




 本文详细介绍各种排序算法的基本概念、分类及实现方式,包括冒泡排序、选择排序、插入排序等,并对比了各种算法的时间复杂度。
本文详细介绍各种排序算法的基本概念、分类及实现方式,包括冒泡排序、选择排序、插入排序等,并对比了各种算法的时间复杂度。
目录
一、排序算法的概念:
排序也称排序算法 (Sort Algorithm),排序是将一 组数据,依指定的顺序进行排列 的过程
二、排序算法的分类:
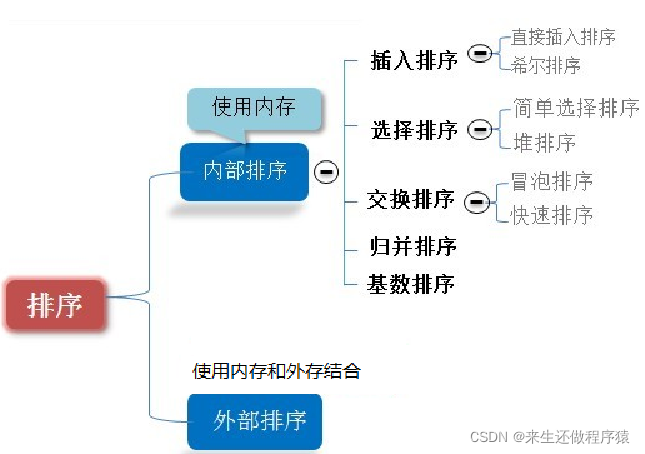
1) 内部排序: 指将需要处理的所有数据都加载 到内部存储器中进行排序。
2) 外部排序法: 数据量过大,无法全部加载到内 存中,需要借助外部存储进行 排序
三、算法的时间复杂度
时间频度:一个算法中的语句执行次数称为语句频度或时间频度。记为T(n)
时间复杂度:一般情况下,算法中的基本操作语句的重复执行次数是问题规模n的某个函数,用T(n)表示,若有某个辅助函数f(n),使得当n趋近于无穷大时,T(n) / f(n) 的极限值为不等于零的常数,则称f(n)是T(n)的同数量级函数。记作 T(n)=O( f(n) ),称O( f(n) ) 为算法的渐进时间复杂度,简称时间复杂度。
T(n) 不同,但时间复杂度可能相同。 如:T(n)=n²+7n+6 与 T(n)=3n²+2n+2 它们的T(n) 不同,但时间复杂度相同,都为O(n²)。
常见的时间复杂度:
常数阶O(1)
对数阶O(log2n)【while循环】
线性阶O(n)【for循环】
线性对数阶O(nlog2n)【for循环嵌套while】
平方阶O(n^2)【双层for循环】
立方阶O(n^3)【三层for循环】
k次方阶O(n^k)
指数阶O(2^n)
常见的算法时间复杂度由小到大依次为:Ο(1)<Ο(log2n)<Ο(n)<Ο(nlog2n)<Ο(n2)<Ο(n3)< Ο(nk) <Ο(2n) ,随着问题规模n的不断增大,上述时间复杂度不断增大,算法的执行效率越低
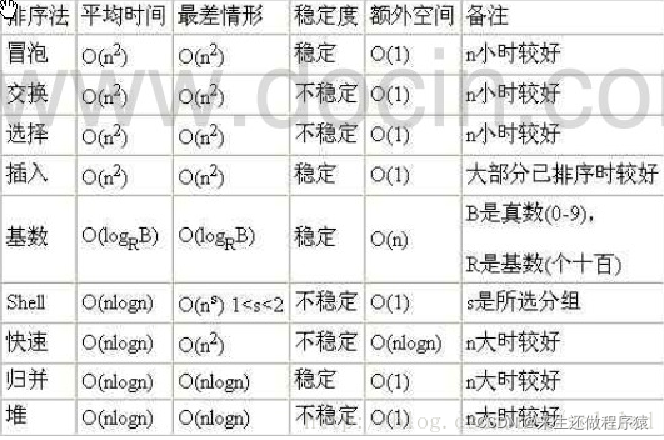
排序算法的时间复杂度对比:
四、交换排序--冒泡排序
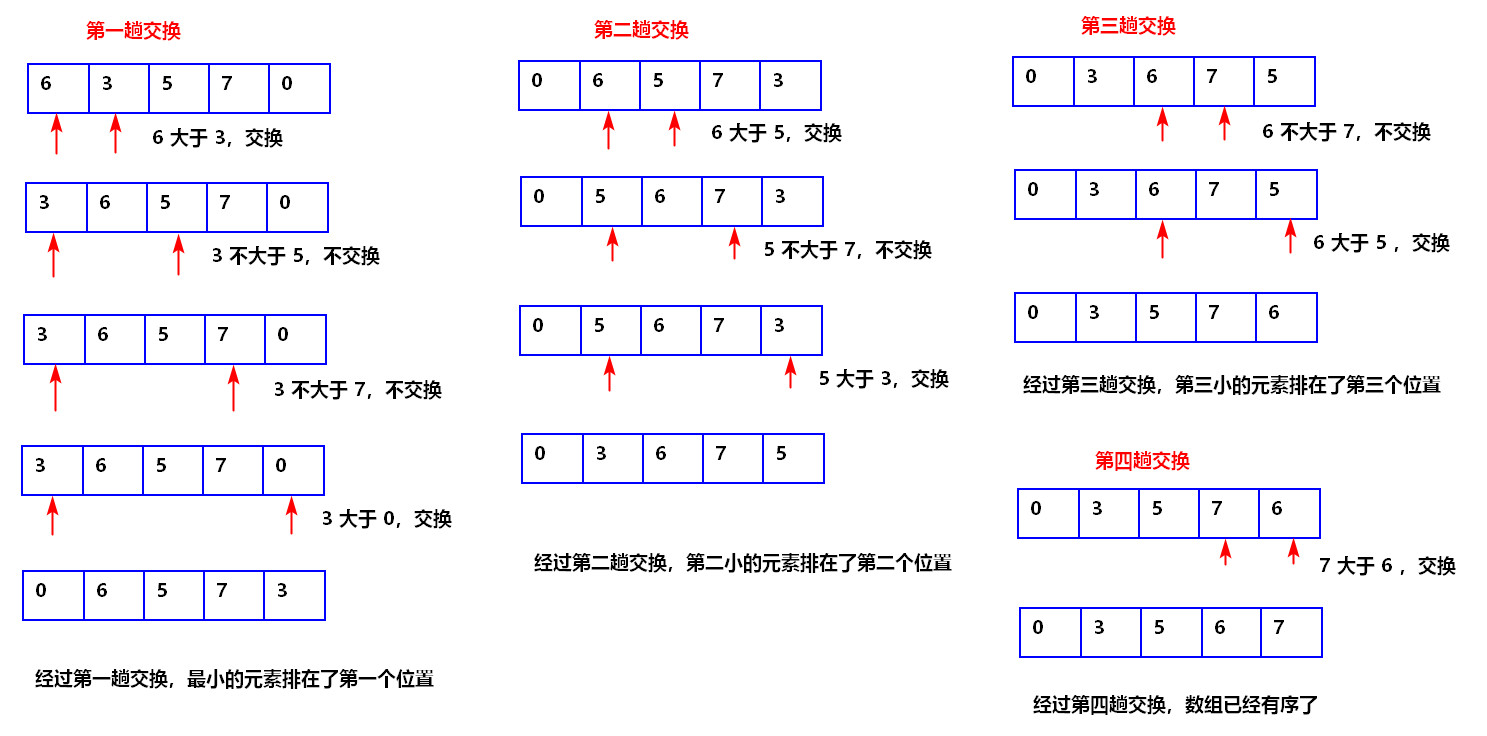
