




 本文介绍了一种使用Hadoop进行大规模手机流量数据统计的方法。通过MapReduce编程模型,实现了对每个手机号的上行流量、下行流量及总流量的精确统计。文章详细阐述了数据输入格式、Map和Reduce阶段的处理流程,以及自定义Bean类和驱动程序的设计。
本文介绍了一种使用Hadoop进行大规模手机流量数据统计的方法。通过MapReduce编程模型,实现了对每个手机号的上行流量、下行流量及总流量的精确统计。文章详细阐述了数据输入格式、Map和Reduce阶段的处理流程,以及自定义Bean类和驱动程序的设计。
1.需求:
- 统计每一个手机号耗费的总上行流量、下行流量、总流量
2.数据准备:
(1)输入数据格式:
时间戳、电话号码、基站的物理地址、访问网址的ip、网站域名、数据包、接包数、上行/传流量、下行/载流量、响应码
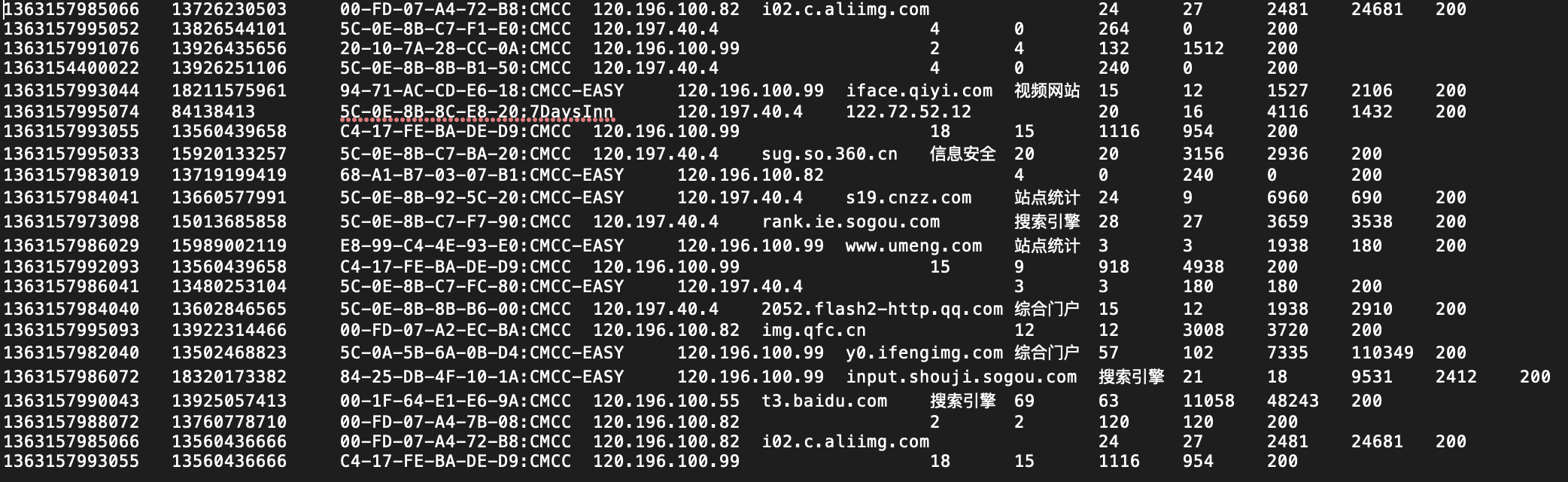
(2)最终输出的数据格式:
手机号码 上行流量 下行流量 总流量
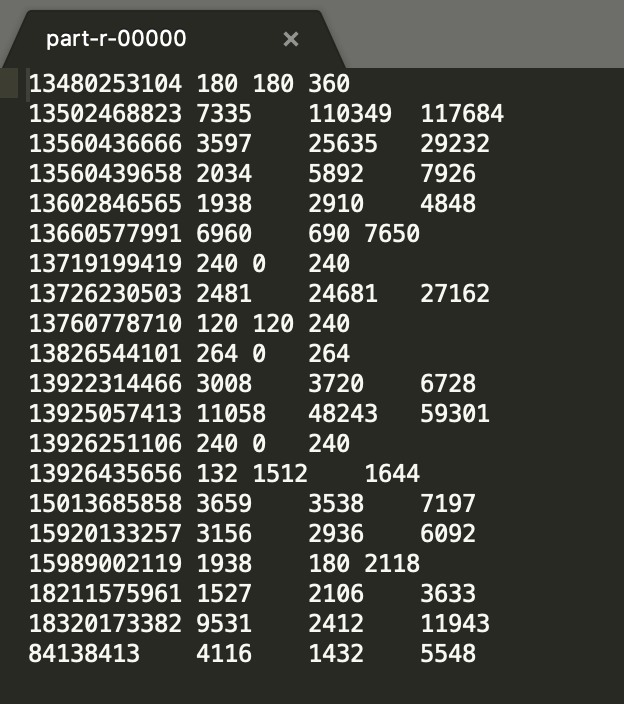
3.分析:
基本思路:
(1)Map阶段:
- (a)读取一行数据,切分字段
- (b)抽取手机号、上行流量、下行流量
- ©以手机号为key,bean对象为value输出,即context.write(手机号,bean);
(2)Reduce阶段:
- (a)累加上行流量和下行流量得到总流量。
- (b)实现自定义的bean来封装流量信息,并将bean作为map输出的key来传输
- ©MR程序在处理数据的过程中会对数据排序(map输出的kv对传输到reduce之前,会排序),排序的依据是map输出的key
所以,我们如果要实现自己需要的排序规则,则可以考虑将排序因素放到key中,让key实现接口:WritableComparable。
然后重写key的compareTo方法。
4.程序代码:
(1)编写流量统计的bean对象FlowBean
FlowBean.java
package phoneData;
import lombok.Getter;
import lombok.Setter;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
// 1 实现writable接口
@Setter
@Getter
public class FlowBean implements Writable {
//上传流量
private long upFlow;
//下载流量
private long downFlow;
//流量总和
private long sumFlow;
//必须要有,反序列化要调用空参构造器
public FlowBean() {
}
public FlowBean(long upFlow, long downFlow) {
this.upFlow = upFlow;
this.downFlow = downFlow;
this.sumFlow = upFlow + downFlow;
}
public void set(long upFlow, long downFlow){
this.upFlow = upFlow;
this.downFlow = downFlow;
this.sumFlow  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 769
769

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









