






1.首先导入库,读取文件并观察数据的shape
2.分别查看训练集和测试集的前五行数据简单观察一下即可

2.查看训练集和测试集的数据缺失情况,可以看到训练集和测试集的“bodyType”、“fuelType”、“gearbox”存在缺失


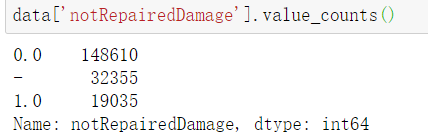
4.查看各特征的取值范围,检查有无异常值。可以发现“notRepairedDamage”值存在"-",可判断为其为缺失的另一种形式,故将其替换为nan,并在后续的缺失值填充时处理该变量
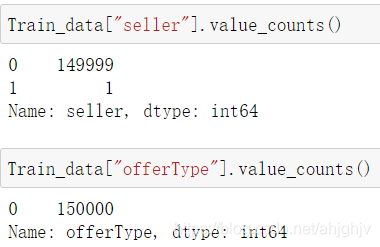
5.可以发现“seller”“offerType”两类别分类严重倾斜,可近似于只有一种类别,对预测值基本没有影响,故将其删去
6.价格分布不平衡,存在个别极大的值与均值差距较大,故将价格做对数变换,使其近似为正态分布
7.将nan填充为-1,快速进行特征工程完成一个基本的baseline。

















 982
982

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