基本思想:通过对待排序的序列,从前完后依次比较相邻的值,逆序则进行交换,将小的值放到前面。
图解:
冒泡法总共进行 元素个数 -1 次冒泡,每次一冒泡可将一个数据放到正确的位置上
每次冒泡又进行 元素个数-1-i 次比较【i就是第几次冒泡】
代码实现:
//冒泡排序法a
public static void bubble(int[] array){
boolean flag = false ;
// i 表示冒泡的次数
for (int i = 0; i < array.length -1 ; i++) {
//j 表示每次冒泡需进行比较的次数
for (int j = 0; j < array.length-1-i; j++) {
if (array[j] > array[j+1]){ // 升序【降序是<】
flag = true ;
int temp = array[j] ;
array[j] = array[j+1];
array[j+1] = temp ;
}
}
if (!flag){
//如果没有进行交换,直接终止循环。无需比较
break;
}else{
//每次交换完,需将标记重置
flag = false ;
}
}
}使用冒泡法对80000个数据进行排序总耗时:10000ms左右
int[] array = new int[80000];
Random random = new Random() ;
for (int i = 0; i < 80000; i++) {
//获取随机数
array[i] = random.nextInt();
}
long start = System.currentTimeMillis();
bubble(array);
long end = System.currentTimeMillis();
System.out.println("冒泡法耗时:" + (end - start));五、选择排序
基本思想:
第一次比较,假设数组一个中元素就是最小值【或者最大值】,将这个最小值与后面的元素进行比较,如果发现比假设最小值还要小,就进行交换。直到与后面的元素都比较完
第二次比较将第二个元素假设为最小值,与后面的元素一 一进行比较,还是和上面一样的操作
第三次比较....
