




 本文深入解析InnoDB在OLAP和OLTP场景下的应用与优化策略,涵盖表设计、索引及脚本优化,旨在提高数据库性能。
本文深入解析InnoDB在OLAP和OLTP场景下的应用与优化策略,涵盖表设计、索引及脚本优化,旨在提高数据库性能。
应用
以上都是在原理层面对innodb进行了分析,基于此我们才能在日常工作中知道如何高效的使用innodb,而且知其然并知其所以然。
数据库的应用分为两类:OLAP和OLTP。
OLAP
联机分析处理(Online Analytical Processing),也叫DSS(Decision Support System)决策支持系统,也就是数据仓库。作业内容是对某些历史数据进行分析,来支持管理决策。OLAP强调的是数据分析,依赖的是磁盘io、数据分区、网络带宽等。
在OLAP系统中脚本的执行速度并不是考核标准,因为一条脚本往往会执行非常长的时间,并且读取的数据也非常多,动辄几百万上千万的数据量,这里考核的指标是系统吞吐量。系统吞吐量取决前面分析过的磁盘io和网络带宽,因为缓存在这里无法发挥作用。
整体流程
整个过程:原始业务数据 -> 数据清洗转换 -> 操作性数据库 -> 数据仓库 -> 数据集市,流程如下:
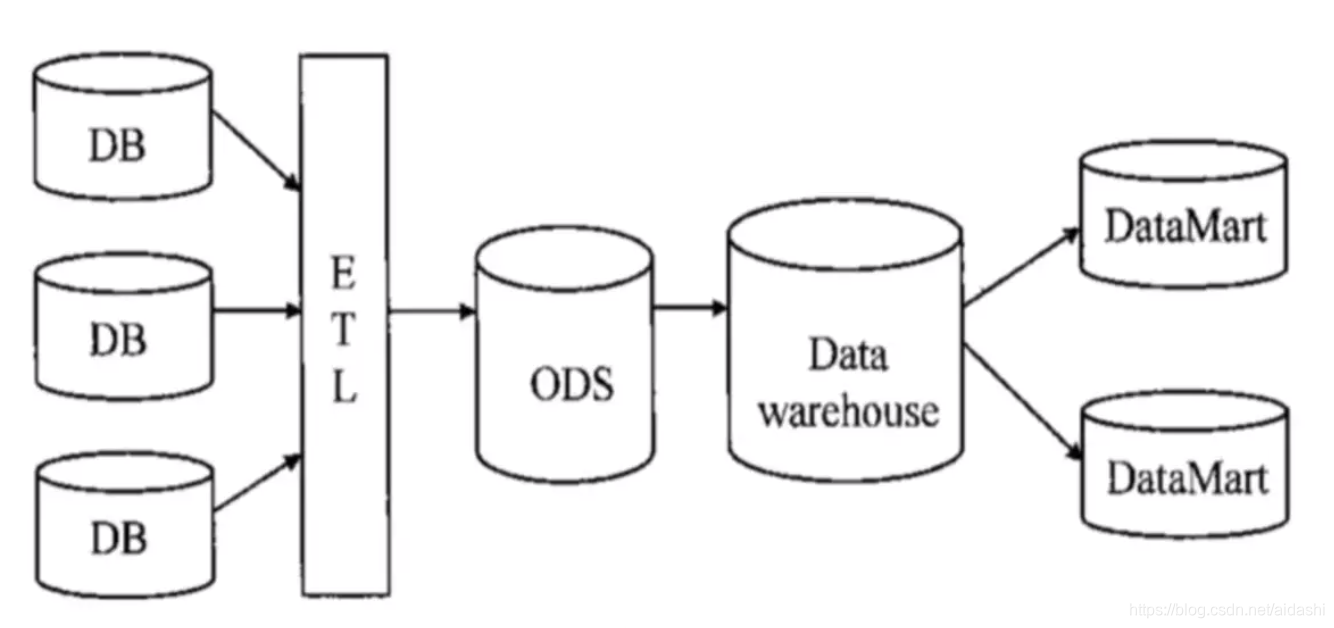
上图的名词解释:
-
DB : 原始业务数据
-
ETL : Extraction-Transformation-Loading,抽取转换和加载,就是数据清洗的过程
-
ODS : Operational Data Store 操作性数据库,与原始数据最接近的一层,在结构和数据上与原始数据保持一致,基本是保存了一份原始数据冗余,为的是在数据仓库和业务库之间加一层隔离,避免数据仓库直接访问业务库从而对实时在线业务产生影响。同时,这一层可以承担数据仓库完成不了的功能,比如可以提供业务明细报表的查询和导出,这种报表的查询和导出不应该由实时系统的主库承担,因为innodb不擅长做这类事务,并且会污染mysql的LRU缓存队列,对在线用户产生很大影响
-
Data warehouse : 数据仓库,面向主题的(Subject Oriented)、集成的(Integrate)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合。
