






 本文介绍了HTTP协议的基础知识,包括robot.txt的使用、常见请求与响应头信息,并概述了简单的爬虫实现步骤,如URL指定、请求发送及数据存储。
本文介绍了HTTP协议的基础知识,包括robot.txt的使用、常见请求与响应头信息,并概述了简单的爬虫实现步骤,如URL指定、请求发送及数据存储。
君子协议:robot.txt 告诉什么可以爬取什么不可以
http协议
常用请求头信息:
user-Agent :请求人的身份
-connection:请求完毕后是断开连接还是继续连接
常用响应头信息:
-content-type :服务器响应返回客户端的数据类型
https协议(证书秘钥加密):
表示安全的http协议-安全的超文本传输协议,在http传输基础上加密
加密方式:
-对称秘钥加密
-非对称秘钥加密
-证书秘钥加密
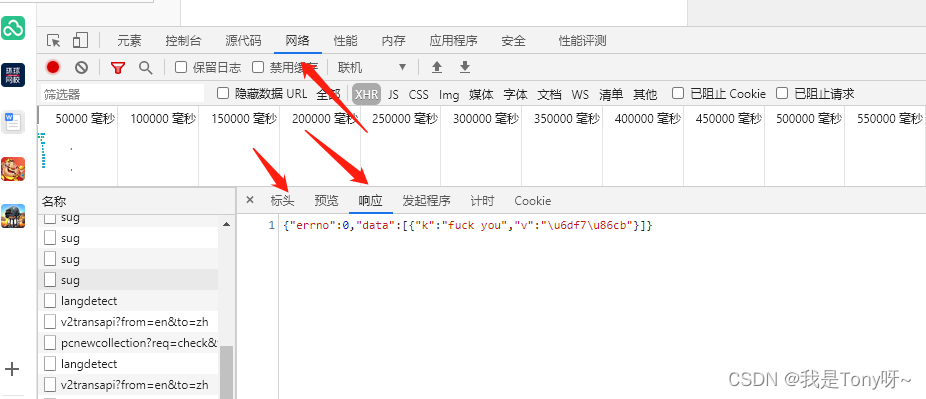
F12看网站相关响应数据