.....
一共进行 元素个数 -1 次比较
图解:
代码实现:第一种写法
对80000个数据进行排序总耗时:8500ms左右
//选择法排序--第一种解法
public static void select(int[] array){
//一共进行 array.length -1 次比较
for (int i = 0; i < array.length -1 ; i++) {
int minIndex = i ; //第一次假设第一个元素为最小值,第二次假设第二个元素为最小值
for (int j = i+1; j < array.length; j++) {
if (array[minIndex] > array[j]){
//交换
int temp = array[j];
array[j] = array[minIndex] ;
array[minIndex] = temp ;
}
}
}
}第二种写法:
对80000个数据进行排序总耗时:3500ms左右
//选择法排序--第一种解法
public static void select(int[] array) {
//一共进行 array.length -1 次比较
for (int i = 0; i < array.length - 1; i++) {
int minIndex = i; //第一次假设第一个元素为最小值,第二次假设第二个元素为最小值
int minVal = array[i];
for (int j = i + 1; j < array.length; j++) {
if (minVal > array[j]) {
//如果有比最小值还小的数据,将最小值的下标和数值保存到 minIndex 和 minVal
minIndex = j;
minVal = array[j];
}
}
if (minIndex != i) {
//如果最小值元素不是一开始假设的,就将俩个元素交换
array[minIndex] = array[i];
array[i] = minVal;
}
}
}六、插入排序
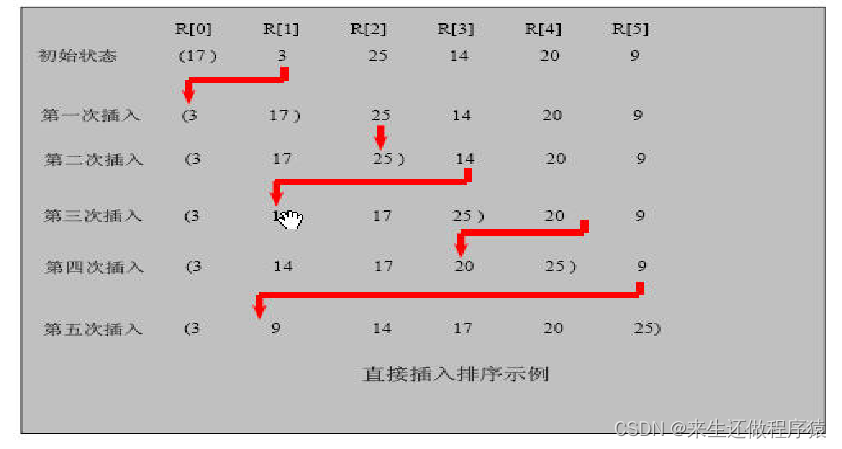
基本思想:
1、 将数组中的元素,看做俩部分,将数组中第一个元素看做是有序列表,其余的元素都是无序列表。
2、将无序列表中的元素与有序列表中最后一个元素进行比较,如果插入的元素比有序列表最后一个元素还大,就直接插入有序列表的最后面。
3、如果插入的元素比有序列表最后一个元素小,就将有序列表往前挪一位,与其进行比较,找到合适的位置插入
图解:
总共进行 元素个数 -1 次插入
代码实现:
对80000个数据进行排序总耗时:1000ms左右
//插入排序
public static void insert(int[] array) {
//从第二个数据开始进行比较。将第一个元素看作有序列表
for (int i = 1; i < array.length; i++) {