-
DataMart : 数据集市,专门为单一业务领域建立的数据仓库,结构性强、针对性强、扩展好,只关心自己需要的数据
架构
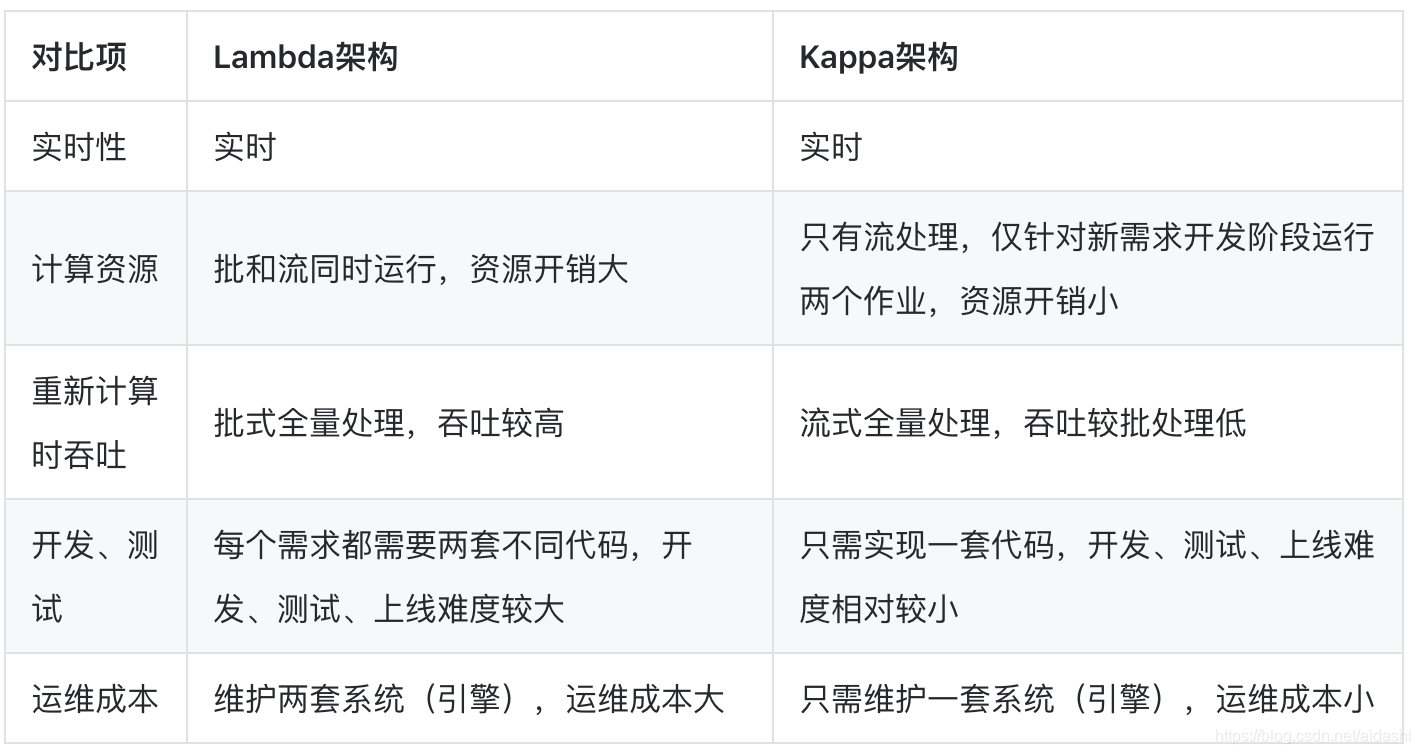
常用的两种架构,Lambda架构与Kappa架构,不做详细解释。
优化
对于OLAP应用,在内存上做优化的空间很小(像myisam存储引擎只缓存索引页不缓存数据页),一般不做更新操作,但是它需要做一些复杂的查询,需要执行一些比较、排序、连接等耗CPU的操作,也就是CPU密集型操作。所以优化的方向就是提升数据检索、聚合效率,那么可选的就是提升CPU速度和提升磁盘IO,另外在算法上还有分区、并行、位图索引等。
OLTP
联机事务处理(Online Transaction Processing),是传统关系型数据库的主要应用场景,表示事务性非常高,一般是高可用的实时在线系统,有以下特点:
-
用户操作并发量大
-
事务处理时间较短
-
查询语句较为简单,复杂查询较少
-
操作数据量较少,一般是一条或者是几十条
innodb是mysql在OLTP事务下最常用的存储引擎。
优化
innodb是一款非常优秀的面向OLTP的储存引擎,不过在日常工作中dba总是能给业务团队提出非常多的慢sql,问题不是出在innodb的设计上,而是出在大家对innodb的使用上。通过上文对innodb的原理有了一定的了解,下面着重讲讲innodb应该如何使用。
表设计优化
-
设置自增id,并且不要改动
-
对于枚举字段优先使用enum或者set类型,可以极大的降低存储空间
-
字段设置默认值,避免使用NULL ,使用NOT NULL DEFAULT 代替,因为NULL很难查询优化
-
金额类型以分为单位存储,int类型,避免小数,代码中业务计算、前后端交互也以分为单位,只有给用户展示时候才由前端转化为元
-
避免使用text类型,定长字段用char,不定长字段用varchar
-
表中字段越少越好,字段长度越短越好(数据页中能存放更多的行),如果字段过多需要考虑垂直拆分
索引优化
-
一张表中的索引尽量不要超过5个
-
取值散列的、无限的列上适合建立索引,参考cardinality。相反的,取值聚合的、有限的列上的索引需要删除
