







 Redis是一个基于内存的键值对NoSQL数据库,特点是低延迟、速度快。它支持数据持久化、主从集群,并有多种客户端支持。文章介绍了Redis的基本操作,如键值对、字符串、列表、集合和有序集合等数据类型的操作命令,以及如何使用Jedis和SpringDataRedis进行Java开发中的集成和操作。
Redis是一个基于内存的键值对NoSQL数据库,特点是低延迟、速度快。它支持数据持久化、主从集群,并有多种客户端支持。文章介绍了Redis的基本操作,如键值对、字符串、列表、集合和有序集合等数据类型的操作命令,以及如何使用Jedis和SpringDataRedis进行Java开发中的集成和操作。
什么是redis
redis诞生与2009年,是一个基于内存的键值对 的NoSql数据库(非关系型数据库)
redis的特征
- 键值对型
- 单线程,每个命令必须具备原子性
- 低延迟,速度快(基于内存,IO多路复用,良好的编码)
- 支持数据的持久化
- 支持主从集群,分片集群
- 支持多语言客户端
sql和nosql的区别

redis基本操作
Redis安装完成后就自带了命令行客户端:redis-cli,使用方式如下:
redis-cli [options] [commonds]
其中常见的options有:
-h 127.0.0.1:指定要连接的redis节点的IP地址,默认是127.0.0.1-p 6379:指定要连接的redis节点的端口,默认是6379-a 123321:指定redis的访问密码
其中的commonds就是Redis的操作命令,例如:
ping:与redis服务端做心跳测试,服务端正常会返回pong
不指定commond时,会进入redis-cli的交互控制台:
127.0.0.1:6379>
指定用户名和密码(你自己的redis密码)
127.0.0.1:6379> AUTH 123321
redis的命令
官方文档:redis.io/commands/hdel
数据结构介绍
redis是键值对的数据库,key一般为String,value的类型可以多种多样
redis的类型:

redis的通用命令
(对任何key都适用)
KEYS
查看符合模板的所有key
效率不高,在生产环境下不建议使用
>keys * #查询所有
>keys a* # 查询所有a(模糊查询)
DEL
删除一个或多个key
>DEL name #删除 name
>DEL k1 k2 k3 k4 # 批量删除
#返回值代表删除的key的数量
EXISTS
判断一个KEY是否存在
存在返回1,不存在返回0
EXPIRE
给一个key设置有效期,到期自动删除
>EXPIRE age 20 # 设置age为20秒
TTL
查看某个key的有效期
有效期为-1代表永久有效,-2的时候就是被删除了
String类型
strig是redis种最简单的存储类型
由于字符串格式不同又可以分为三类:
- string:普通字符串
- int :整型
可以进行自增自减 - float:浮点型
可以进行自增自减
不管是哪种格式,底层都是字节数组的形成存储,不过编码方式不同,字符串需要把字符转为编码,所有占用内存更多字符串最大空间不能超过512m
常见的命令
SET
添加或修改一个string类型的键值对
GET
根据KEY获取String类型的value
MSET
批量添加多个String类型的键值对
MGET
根据多个KEY获取String类型的value
INCR
让一个整型key自增1
INCRBY
指定步长让一个整型key自增
INCRBYFLOAT
使一个浮点数自增
SETNX
添加一个类型string的键值对,前提是这个key不存在
SETEX
添加一个key并指定有效期
Key的层次结构
key允许多个单词形成层级结构,多个单词之间用':'隔开如:
项目名:业务名:类型:id
Hash类型
Hash类型,也叫散列,value是一个或多个键值对的对象,类似java中的HashMap
string结构是将对象序列化为json字符串后存储,当需要修改对象的某个字段时很不方便
# hash结构可以将对象的每个字段独立存储
hash结构的value存储的是键值对类型
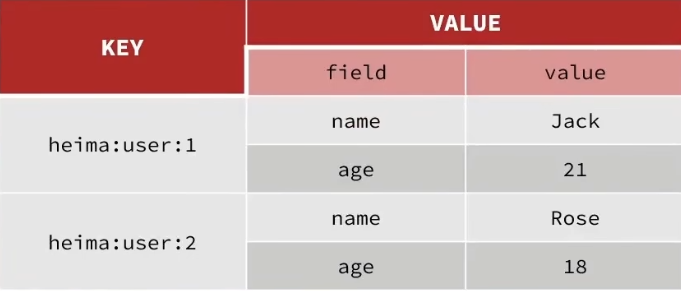
常见命令:

List类型
list类型跟java中的LinkedList比较类似,他的底层可以看成是双向链表,支持正向检索和反向检索,特征也和链表相似
有序、元素可以重复、插入删除快、查询速度慢、
List的常用命令
LPUSH key element
向列表左侧插入一个或多个元素
LPOP key
`移除并返回列表左侧的第一个元素,没有则返回nil
RPUSH key element
向列表右侧插入一个或多个元素
RPOP key
`移除并返回列表右侧的第一个元素,没有则返回nil
LRANGE key star end
返回一段角标范围内的所有元素
BLPOP和BRPOP
与LPOP和RPOP类似,只不过没有元素时等待指定时间,而不是之间返回nil
Set类型
类似与java中的HashSet,可以看成一个values为null的hashmap,具备HashSet的特征:
无序、元素不可重复、查找快、支持交集并集差集等功能
常见命令
SADD key member
向set中添加一个或多个元素
SREM key member
移除set中的指定元素
SCARD key
返回set中元素的个数
SISMEMBER key member
判断一个元素是否存在与set中
SMEMBERS
获取set中所有元素
SortedSet类型
可排序的set集合,每一个元素都带有一个score属性,可以基于score属性对元素进行排序,底层是一个SkipList+hash表
1.可排序
2.元素不重复
3.查询速度快
常用命令

Redis的Java客户端
Jedis
引入依赖
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.7.0</version>
</dependency>
建立连接
public class JedisTest {
private Jedis jedis;
@BeforeEach
public void setUp(){
// 建立连接
jedis= new Jedis("localhost",6379);
// 设置密码
jedis.auth("123456");
// 选择库
jedis.select(0);
//操作redis
//jedis的方法跟命令行操作redis的关键字一样
jedis.set("name","年年");
System.out.println(jedis.get("name"));
//关闭
jedis.close();
}
}
输出:
年年
Jedis连接池
jedis本身是线程不安全的,并且频繁的创建和销毁连接会有性能损耗,因此推荐大家使用jedis连接池代替jedis的直连方式
创建连接池工具类
public class JedisConnectionFactory {
private static final JedisPool jedisPoll;
static {
// 配置连接池
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
jedisPoolConfig.setMaxTotal(8);//最大连接数
jedisPoolConfig.setMaxIdle(8);//空闲连接
jedisPoolConfig.setMinIdle(0);//最小空闲连接
jedisPoolConfig.setMaxWaitMillis(1000);//没有连接时默认值-1,表示无限制等待,设置为1000,到时间就会报错
// 创建连接池对象
jedisPoll=new JedisPool(jedisPoolConfig,"localhost",6379,1000,null);
}
public static Jedis getJedis(){
return jedisPoll.getResource();
}
}
使用连接池
Jedis jedis = JedisConnectionFactory.getJedis();
jedis.close();//关闭连接
SpringDataRedis
springData是spring中数据操作的模块,包含了对各种数据库操作的集成
SpringDataRedis对不同的redis客户端进行了整合(Lettuce和Jedis)
提供RedisTemplate统一API来操作Redis
支持Redis的发布订阅模型
支持哨兵和集群
支持基于Lettuce的响应式编程
支持基于JDK、JSON、字符串、spring对象的数据序列化和反序列化
支持基于Redis的JDKCollection
springDataRedis提供了RedisTemplate的工具类,封装了对Redis的操作,并且将不同的数据类型的操作API封装到了不同的类型中

