




强化学习框架VeRL全面解析
当前的RL框架一览
字节系:
VeRL
CURE(RL for coding)
阿里系:
ROLL淘天爱橙团队
智谱:
slime
huggingface:
trl
VeRL的特点
由于强化学习算法在LLM时代中,对与“灵活性”和“高效性”的双重需求,VeRL应运而生。
其主要特点包括:【Single-controller、multi-controller 以及Hybrid Engine】
- 引入single-controller的范式思想;将复杂的RL workflow简化为20几行代码;
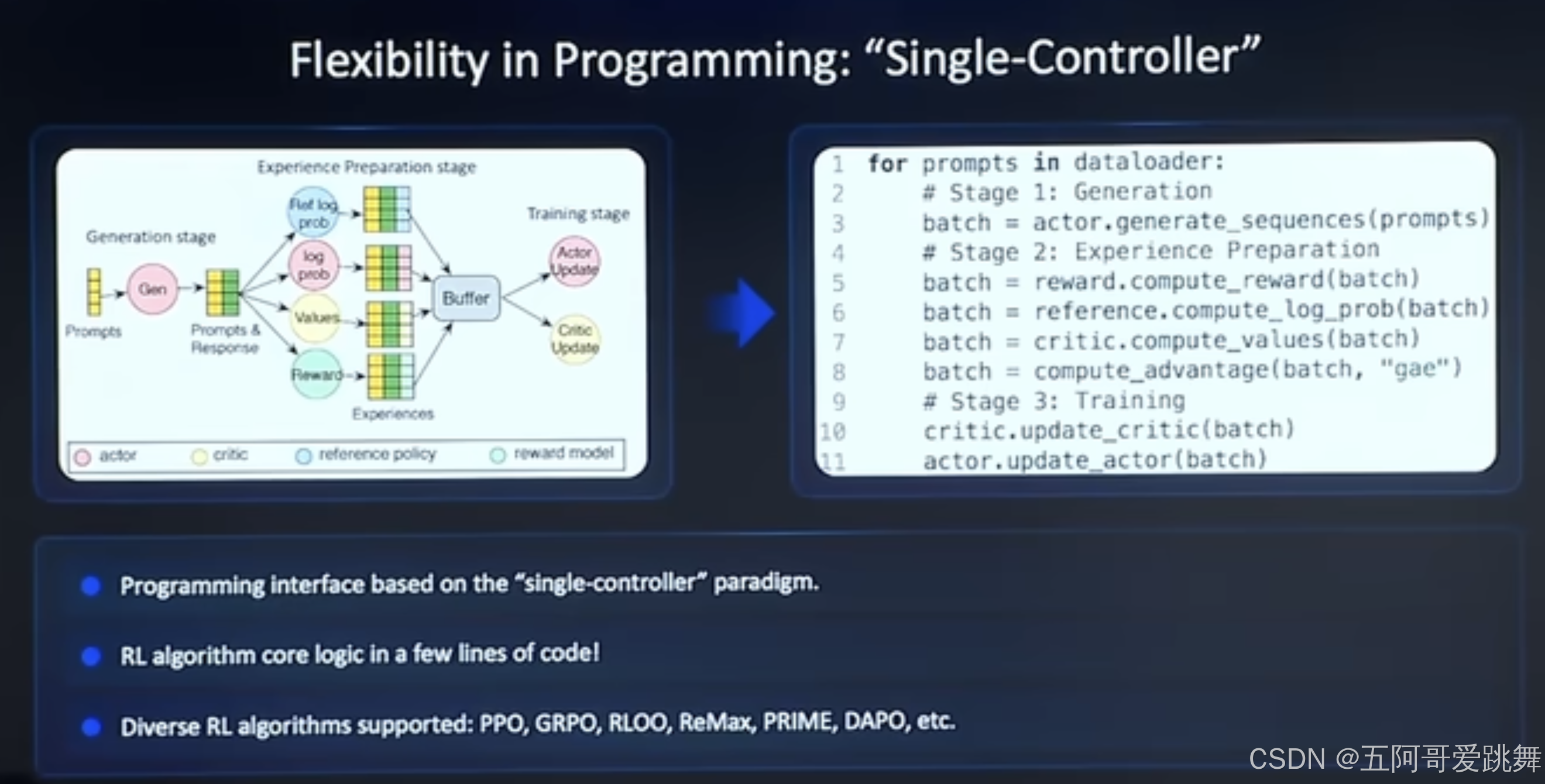
- 引入multi-Controller的思想:实现高效数据并行、训练和生成:

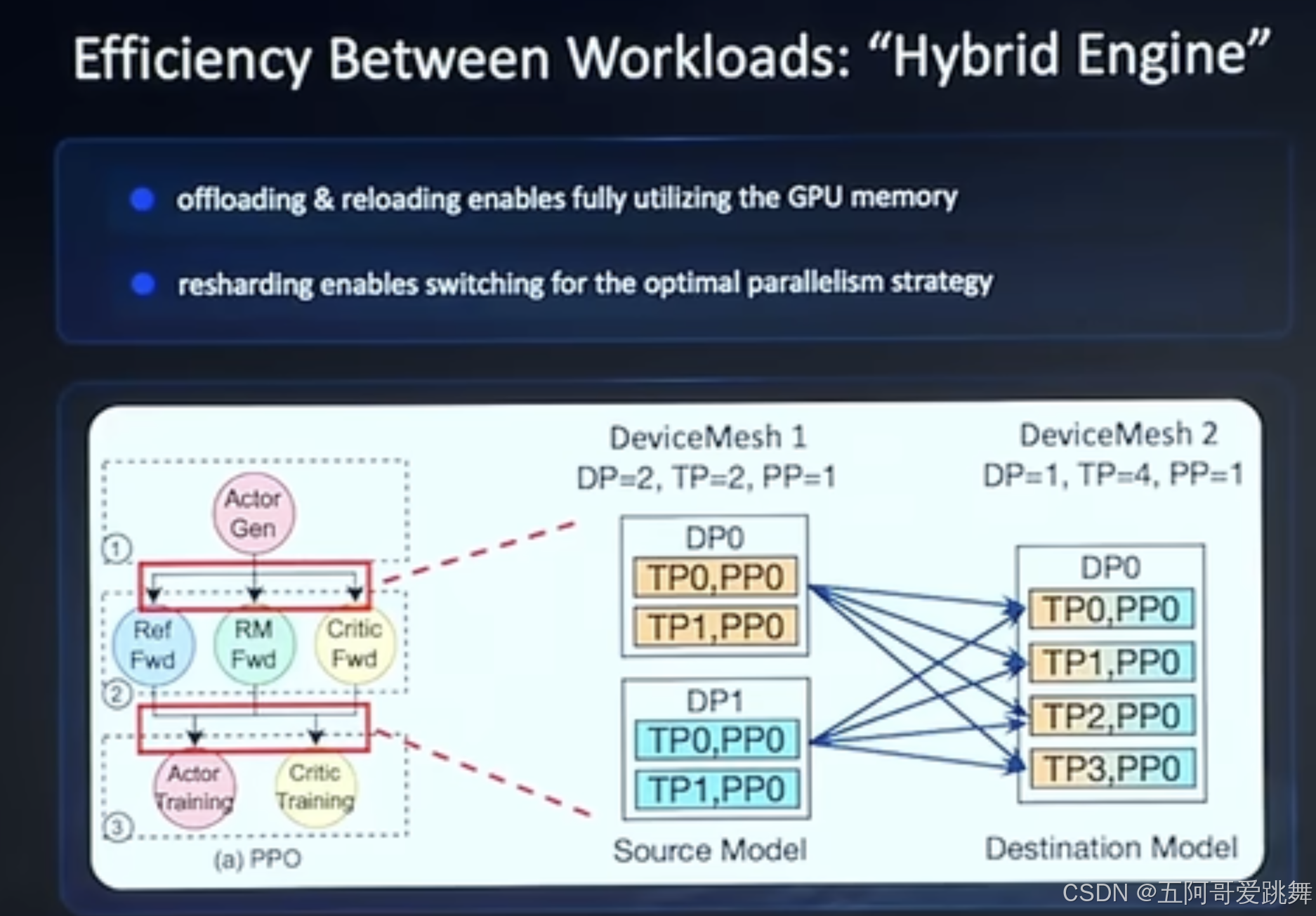