-
最左匹配原则,联合索引最左边的列一定是能过滤数据最多的列,并且依次降序排列
-
索引列不要参与计算
-
尽量扩展索引列,避免新建索引,比如将单列索引扩展为联合索引
-
避免like %xx导致索引失效,可以使用全文索引代替,或者冗余该列的逆序,建立索引然后转为like xx%
-
根据业务场景来考虑索引覆盖,根据order by 语句考虑利用联合索引第二列的有序性
脚本优化
-
复杂查询转换为多个简单查询,将大事务转化为简单事务
-
避免使用 != 和 <>
-
select * 转换为 select 列名
-
将在同列的or查询转换为in查询,例如
select xx from xxx where a = '1' or a = '2'可以用select xx from xxx where a in ('1','2')代替 -
将不同列的or查询转换为union all查询,例如
select xx from xxx where a = '1' or b = '1'可以使用select xx from xxx where a = '1' union all select xx from xxx where b = '1'来代替,因为在这里or查询无法走索引
大表优化
-
限定数据范围,所有查询必须限定一个合适的范围
-
读写分离,主库写,从库读
-
垂直拆分
-
优点:列数变下,简化表结构
-
缺点:冗余数据,需要连接操作,耗费cpu。无法解决单表数据量大的问题
-
-
水平拆分,拆分后的表需要部署在不同的机器上,防止表之间io竞争,增大了公司成本
-
数据归档,冷热数据分离
本文不足
本文只在存储和索引的角度阐述了innodb,目的是能让大家在使用层面对innodb有一定了解,进而在日常工作能更高效的使用innodb。其实innodb其他模块还有线程架构、缓存策略、锁原理、事务实现、日志体系等,不过日常业务研发人员离这些模块较远,但是如果业余学习了解后,对于开阔技术视野、拓展处理问题思路等大有裨益。
业余时间做的innodb的脑图总结
本文部分图片来自网络,侵权必删!若有不恰当之处,还望指教,谢谢


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









