






TransUnet官方代码训练自己数据集
一、制作自己的分割数据集
参考:安装打标签工具并打标签,在我的博客里自行检索即可
具体的标注软件使用的是labelme,安装过程和使用方法大家可以看链接给出的另一篇文章,我这里把主要流程说一下。
- 用labelme对数据进行标注,每张图片标注保存后会对应生成一个.json文件,如下图

- 编写代码利用json文件生成标签图
- 最后将图像image和标签图label使用相同的命名保存到两个文件夹中
- 另存一份上述文件夹,并添加后缀deleted,即image_deleted和label_deleted,然后根据label_deleted逐个删除不需要的图片,再利用代码根据label_deleted中删除后的图片列表来删除image_deleted,从而生成一组匹配的图片和标签。
二、下载官方TransUnet代码并加载自己的数据
1. 首先下载官方代码并解压
代码地址如下:https://github.com/Beckschen/TransUNet
https://github.com/Beckschen/TransUNet
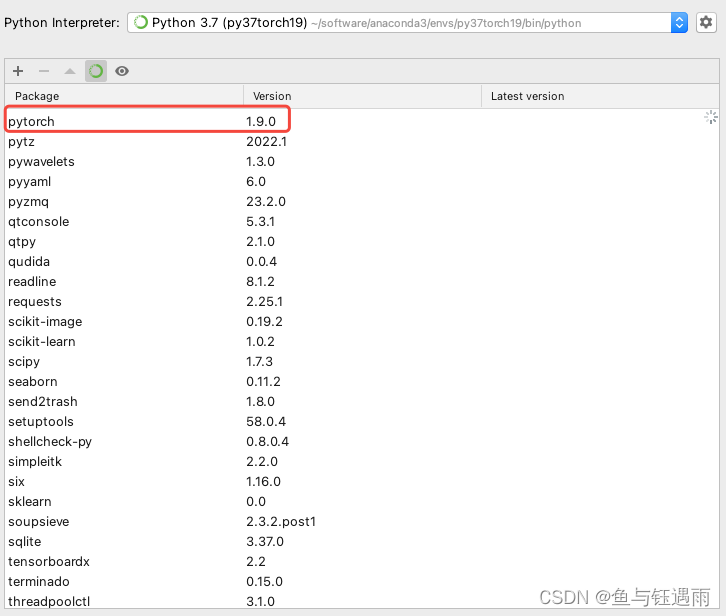
2. 配置Conda的pytroch环境
本次测试使用的环境是python 3.7.5 torch 1.9.0
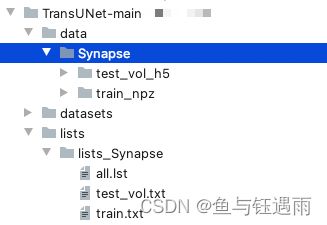
程序文件架构如下:
3. 制备TransUnet所需数据
由于TransUnet源码所需的数据格式为npz,因此需要通过代码首先将数据转换为npz格式。
在根目录下创建prepareddata文件夹,并在其中创建image_data3_crop_deleted和label_data3_crop_deleted文件夹、以及图像转化工具getnpz_test.py和getnpz_train.py 还有列表生成工具write_test_txt.py和write_train_txt.py
首先,转换代码会把image和label成对生成在一个npz中,并将npz保存在根目录的 data/Synapse/test_vol_h5/文件夹下。
‘…/data/Synapse/test_vol_h5/’
这里,我们默认通过getnpz_test.py和getnpz_train.py对全部的样本生成到Synapse文件夹下,不进行训练集和测试集的划分操作。 交给后面的txt列表生成。
测试集npz生成代码如下:
import glob
import numpy as np
import cv2
import logging
import pdb
import logging
import os
import sys
from PIL import Image
import torchvision.transforms as transforms
def npz():
#配置日志文件
exp = 'test_dataname'
log_folder = './datacreate_log'
os.makedirs(log_folder, exist_ok=True)
logging.basicConfig(filename=log_folder + '/'+exp+".txt", level=logging.INFO, format='[%(asctime)s.%(msecs)03d] %(message)s', datefmt='%H:%M:%S')
logging.getLogger().addHandler(logging.StreamHandler(sys.stdout))
#原图像路径
path = '/Users/XXX/Documents/codespace/TransUNet-main-xxx-data3/xxxpreparedata/image_data3_crop_deleted/*.png'
#项目中存放训练所用的npz文件路径
# path2 = '../data/Synapse/train_npz/'
path2 = '../data/Synapse/test_vol_h5/'
print(glob.glob(path))
for i,img_path in enumerate(glob.glob(path)):
#读入图像
image = cv2.imread(img_path) # cv2读图片,读进来默认是BGR格式的
image = cv2.cvtColor(image,cv2.COLOR_BGR2RGB) # BGR转RGB格式 三通道
# image = cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
#读入标签