针对RL当中各个operator之间效率的优化,VeRL引入了Hybrid Engine
其中包括:offloading&reloading;并行策略切换

VeRL分布式框架—分布式新范式
分布式框架的实现思路主要有两种:
**single-controller:**一个中心controller来控制所有的worker进行对应任务;【single controller来掌控全局】
multi-controller: 每一个worker独立控制自身,通过其他方式实现并行,例如数据并行,每个worker之间通过通信的方式汇总并行数据。【通过worker间通信来协调】
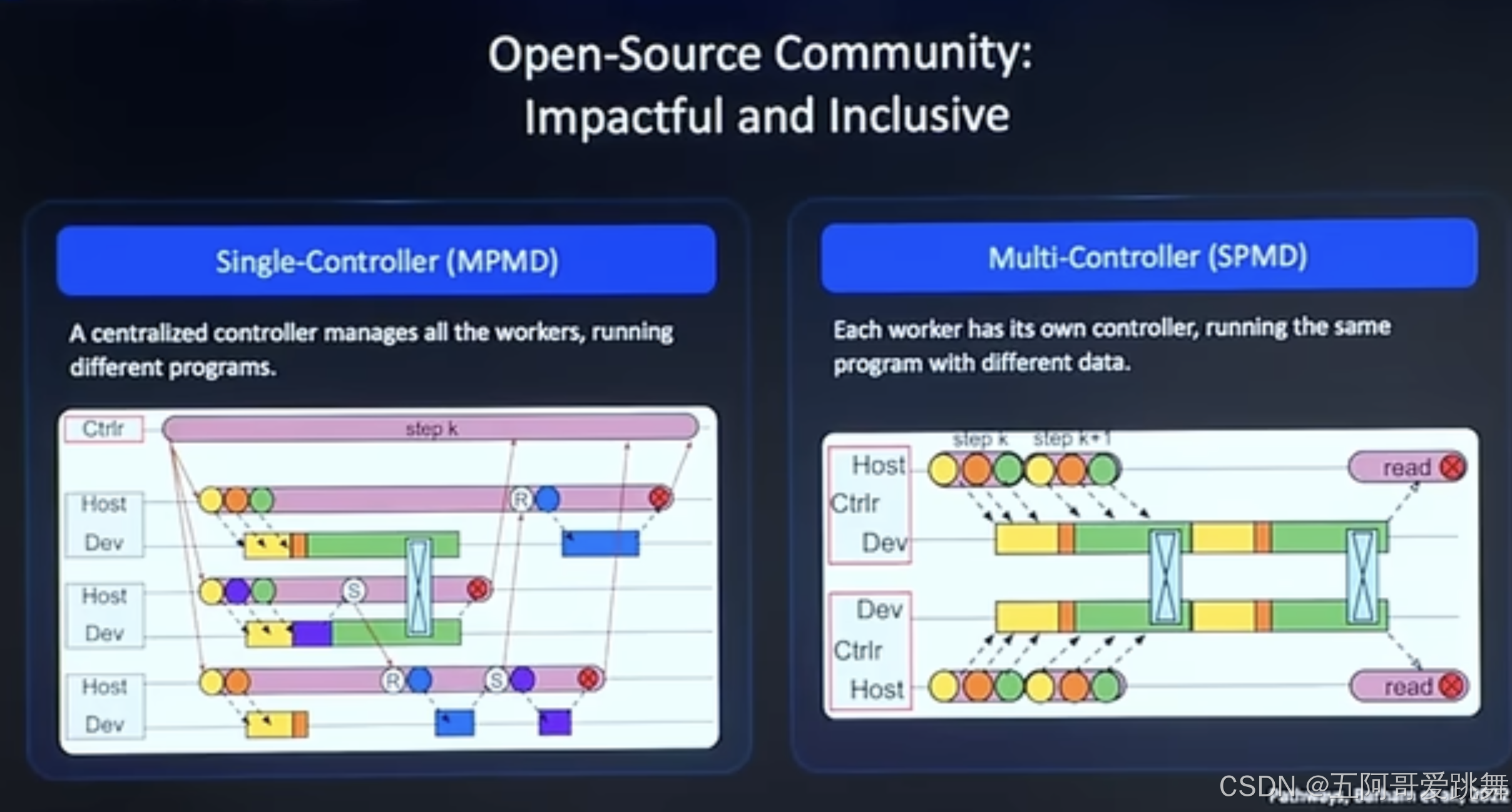
两种方案各有优略:

Hybrid Flow分布式范式
新范式Hybrid Flow,提出了Hybrid Controller思路:结合Single- Controller和Multi-controller。