//有序列表元素的下标
int index = i - 1;
//插入的数据
int insertVal = array[i];
while (index >= 0 && insertVal < array[index]) {
/*
当插入的数据比有序列表中最后一个元素小时
把有序列表中最后一个元素向后复制一个,index--,往前移一个位置,继续判断
*/
array[index + 1] = array[index];
index--;
}
//当插入的数据比有序列表中的数据大时,就将插入的数据插入到与他比较元素的后面
array[index + 1] = insertVal;
}
}★★★★★:对 index +1 进行一下解释:
拿上图第四次插入举例:[3 , 14, 17, 25] 20 , 9 插入20
1、将插入的值赋给minVal = 20 。
2、有序列表中最后一个元素是 25 ,下标是 3 ,index = 3
3、将 20 与 25 进行比较,发现 20 比 25 小,就将有序列表中最后一个元素向后复制一位
有序列表变成了 [3 , 14, 17, 25, 25] 20 , 9 index--,向前移动一位 index = 2 ,将 20 与 17 进行比较,发现 20 比 17 小,即将 20 插入 到 17 的后边 有序列表变成了:[3 , 14, 17, 20, 25] 9
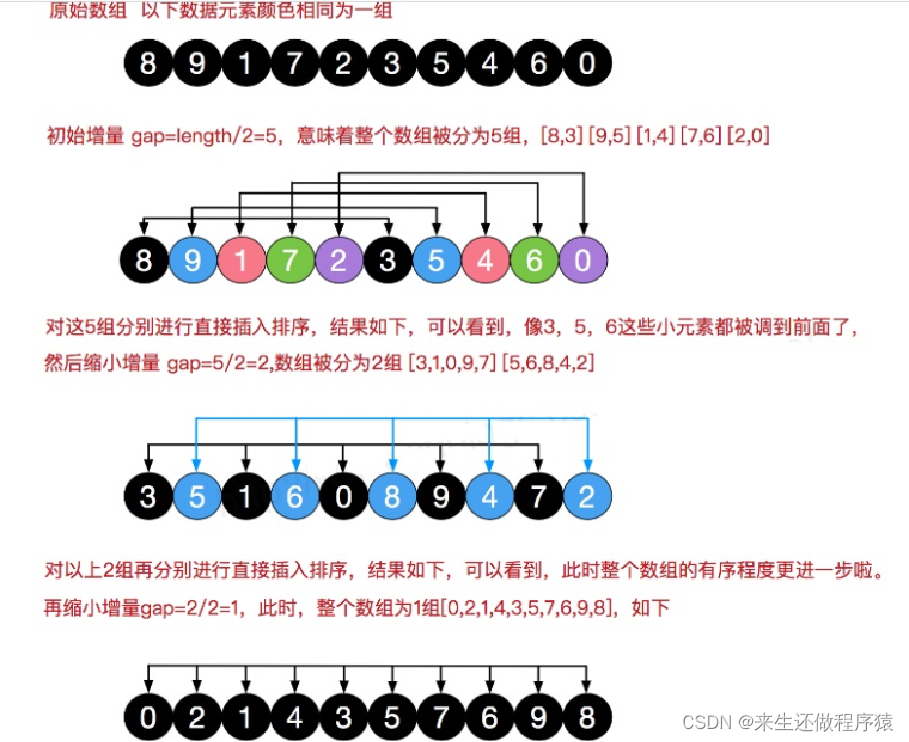
七、希尔排序--shell排序
插入排序存在的问题:假设对数组 arr = {2,3,4,5,6,1} 进行排序,这时需要插入的数 1(最小), 这样的过程是: {2,3,4,5,6,6} {2,3,4,5,5,6} {2,3,4,4,5,6} {2,3,3,4,5,6} {2,2,3,4,5,6} {1,2,3,4,5,6}。仅仅是插入一个数据就需要 6 步,效率太低。所以使用希尔排序会提高速度
希尔排序是希尔(Donald Shell)于1959年提出的一种排序算法。希尔排序也是一种插入排序,它是简单插入排序经过改进之后的一个更高效的版本,也称为缩小增量排序。
基本思想:
希尔排序是把记录按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的元素越来越多,当增量减至1时,整个数组恰被分成一组,算法便终止
图解:

希尔排序第一种写法--交换法:【效率较低】
对80000个数据进行排序总耗时:5400ms左右
//希尔排序
public static void shell(int[] array) {
//分组:gap代表组数,增量。第一次分为:5组,增量为5.第二次分为:2组,增量为2,第三次分为:1组,增量为1
for (int gap = array.length / 2; gap > 0; gap = gap / 2) {
//对数组中的数据分组
