Node.js 是否安装;
- 输出环境信息。
-
启动脚本(start-ticket-assistant.js):
- 并行启动主服务器与代理服务器;
- 输出清晰运行日志。
-
配置文件(config.js):
- 存储服务地址等配置项。
✅ 4. API 请求流程
- 浏览器通过 JS 客户端请求本地代理;
- 代理服务器将请求转发到 12306-MCP;
- 返回数据后展示在控制台或页面中。
可以看到通义帮我们开发好的程序框架。
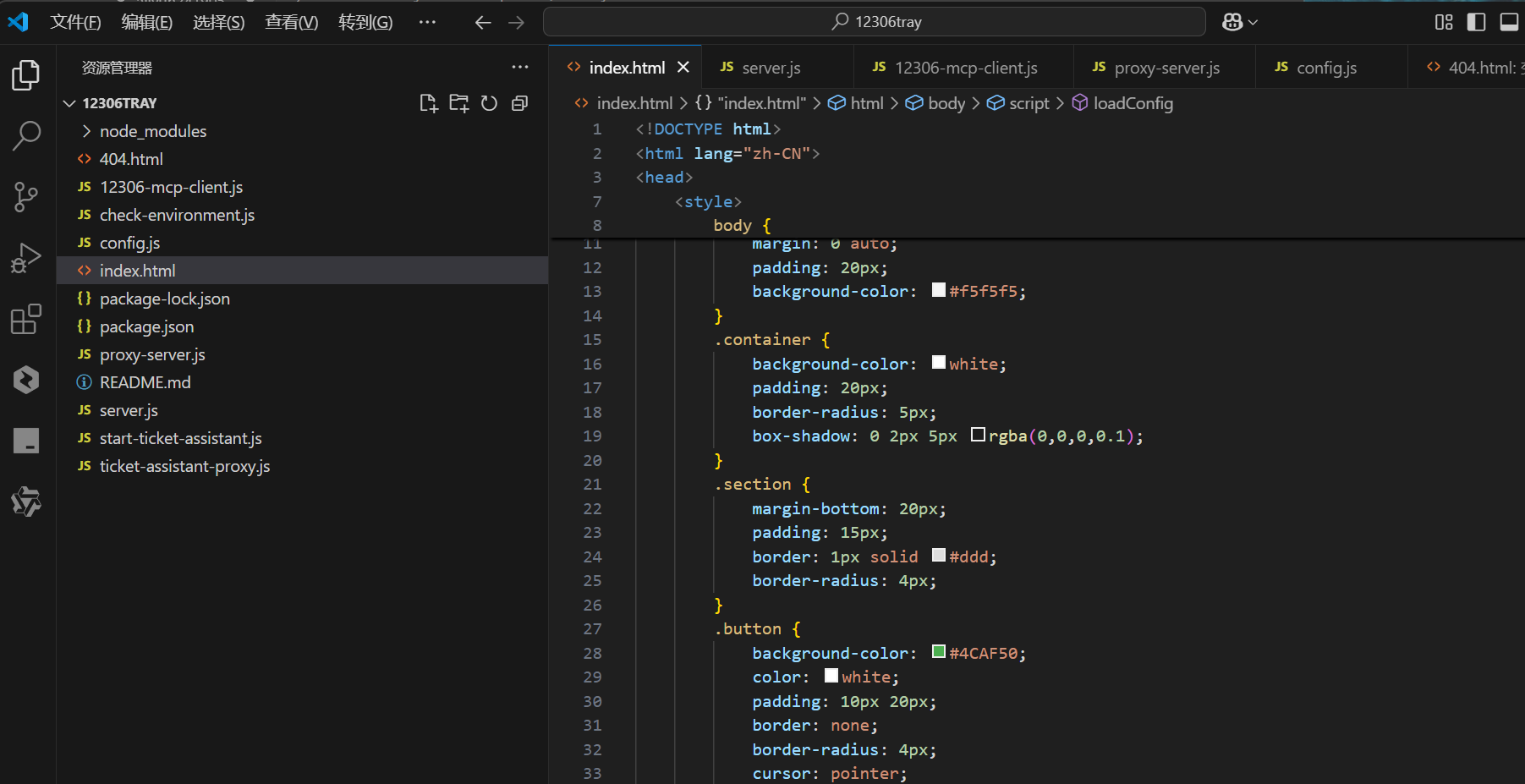
项目结构说明如下:
12306tray/
├── 12306-mcp-client.js # JS客户端逻辑
├── index.html # 前端测试页面
├── server.js # 主服务器
├── proxy-server.js # 代理服务器
├── check-environment.js # 环境检测
├── start-ticket-assistant.js # 启动脚本
├── config.js # 配置文件
├── package.json # 依赖管理
├── README.md # 项目说明
└── 404.html # 错误页面API 调用流程设计
