




一文读懂 DeepSearcher:架构、原理与应用全解析。
微信搜索关注《AI科技论谈》

近期,OpenAI 的深度研究成果引发 AI 领域广泛关注,不少类似工具相继推出,如 Perplexity Deep Research、Hugging Face 的 Open DeepResearch 等。这些工具虽然架构和方法有差异,但都想通过反复研究网页或内部文档,输出一份详实、有条理的报告。而且,这些工具的底层智能体都能自动思考中间步骤该怎么做。
今天给大家介绍的是 Zilliz 的开源项目 DeepSearcher。DeepSearcher 融入查询路由、条件执行流等创新概念,支持网页爬取,以 Python 库和命令行工具呈现,功能丰富,能处理多源文档,还可配置嵌入模型和向量数据库。尽管它还不够复杂,但在智能体增强检索生成(RAG)技术方面表现亮眼,推动了人工智能应用发展。
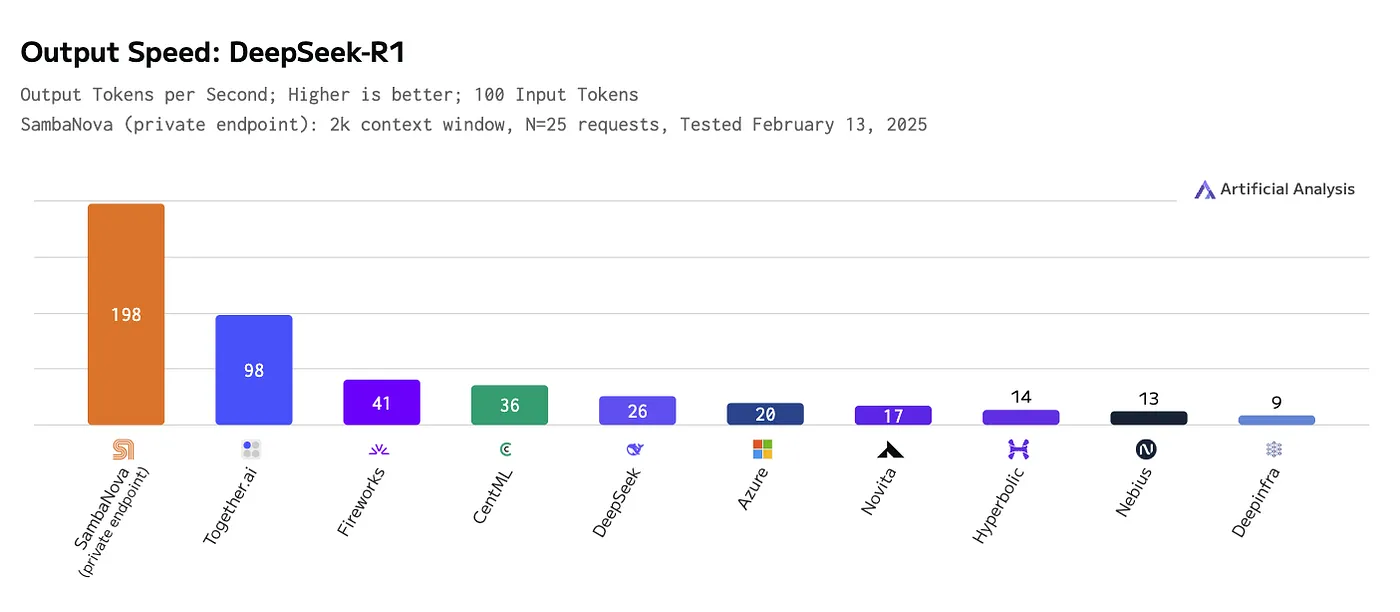
推理模型依赖 “推理扩展” 提升输出质量,频繁调用大语言模型导致推理带宽成为瓶颈。我们采用 SambaNova 定制硬件上的 DeepSeek - R1 推理模型,其输出速度比对手快一倍(见图示)。
SambaNova Cloud 为 Llama 3.x、Qwen2.5 和 QwQ 等开源模型提供推理服务,基于 RDU 定制芯片运行,该芯片专为高效推理生成式 AI 模型设计,能降本增效,更多详情可前往官网查看(https://sambanova.ai/technology/sn40l-rdu-ai-chip)。