for (int i = gap; i < array.length; i++) {
for (int j = i - gap; j >= 0; j = j - gap) {
if (array[j] > array[j + gap]) {
//如果同一组中前面的数比后面的数大,就进行交换【升序】
int temp = array[j];
array[j] = array[j + gap];
array[j + gap] = temp;
}
}
}
}
}希尔排序第二种写法--插入法
对80000个数据进行排序总耗时:30ms左右
//希尔排序--插入法
public static void shellByInert(int[] array) {
for (int gap = array.length / 2; gap > 0; gap = gap / 2) {
for (int i = gap; i < array.length; i++) {
//插入法
int index = i;
//插入的值
int inertVal = array[i];
while (index - gap >= 0 && inertVal < array[index - gap]) {
//每一组中,如果后面的数比前面的数小,将前面的数复制后移一位
array[index] = array[index - gap];
//index前移,继续判断
index = index - gap;
}
//找到插入位置。
array[index] = inertVal;
}
}
}八、快速排序--快排
快速排序是对冒泡法的一种改进。通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列
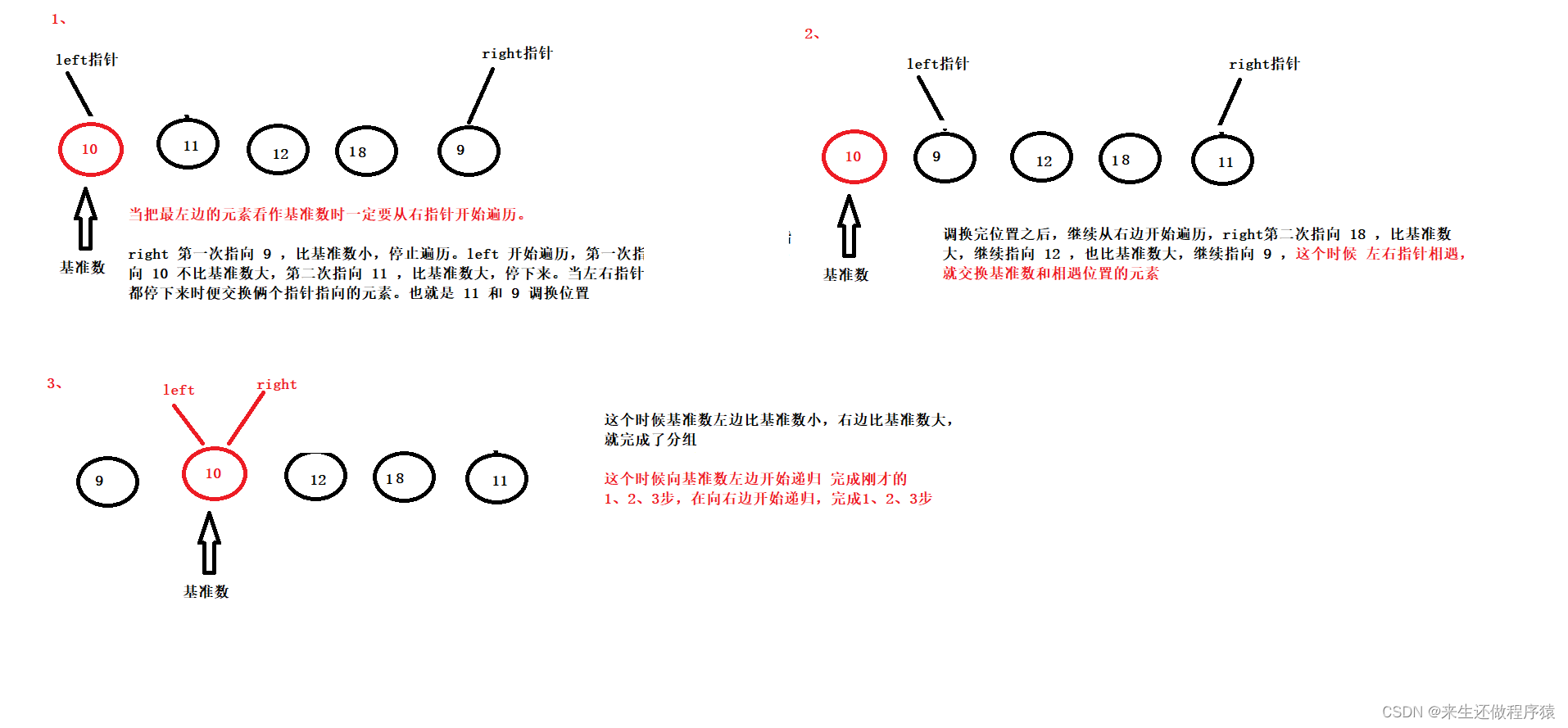
快排思路:
1、定义俩个变量指针 left ,right。帮助进行数组遍历。left 指向数组最左边的元素,right 指向最右边的元素
2、将数组最左边的元素看做基准数 pivot【最右边或者中间都可以】,基准数左边的元素都比基准数小,基准数右边的元素都比基准数大。【把数组最左边元素看做基准数时,要从右边开始遍历,在从左边开始遍历。如果将右边元素看做基准数,则相反】
3、right 从右边开始遍历,当遇到比基准数小的值便会停下里。 left 从左边开始遍历,当遇到比基准数大的值便会停下来。当left,right都停下来的时候,交换俩个元素的位置。直到循环 左右指针重合的时候,停止交换。
4、当左右指针重合时,将 基准数pivot 和 重合位置的元素进行交换。
5、这个时候基准数左边就是比基准数小的元素,右边是比基准数大的元素了。完成了分割的俩部分
6、这时对左边进行递归操作,重复1、2、3、4、5步。对右边进行递归操作,重复1、2、3、4、5步
图解:
代码实现:
//快排--快速排序
/**