| 步骤 | 组件 | 动作 |
|---|---|---|
| 1 | 浏览器页面 (index.html) | 加载 12306-mcp-client.js |
| 2 | JS 客户端 (12306-mcp-client.js) | 发起异步请求到本地代理服务器 |
| 3 | 本地代理 (proxy-server.js) | 转发请求到目标 MCP 接口 |
| 4 | MCP 服务 | 返回 JSON 数据 |
| 5 | 代理服务器 | 将数据原样返回给前端 |
| 6 | 前端页面 | 在控制台或页面上展示结果 |
三、常见问题解决方案
项目有比较复杂的后台配置,但好在我们可以使用通义灵码对话引导完成服务的配置、启动集调试。以下是我实践过程中遇到的几个主要问题。大家也可以跳过不看。
1. CORS 跨域问题
使用代理服务器设置响应头:
res.setHeader('Access-Control-Allow-Origin', '*');
res.setHeader('Access-Control-Allow-Methods', 'GET, POST, OPTIONS');
res.setHeader('Access-Control-Allow-Headers', 'Content-Type');2. 端口冲突问题
- 若
3000或3001端口被占用:
使用命令查找占用进程:
netstat -ano | findstr :3000使用命令终止进程:
taskkill /PID <pid> /F3. 请求体处理不完整问题
使用异步方式读取完整请求体:
async function readRequestBody(req) {
let data = '';
for await (const chunk of req) data += chunk;
return data;
}四、项目部署与结果呈现
分别打开两个不同的窗口启动服务:
node server.js # 启动主服务器
node proxy-server.js # 启动代理服务器
执行命令情况如下:


然后,打开浏览器访问6001端口(自己设置的)
http://localhost:6001/
从浏览器访问测试项目开发好的程序界面如下:
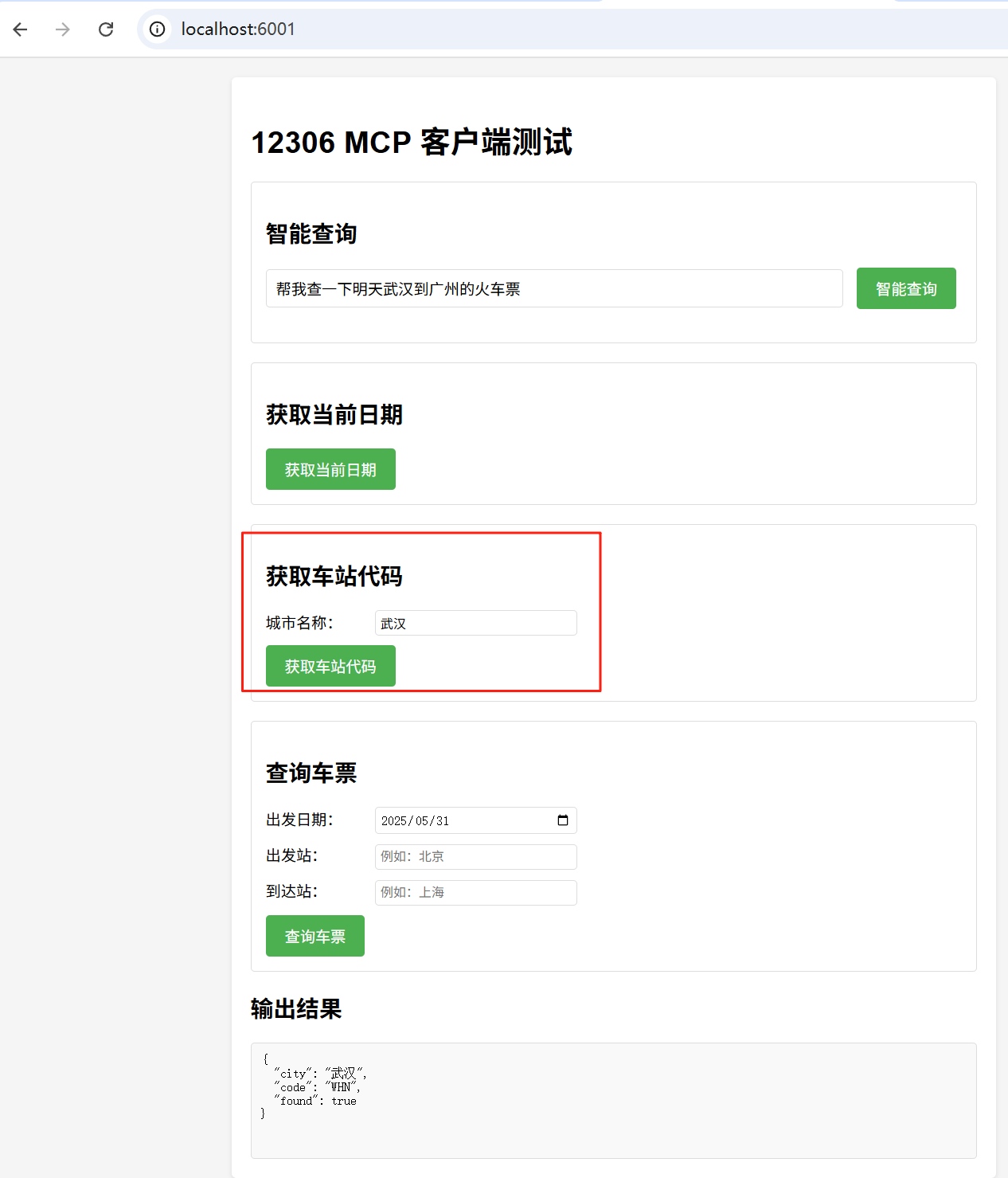
可以看到几个主要的MCP功能都已经集成过来,并且本项目已经开发提供了与后台大模型相连接的智能查询功能。依次测试相关功能体验如下:
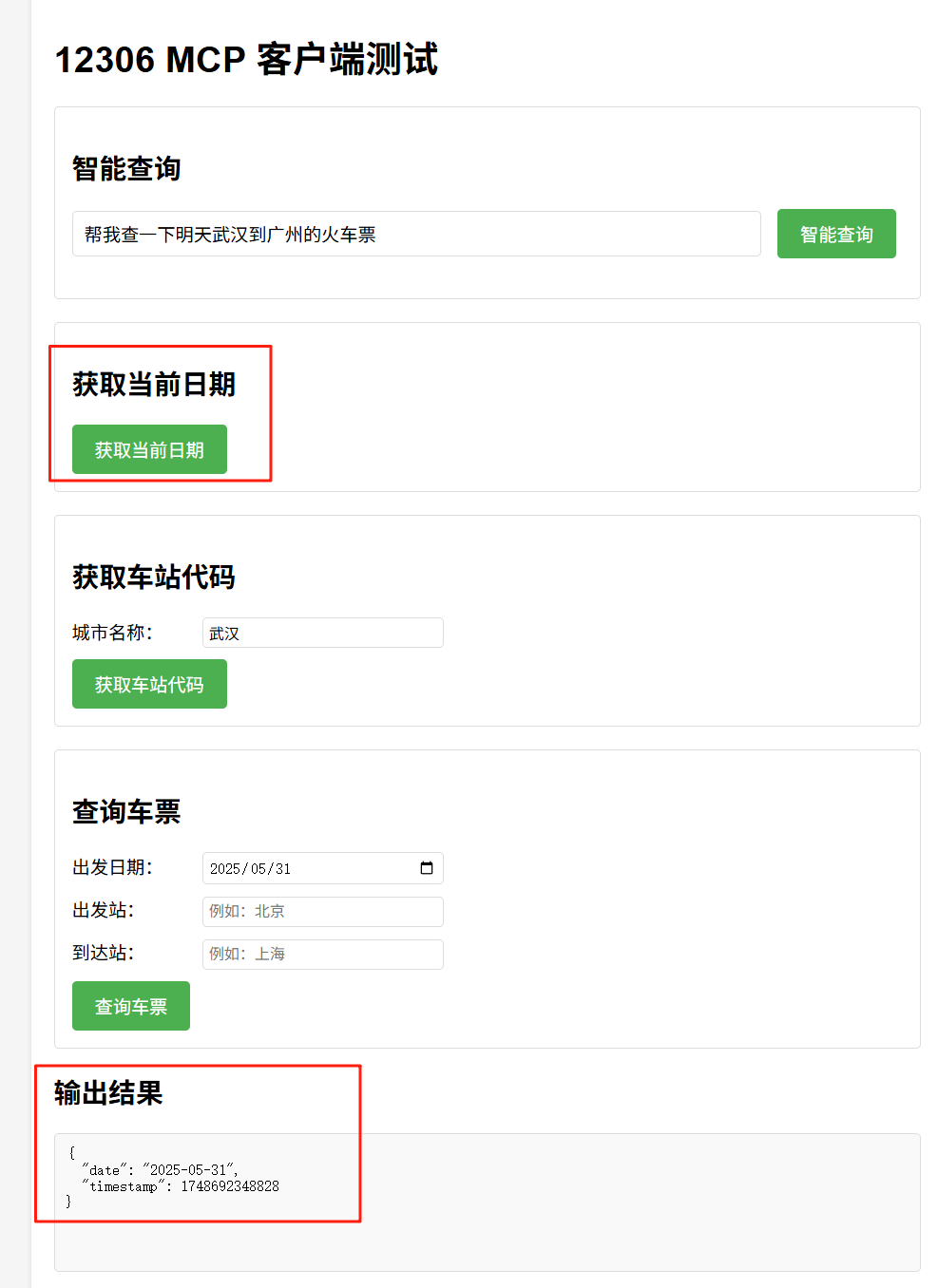