数据调动上灵活的中央控制+在大规模分布式计算上实现高效的分布式通信:通过一个Single-Controller进行全局的控制,而具体的生成和计算交给muliti-controller
single-controller 通过远程进程调用PRC来控制multi-controller

在代码中,通过@register装饰器,对multi-controller进一步进行优化。
VeRL调试方法
安装和启动分布式调试插件
首先,由于VeRL采用Ray进行分布式运行,因此传统的基于vscode的调用方法无法生效,需要安装插件Ray distributed debugger
插件安装后确保需要debug的环境中安装了ray debug所需要的依赖,如下:
代码ide: Visual Studio Code
ray[default] >= 2.9.1
debugpy >= 1.8.0
环境配置:
conda create -n myenv python=3.9
conda activate myenv
pip install "ray[default]" debugpy
插件安装成功后会出现下图2中左下角1处 图标,然后点击2处 add cluster,在3处 添加服务器集群地址和端口号,ray默认地址 127.0.0.1:8265 (可Enter直接添加此地址)
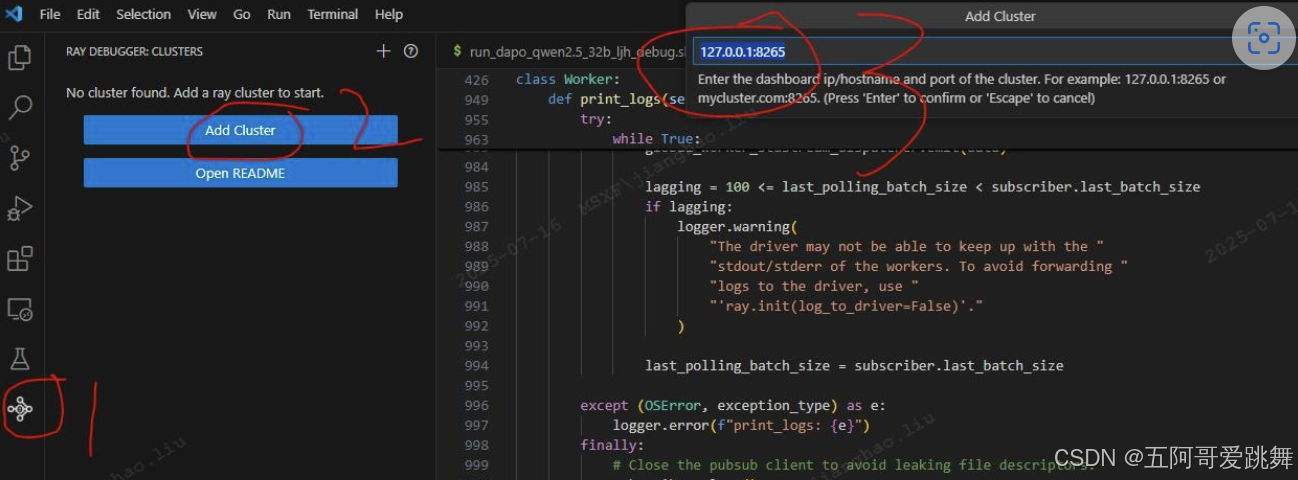
此时在集群Cluster未启动的情况下显示如下的connecting状态即为插件配置启动成功
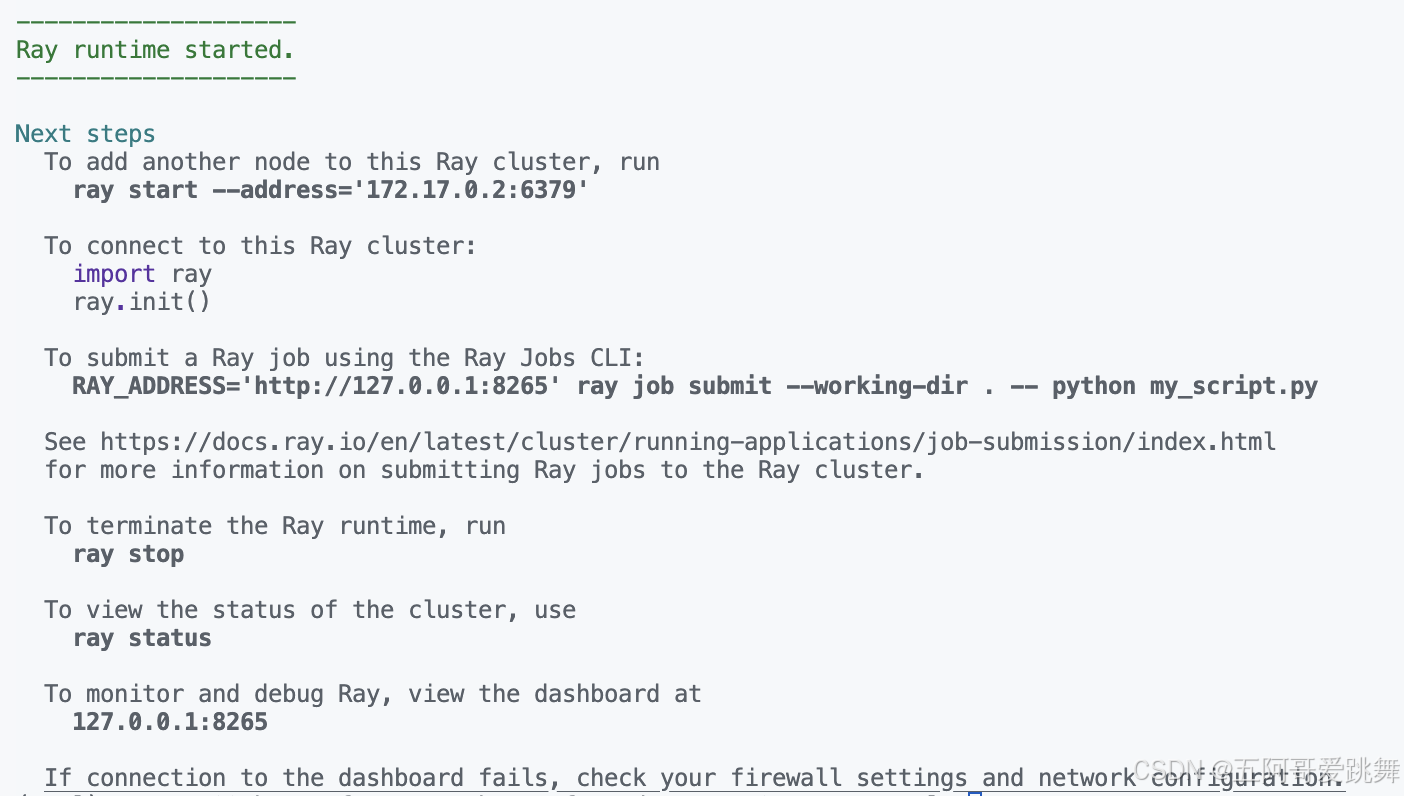
然后启动ray
ray start --head
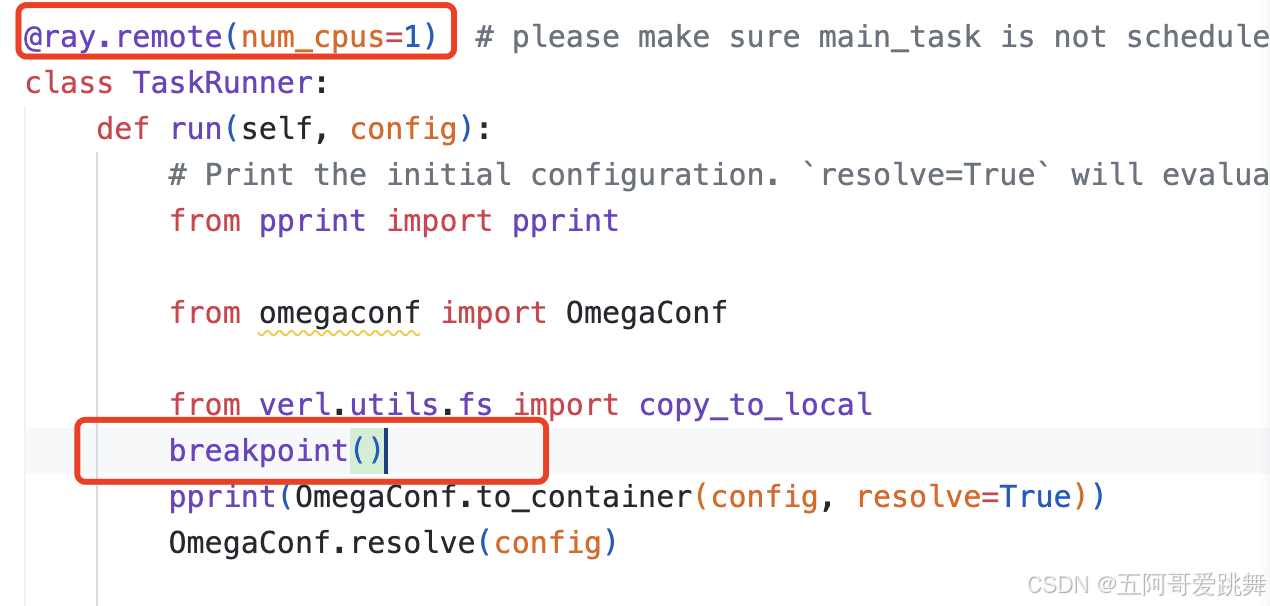