* @param array 排序的数组
* @param left 左边开始的下标
* @param right 右边结束的下标
*/
public static void quick(int[] array, int left, int right) {
if (left > right) {
return;
}
int l = left; //左边指针
int r = right; //右边指针
int pivot = array[left]; //基准数
//当左指针和右指针相遇时,便停下来
while (l != r) {
//从右边开始遍历
while (pivot <= array[r] && l < r) {
r--;
}
//左边遍历
while (pivot >= array[l] && l < r) {
l++;
}
//当左右指针都停下的时候,进行交换
int temp = array[l];
array[l] = array[r];
array[r] = temp;
}
//当退出while循环时,说明 左右指针相遇,开始交换基准数和相遇位置的元素
array[left] = array[r];
array[r] = pivot;
//向左边递归
quick(array, left, r - 1); //这里用r或者l无所谓,因为l和r已经相遇。指向了基准数
//向右边递归
quick(array, r + 1, right);
}九、归并排序
归并排序(MERGE-SORT)是利用归并的思想实现的排序方法,该算法采用经典的分治(divide-and-conquer)策略(分治法将问题分(divide)成一些小的问题然后递归求解,而治(conquer)的阶段则将分的阶段得到的各答案"修补"在一起,即分而治之)。
图解:
分:将一组数据拆分成最小的序列,也就是一个元素一个序列
治:对有序的序列进行合并,最终得到一个有序的序列【核心操作】
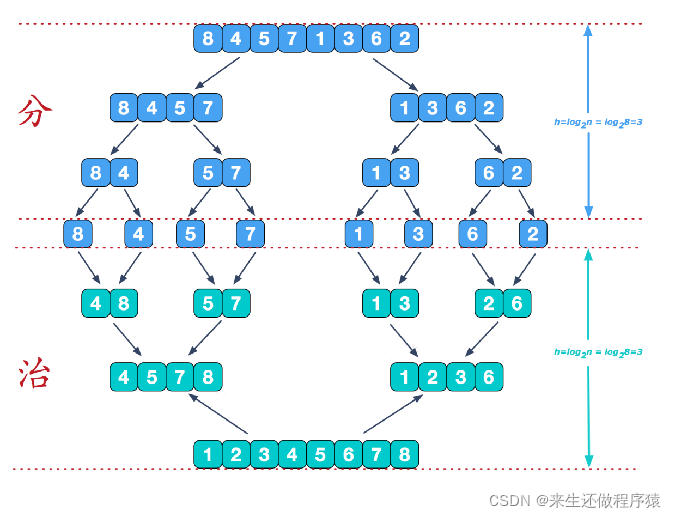
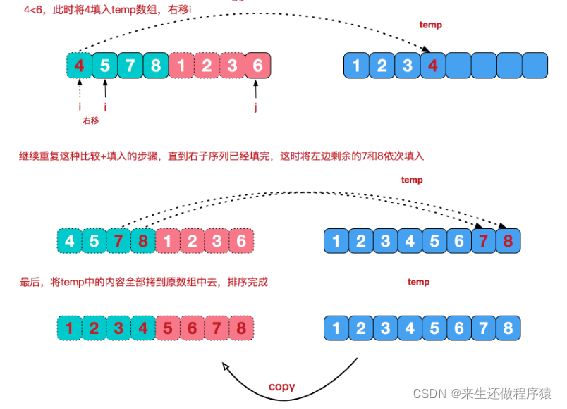
再来看看治阶段,我们需要将两个已经有序的子序列合并成一个有序序列,比如上图中的最后一次合并,要将[4,5,7,8]和[1,2,3,6]两个已经有序的子序列,合并为最终序列[1,2,3,4,5,6,7,8],来看下实现步骤:
1、将左子序列和右子序列的每个值都进行比较,把较小的值放到temp集合中
2、最后将左子序列或者右子序列中剩余的元素,依次加入到temp集合中
3、将temp拷贝会原数组
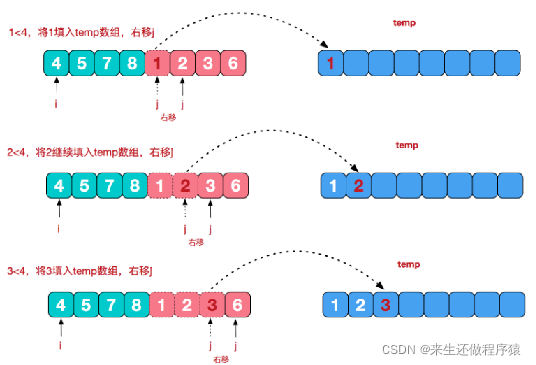
代码实现:
对80000个数据进行排序总耗时:20ms左右
//分解
public static void divide(int[] arr, int left, int right, int[] temp) {