# print(img_path)
# label_path = img_path.replace('images','labels')
label_path = img_path.replace('image_data3_crop_deleted','label_data3_crop_deleted')
# flags: 标志位, 表示读取数据的格式,读取彩色可以设为cv2.IMREAD_COLOR(flags=1)
# ,读取灰度图像设为cv2.IMREAD_GRAYSCALE(flags=0),读取原始图像设为cv2.IMREAD_UNCHANGED(flags=-1)。
label = cv2.imread(label_path,flags=0) # 读取灰度图像(0-255)
# pdb.set_trace()
#将非目标像素设置为0
label[label!=38]=0 #根据你自己的数据修改,这里我只有labelme标注的一类
#将目标像素设置为1
label[label==38]=1
#保存npz
#image:(256, 256, 3) label:(256,256)
np.savez(path2+str(i),image=image,label=label) #三通道的图,单通道的标签
# print('------------',i)
logging.info('test'+img_path+'----'+str(i))
# 加载npz文件
# data = np.load(r'G:\dataset\Unet\Swin-Unet-ori\data\Synapse\train_npz\0.npz', allow_pickle=True)
# image, label = data['image'], data['label']
print('ok')
npz()
报错:
FileNotFoundError: [Errno 2] No such file or directory: '../data/Synapse/test_vol_h5/0.npz'
说明我们需要在Synapse下手动创建data/test_vol_h5这个文件夹
再次运行结束后,显示一个OK和所有生成图像的对应标签列表,则说明运行完成。其中,原图片文件和标签的名字会被修改后存入npz,因此,我们设计了一个记录器来存储npz文件和标签文件的对应关系。 文件位置在datacreate_log/train_dataname.txt
然后是运行getnpz_train.py,
import glob
import numpy as np
import cv2
import logging
import pdb
import logging
import os
import sys
from PIL import Image
import torchvision.transforms as transforms
def npz():
#配置日志文件
exp = 'train_dataname'
log_folder = './datacreate_log'
os.makedirs(log_folder, exist_ok=True)
logging.basicConfig(filename=log_folder + '/'+exp+".txt", level=logging.INFO, format='[%(asctime)s.%(msecs)03d] %(message)s', datefmt='%H:%M:%S')
logging.getLogger().addHandler(logging.StreamHandler(sys.stdout))
#原图像路径
path = '/Users/XXX/Documents/codespace/TransUNet-main-xxx-data3/xxxpreparedata/image_data3_crop_deleted/*.png'
#项目中存放训练所用的npz文件路径
path2 = '../data/Synapse/train_npz/'
print(glob.glob(path))
for i,img_path in enumerate(glob.glob(path)):
#读入图像
image = cv2.imread(img_path) # cv2读图片,读进来默认是BGR格式的
image = cv2.cvtColor(image,cv2.COLOR_BGR2RGB) # BGR转RGB格式 三通道
# image = cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
#读入标签