设置调试启动参数
在代码中需要调试的地方设置breakpoint()
⚠️注意:添加断点位置的函数/类,必须有@ray.remote()装饰器,例如:
然后直接用bash启动sh脚本,脚本中用python调用,即可,可以用如下代码测试:
bash examples/grpo_trainer/run_qwen3-0.6b.sh
插件自动捕捉到断点之后就可以像正常python程序一样调试了:
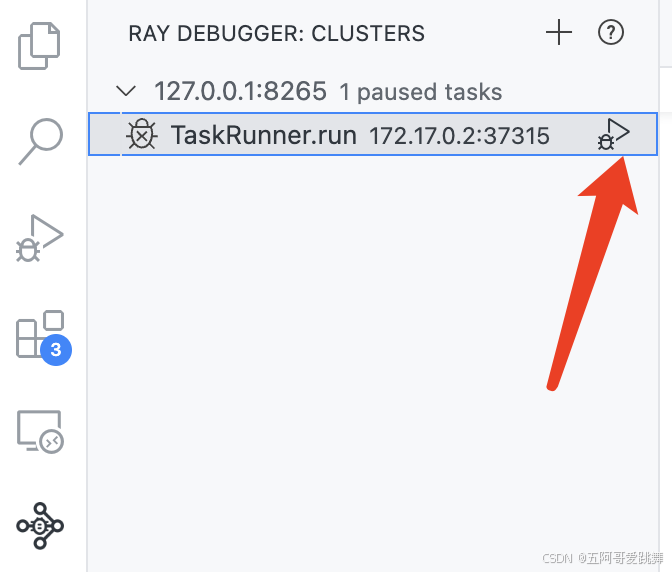
在非@ray.remote装饰位置的设置的breakpoint()会在命令行进行pdb调试。
Verl example中的数据预处理
在Verl example中提供了许多有用的小例子,包括从数据处理到一些训练的例子。
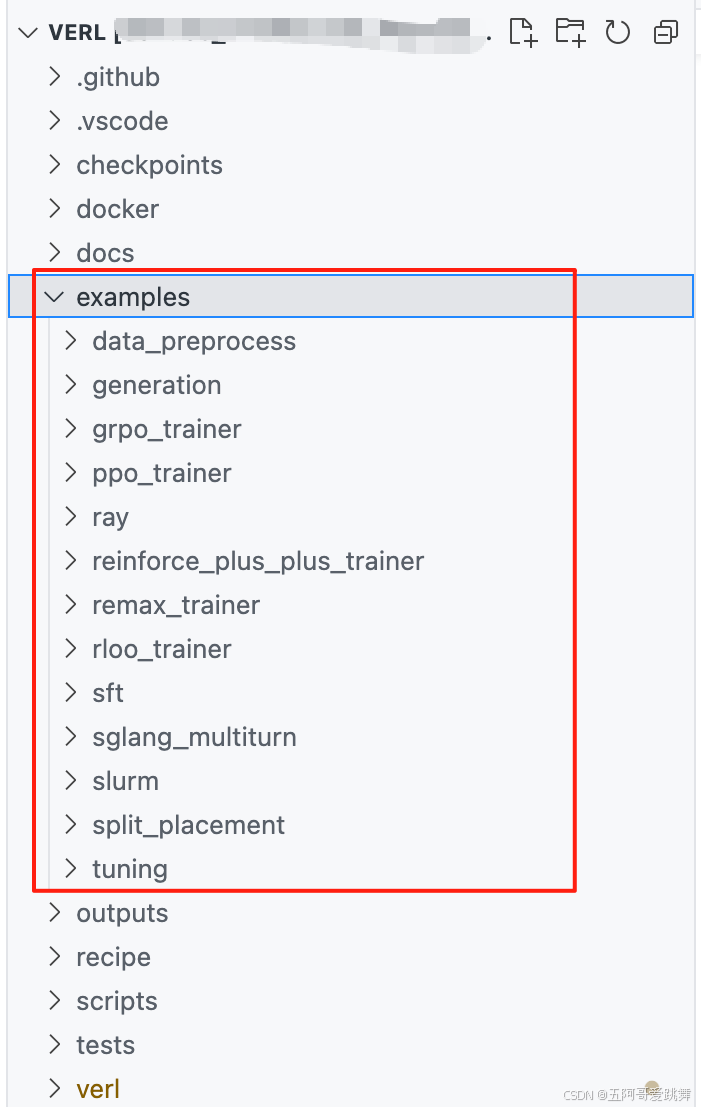