if (left < right) {
int mid = (left + right) / 2; //中间指针
//对左边进行分解
divide(arr, left, mid, temp);
//对右边进行分解
divide(arr, mid + 1, right, temp);
//合并
conquer(arr, left, mid, right, temp);
}
}
/**
* 功能:将俩个部分的子序列进行合并
*
* @param arr 待排序的数组
* @param left 指向左子序列的指针
* @param mid 指向中间
* @param right 指向右子序列的指针
* @param temp 临时数组,用于保存最后排序完的结果
*/
public static void conquer(int[] arr, int left, int mid, int right, int[] temp) {
int l = left;
int r = mid + 1;
int index = 0;//指向临时数组
while (l <= mid && r <= right) {
if (arr[l] <= arr[r]) {
//如果左边的数小于等于右边的数,就将左边的数放到temp中
temp[index++] = arr[l++];
} else {
//相反右边的数小于左边的数,就将右边的数放到temp中
temp[index++] = arr[r++];
}
}
//当左边有剩余元素的时候,加到temp中
while (l <= mid) {
temp[index++] = arr[l++];
}
//当右边有剩余元素时,加到temp中
while (r <= right) {
temp[index++] = arr[r++];
}
//最后将temp数组拷贝到原数组中
index = 0;
while (left <= right) {
arr[left++] = temp[index++];
}
}十、基数排序
基数排序(radix sort)属于“分配式排序”(distribution sort),又称“桶子法”(bucket sort)或bin sort,顾名思义,它是通过键值的各个位的值,将要排序的元素分配至某些“桶”中,达到排序的作用 基数排序法是属于稳定性的排序,基数排序法的是效率高的稳定性排序法 基数排序(Radix Sort)是桶排序的扩展
图解:
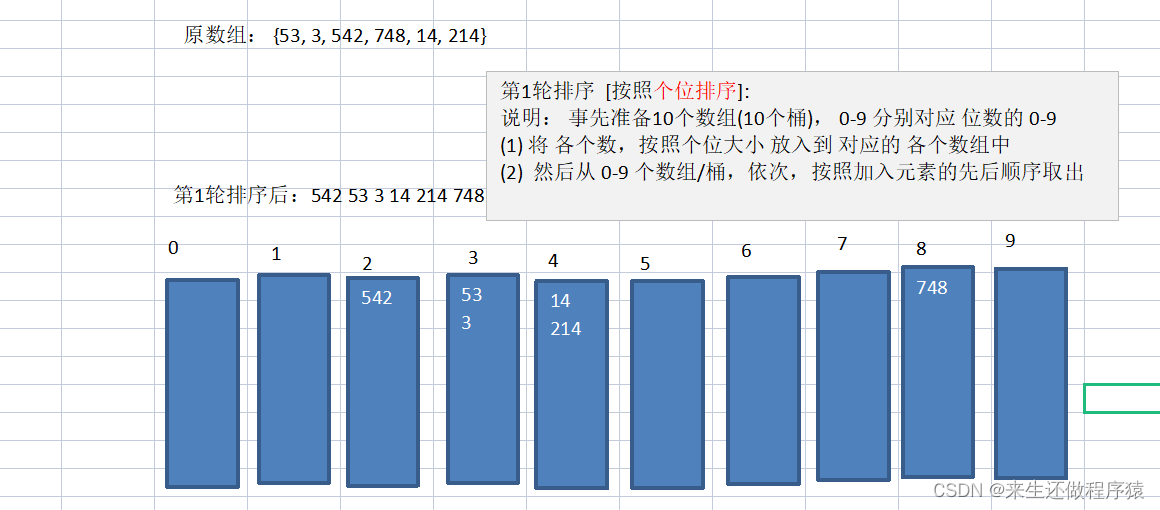
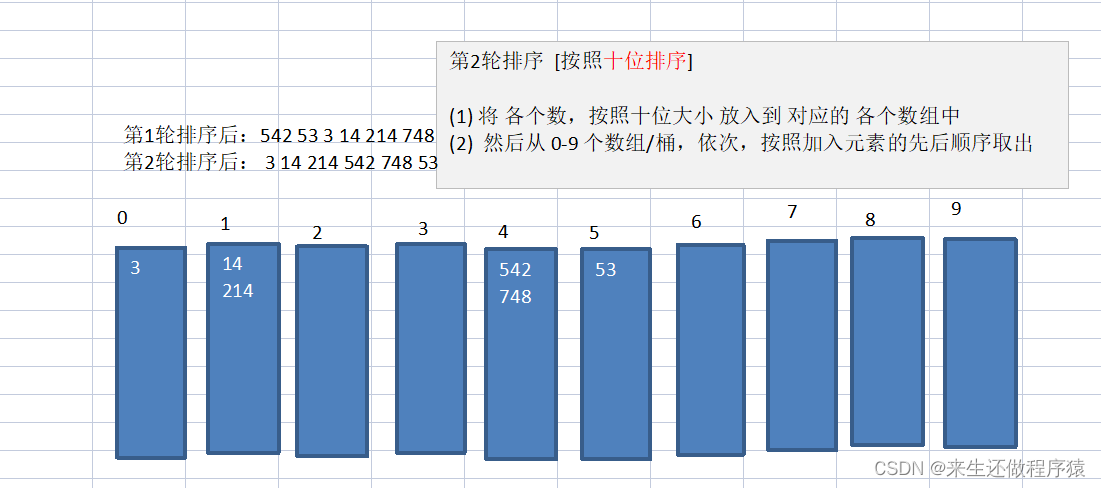
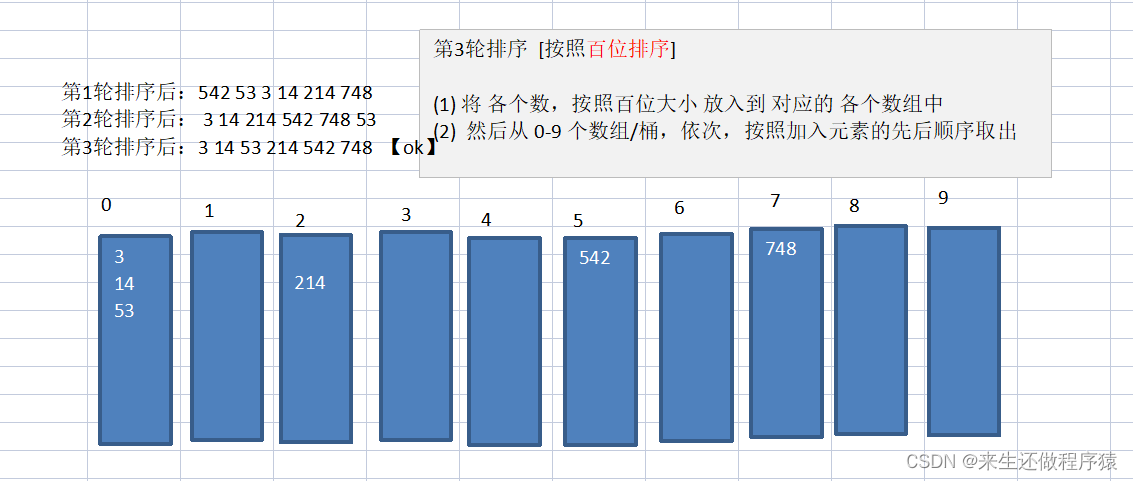
1、首先获取数组中最大的一个数,并求他的位数
2、创建一个二维数组表示桶子的数量10个以及每个桶子中的容量。并且用一个一位数组记录每个桶子中数据的个数