SpringDataRedis快速入门
创建spring boot项目导入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!-- 连接池 /-->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
添加yaml配置
spring:
redis:
host: localhost
port: 6379
password: 123456
lettuce:
pool:
max-active: 8
max-idle: 8
min-idle: 0
max-wait: 1000
使用redistemplate
@Autowired
private RedisTemplate redisTemplate;
@Test
void contextLoads() {
redisTemplate.opsForValue().set("name","年年");//它接收两个Object类型,redisTemplate利用jdk序列化工具转为字节形式
Object name = redisTemplate.opsForValue().get("name");
System.out.println(name);
}
RedisTemplate和RedisSerializer
redistemplate可以接收任意Object作为值写入redis,只不过会把object序列化为字节形式(默认采用jdk序列化工具)

缺点
- 可读性差
- 内存占用大
我们可以手动修改他的序列化工具
@Configuration
public class redisConfig {
@Bean
public RedisTemplate<String,Object> redisTemplate(RedisConnectionFactory connectionFactory){
//创建redistemplate对象
RedisTemplate<String, Object> template = new RedisTemplate<>();
//设置连接工厂
template.setConnectionFactory(connectionFactory);
//创建json序列哈工具
GenericJackson2JsonRedisSerializer jsonserializer = new GenericJackson2JsonRedisSerializer();
//设置key序列化 ------ redis的key都是string类型的所以序列化成string
template.setKeySerializer(RedisSerializer.string());
template.setHashKeySerializer(RedisSerializer.string());
//设置value序列化-----
template.setValueSerializer(jsonserializer);
template.setHashValueSerializer(jsonserializer);
return template;
}
}
StringRedisTemplate
尽管JSON的序列化可以满足我们的需求,但是依然存在一些问题

为了在反序列化时知道对象的类型,json序列化时会将类的class类型写入json,存入redis,会带来额外的内存开销。
为了节省内存空间,我们不会用json的序列化器,而是使用string的序列化器,要求只能存储String类型的key和value,当需要存储Java对象时,手动完成对象的序列化和反序列化
Spring提供了一个StringRedisTemplate类,key和value的序列化默认就是string的方式
class DataDemoApplicationTests {
@Autowired
private StringRedisTemplate redisTemplate;
@Test
void contextLoads() {
redisTemplate.opsForValue().set("name","年年");
System.out.println(redisTemplate.opsForValue().get("name"));
}
}
存储和获得对象时需要手动序列化
@Autowired
private StringRedisTemplate redisTemplate;
private static final ObjectMapper mapper = new ObjectMapper();
@Test
void contextLoads() throws JsonProcessingException {
User user = new User("年年",20);//创建对象
//手动序列化
String userJson = mapper.writeValueAsString(user);
//写入数据
redisTemplate.opsForValue().set("user:200",userJson);
//获取数据
//手动反序列化
String s = redisTemplate.opsForValue().get("user:200");
User user_result = mapper.readValue(s, User.class);
System.out.println(user_result);
}
RedisTemplate操作Hash类型
redisTemplate.opsForHash().put("user:001","name","年年");
redisTemplate.opsForHash().put("user:001","age","20");
//获得hash
Map<Object, Object> map = redisTemplate.opsForHash().entries("user:001");
System.out.println(map);
//获取数据
//手动反序列化
String s = redisTemplate.opsForValue().get(“user:200”);
User user_result = mapper.readValue(s, User.class);
System.out.println(user_result);
}
##### RedisTemplate操作Hash类型
```java
redisTemplate.opsForHash().put("user:001","name","年年");
redisTemplate.opsForHash().put("user:001","age","20");
//获得hash
Map<Object, Object> map = redisTemplate.opsForHash().entries("user:001");
System.out.println(map);


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