具体包含的数据处理example如下:
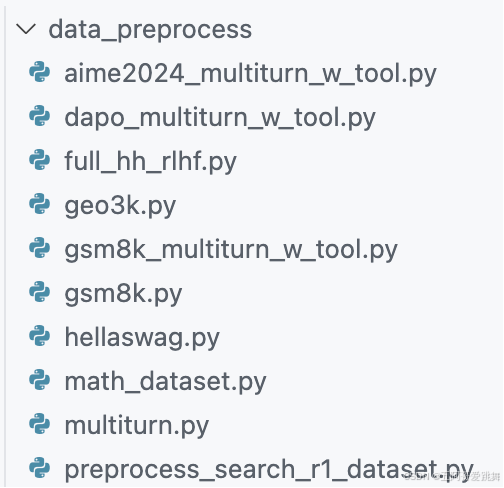
其中,例如gsm8k.py针对GSM8k数据集进行预处理。
https://verl.readthedocs.io/en/latest/start/quickstart.html
通常使用parquet格式的原因是加载更快,当前默认原始数据集就是这个数据格式,因此不用修改。
main_ppo.py主文件架构分析
该文件基本定义了训练的最简化的流程,是一个基于 Hydra + Ray 驱动的 PPO/GRPO 类强化学习训练入口。它把「资源管理、进程/角色划分、数据集与采样、奖励函数、多种分布式策略(FSDP / Megatron / vLLM)」这些零件拼在一起,然后交给 RayPPOTrainer 去跑。
首先是基于Hydra的配置
yaml文件中主要包括如下配置:
data: # 数据
actor_rollout_ref::#核心配置,包括model、actor、ref、rollout、
reward_model:: #奖励模型,用于计算输出样本及时分数
critic: #批评家模型,用于估计期望回报
custom_reward_function: # 自定义奖励模型
trainer: # 训练器
25.06 - update&plan
多轮强化学习训练支持
异步引擎,辅助LLM多轮对话强化学习优化,解决之前同步方案的效率问题;

MoE模型训练支持
优化Megatron
采用多node推理
参数切片管理,用于megatron和inference引擎。

planned



















 6932
6932

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