3、对数组中每个数据取到个位,并把每个数据放到对应的桶子中,每放入一个数据,桶子的数据个数+1
4、所有数据都放入后,判断每个桶子的容量是否为0,不为0将每个桶子的数据复制给原数组。【复制完后一定要将桶子中的个数清0】
5、取到每个数据的十位,百位....并完成上面的2、3、4步
代码实现:
对80000个数据进行排序时总耗时:30ms左右
//基数排序
public static void radix(int[] arr) {
//1、获取数组中最大的数
int max = 0;
for (int i = 0; i < arr.length; i++) {
if (max < arr[i]) {
max = arr[i];
}
}
//求最大数的位数
int length = (max + "").length();
//2、创建10个桶子,分别对应数字0~9.每个桶子的容量为数组的长度
int[][] bucket = new int[10][arr.length];
//用来表示桶子中数据的个数 比如:count[0] = 3 .表示第一个桶子中有三个数据
int[] count = new int[10];
for (int i = 0, n = 1; i < length; i++, n = n * 10) {
for (int j = 0; j < arr.length; j++) {
//3、对数组进行遍历。获取每一个数据的个位数,十位数,百位数
int digit = arr[j] / n % 10;
//4、按对应的数字放到对应的桶子中,桶子的容量并+1
bucket[digit][count[digit]++] = arr[j];
}
int index = 0; //指向原数组的指针
//6、将桶子中的数据依次取出来放回原数组中[共有10个桶子]
for (int l = 0; l < 10; l++) {
if (count[l] != 0) {//判断桶子中的数据是否等于0
for (int k = 0; k < count[l]; k++) {
arr[index++] = bucket[l][k];
}
}
//每遍历一个桶,将桶中的数据进行清 0
count[l] = 0;
}
}
}使用基数排序时的注意事项:
1、基数排序是对传统桶排序的扩展,速度很快.
2、基数排序是经典的空间换时间的方式,占用内存很大, 当对海量数据排序时,容易造成 OutOfMemoryError 。
3、基数排序是稳定的。[注:假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,则称这种排序算法是稳定的;否则称为不稳定的]
4、有负数的数组,我们不用基数排序来进行排序


















 11万+
11万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