1 DeepSearcher架构
DeepSearcher 架构将研究流程分为定义/细化问题、研究、分析、综合四步,且步骤间相互重叠,协同增效。下文会逐步介绍每个步骤,并重点说明DeepSearcher的改进之处。
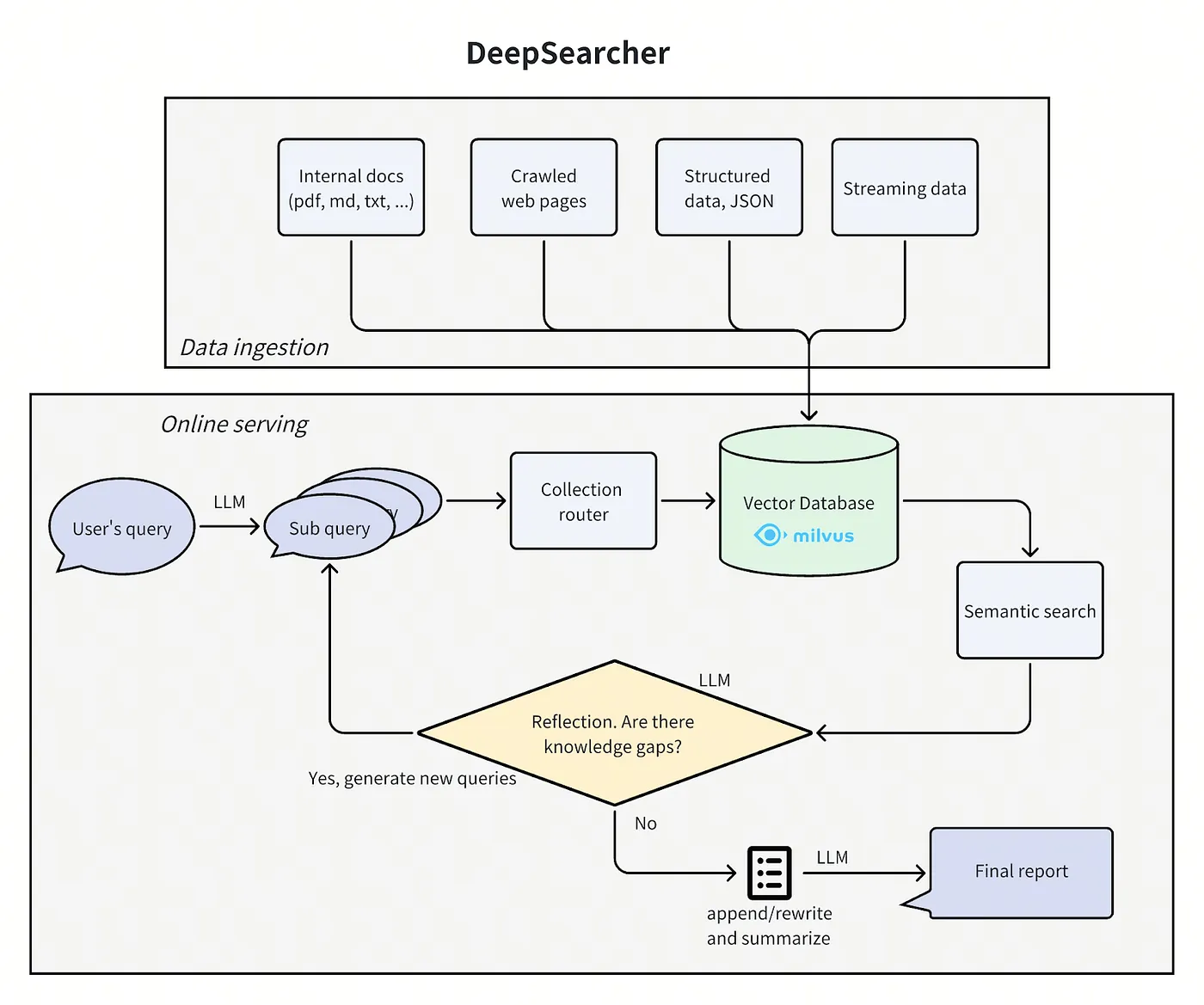
1.1 定义和细化问题:深度挖掘查询核心
以“《辛普森一家》随时间发生了哪些变化?”为例,DeepSearcher会将其拆解为多个子查询:
-
从首播到现在,其文化影响和社会意义是如何演变的?
-
不同季之间,在角色发展、幽默风格和叙事方式上发生了哪些变化?
-
动画风格和制作技术是如何随时间变化的?
-
在播出期间,受众群体、观众反响和收视率发生了哪些变化?
DeepSearcher的特别之处在于,研究和细化问题的界限不固定。初始分解后,研究过程会按需对问题再细化,灵活调整研究方向,精准挖掘信息,为后续工作筑牢根基。
1.2 研究和分析
将查询分解为子查询后,智能体的研究部分就开始了。大致来说,这部分包含四个步骤:路由、搜索、反思和条件重复。
路由
我们的数据库包含来自不同来源的多个表或集合。如果能将语义搜索限制在与当前查询相关的来源上
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