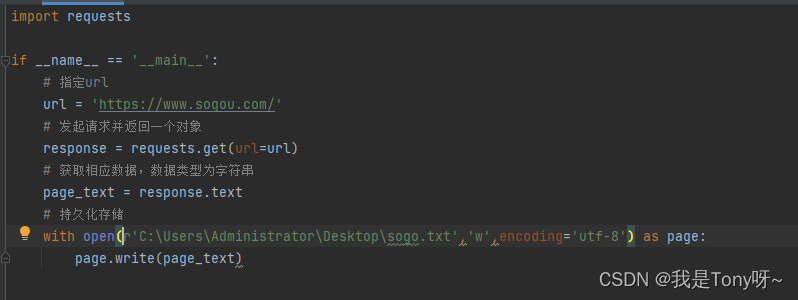
简单爬虫:指定url,发起请求,接收数据,持久化存储
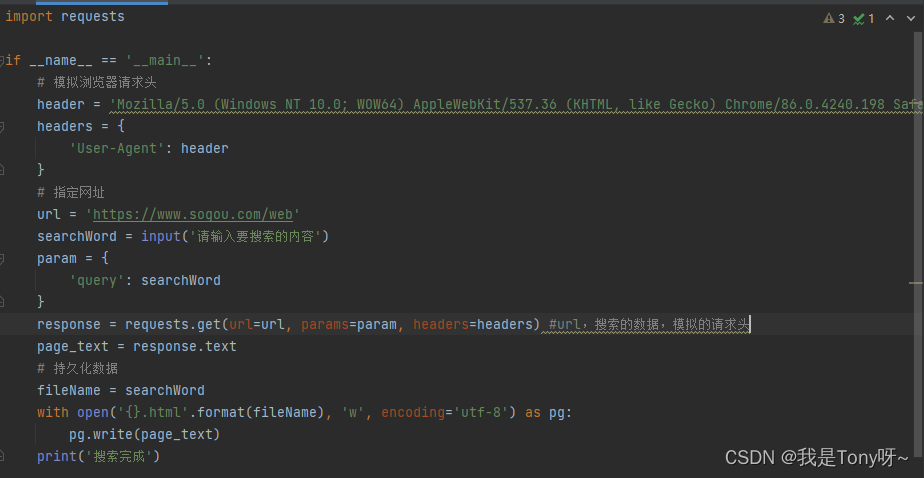
二、简单网页采集器(主要键值对要跟浏览器一样,特别是headers里面的,键和值都要跟浏览器的一样)
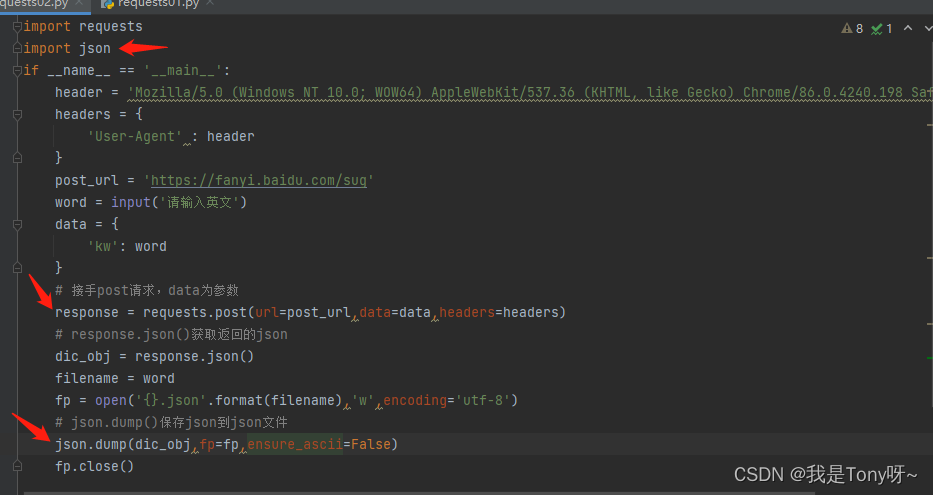
三、接收post请求,json数据
四、get请求的json数据
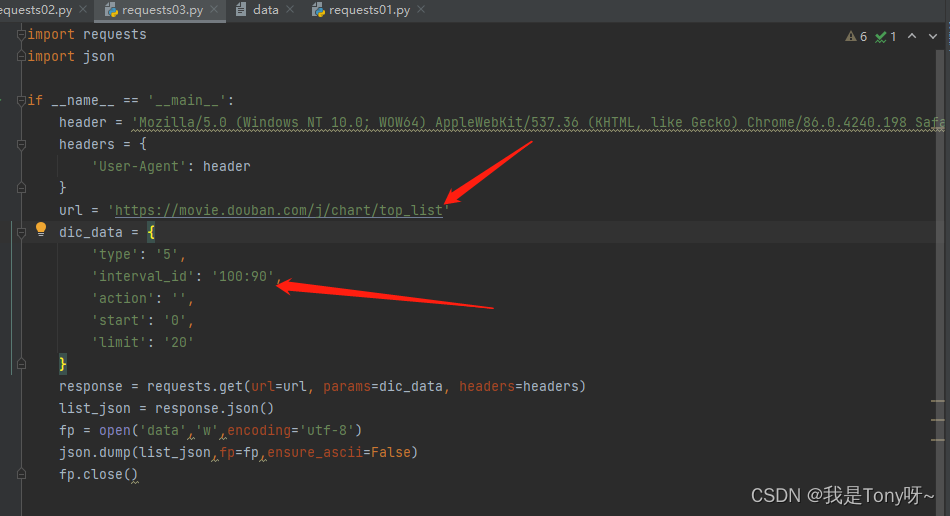
总结:基础爬虫主要以下几步
1、指定爬取的url
2、伪装成浏览器去发送请求
3、获取到请求
4、持久化数据
学会用F12来分析需要爬取页面,那些是需要传的参数,那个是url,返回是什么类型的结果



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