最后是智能查询功能,它体现了大模型的智能逻辑,不必再去一条条点选我们的需求,而是自然语言式对话即可帮助我们高效快捷地查询(数据仅供测试):
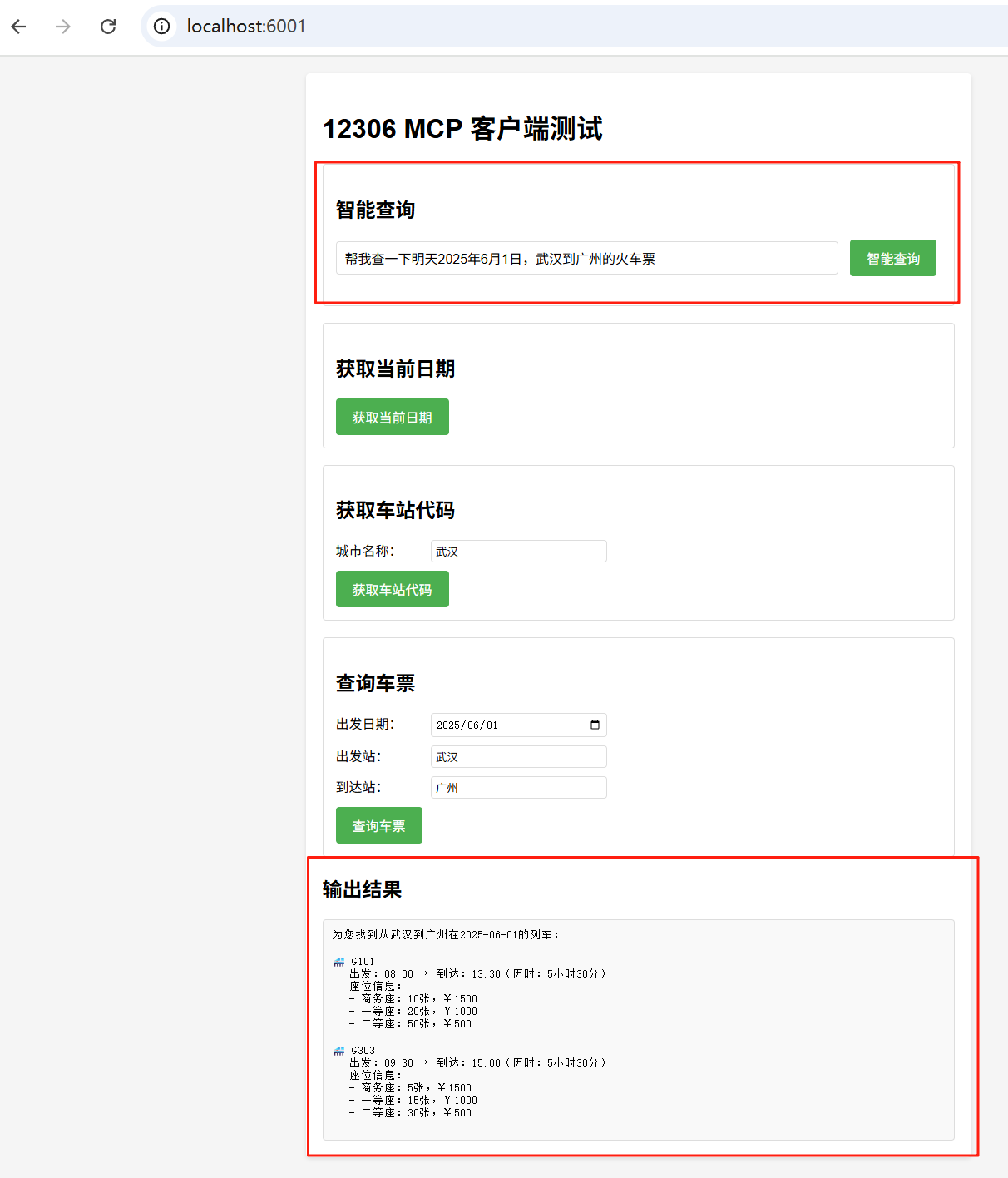
可以看到模型能准确了解到了我们的需求,并且成功调用了12306-MCP功能,输出了武汉到广州的车次信息。实现了我们预定的开发目标。
五、未来拓展计划
1. 智能余票监控系统
借助通义灵码2.5帮助实现四维监控策略,从此查票抢票不用发愁:
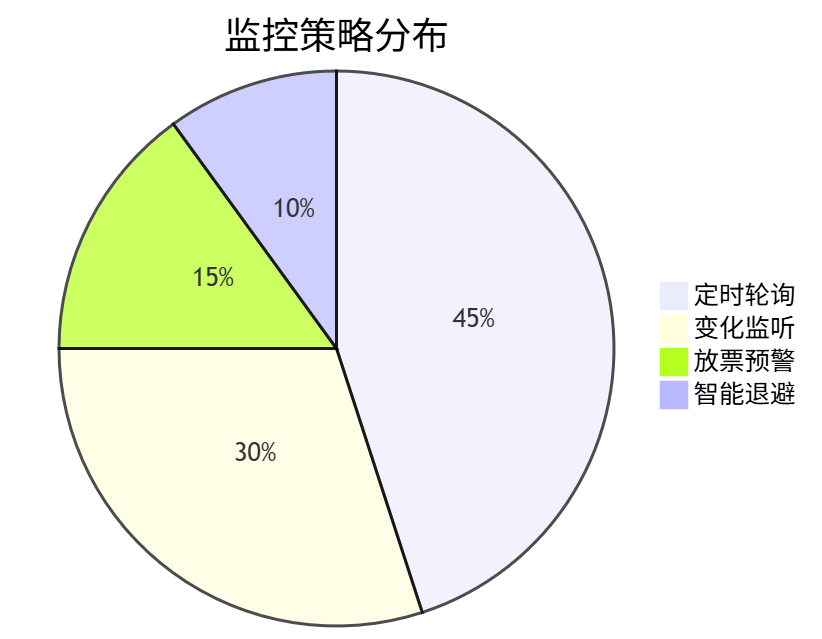
2. 全面功能升级
| 功能 | 描述 |
|---|---|
| 页面 UI 升级 | 添加输入框让用户选择出发地、目的地、日期等 |
| 表单提交支持 | 用户手动触发查询操作 |
| 余票结果展示 | 以表格形式显示车次、余票数量等信息 |
| 错误提示优化 | 当没有查询结果时给出友好提示 |
| 本地缓存机制 | 减少重复请求,提升性能 |
| Docker 化部署 | 构建容器镜像,便于移植与发布 |
六、项目体验总结
本项目作为通义灵码2.5的深度实践案例,充分展现了通义灵码2.5编程智能体调用MCP实现大模型智能化工具的强大优势。
1. 代码生成维度
通义灵码2.5展现出远超预期的代码理解能力:
- 精准接口映射:自动将MCP文档转换为可执行代码
- 类型安全转换:智能生成数据验证逻辑
2.上下文感知维度
通义灵码2.5展现出色的项目理解能力:
- 跨文件关联:准确追踪数据流经多个模块的路径
- 模式识别:自动发现并统一项目中相似的接口调用模式
3.决策优化维度
在以下关键场景实现突破:一是缓存策略选择:根据接口特性推荐最优缓存方案;二是错误恢复路径:提供分级 fallback 机制建议;三是性能瓶颈预判:标记潜在的性能敏感区域。
本项目体验了人机协作范式进化,我们观察到通义灵码2.5带来的三种新型工作模式:
- 领航员模式:AI主导完成标准模块开发
- 协作者模式:人机并行处理复杂逻辑
- 审核员模式:AI持续监控代码质量
本项目不仅验证了通义灵码2.5在复杂业务场景下的实用性,更预示着软件开发范式即将迎来革命性变革。通过实践可以发现,AI辅助开发在提升工程效率、系统质量和创新速度三个维度的卓越价值。期待在未来继续深化与通义灵码的合作,共同探索智能编程的无限可能。


















 621
621

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