# print(img_path)
# label_path = img_path.replace('images','labels')
label_path = img_path.replace('image_data3_crop_deleted','label_data3_crop_deleted')
# flags: 标志位, 表示读取数据的格式,读取彩色可以设为cv2.IMREAD_COLOR(flags=1)
# ,读取灰度图像设为cv2.IMREAD_GRAYSCALE(flags=0),读取原始图像设为cv2.IMREAD_UNCHANGED(flags=-1)。
label = cv2.imread(label_path,flags=0) # 读取灰度图像(0-255)
# pdb.set_trace()
#将非目标像素设置为0
label[label!=38]=0 #根据你自己的数据修改,这里我只有labelme标注的一类
#将目标像素设置为1
label[label==38]=1
#保存npz
#image:(256, 256, 3) label:(256,256)
np.savez(path2+str(i),image=image,label=label) #三通道的图,单通道的标签
# print('------------',i)
logging.info('train'+img_path+'----'+str(i))
# 加载npz文件
# data = np.load(r'G:\dataset\Unet\Swin-Unet-ori\data\Synapse\train_npz\0.npz', allow_pickle=True)
# image, label = data['image'], data['label']
print('ok')
npz()
仍然报
FileNotFoundError: [Errno 2] No such file or directory: '../data/Synapse/train_npz/0.npz'
因此需要手动创建文件夹data/Synapse/train_npz/
对应的列表信息也保存在datacreate_log/train_dataname.txt中;
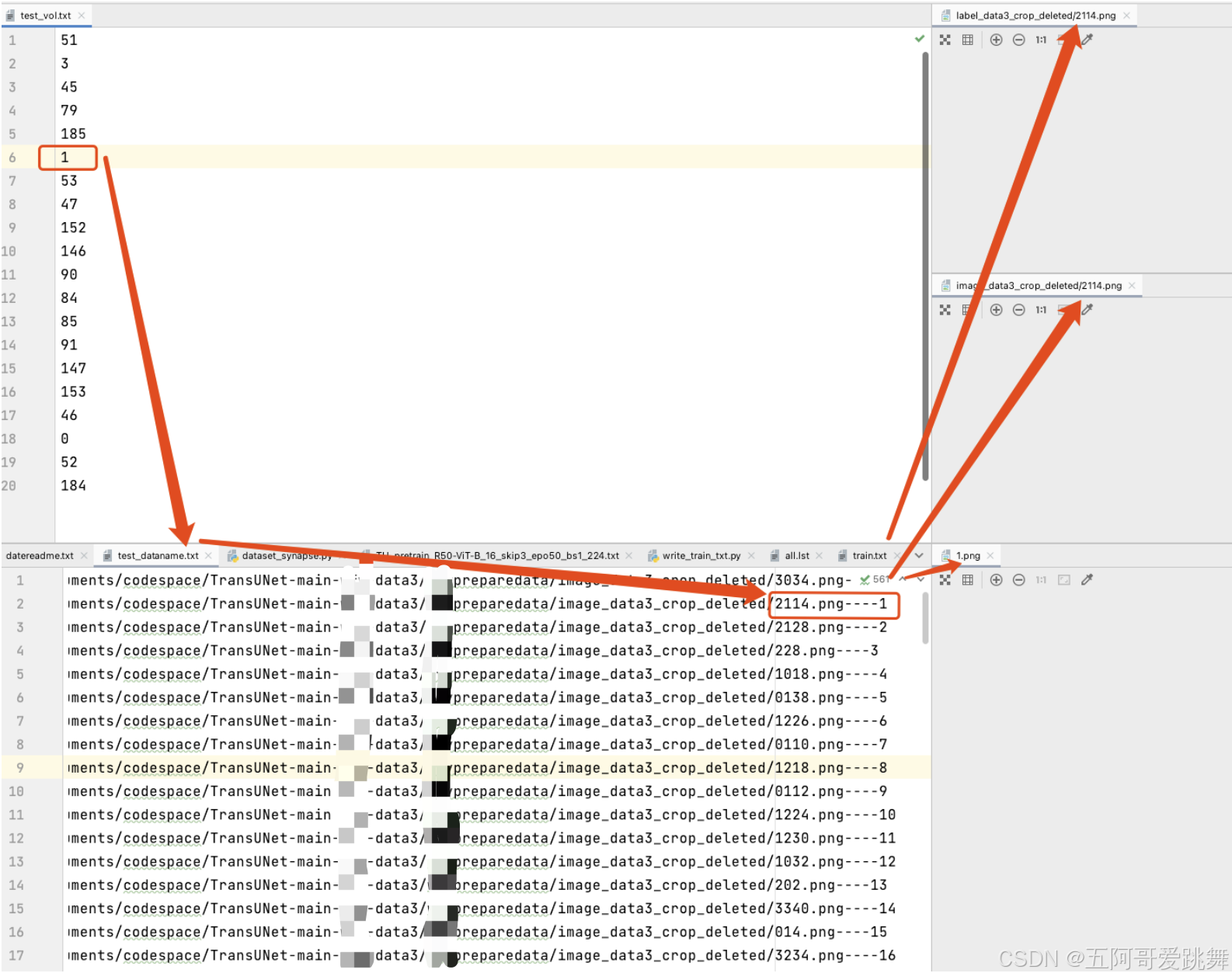
对比方式为:
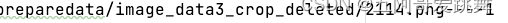
这里说明,2114.png对应1.npz。也就是,test_vl.txt中的索引6下的1.npz对应2114.png
4. 生成数据列表
我们可以看到,原文件中需要的数据已经准备好了,但test_vol.txt以及train.txt中的内容,还是作者给出的,需要替换掉;正常我们是直接利用test_vol_h5和train_npz中的文件名来生成,但是,我们在上一步并没有对数据进行划分,因此在这里生成list的时候,就需要进行划分了。因为最终程序也是通过list来读文件的,上一步不划分并不会产生影响。
我们,找到train.txt和test_vol.txt,手动将文件里面的内容清空(train.txt不清空也行,后面的代码会直接将这个文件覆盖掉),split_data.py这个文件直接无视。自己写一个函数读取train_npz中所有的文件名称,然后将文件名称写入train.txt文件,一个名称一行,如下图所示。同理可完成test_vol.txt文件制作。(这里test文件,直接从train.txt中选一些复制到test_vol.txt中即可,无需代码生成)
我们在preparedata文件夹下创建wtire_train_txt.py
import glob
def write_name():
#npz文件路径
files = glob.glob('../data/Synapse/train_npz/*.npz')
# files = glob.glob('../data/Synapse/test_vol_h5/*.npz')
#txt文件路径
f = open('../lists/lists_Synapse/train.txt','w')
# f = open('../lists/lists_Synapse/test_vol.txt','w')
for i in files:
name = i.split('/')[-1]
name = name[:-4]+'\n'
f.write(name) # 按照读取文件的名字,存到train.txt列表中,然后从里面复制出来0.1样本,现在问题是,文件名和图片怎么对应
write_name()

从train.txt中选10%作为test_vol.txt,这里已经筛选了。
数据集制作完毕!!!代码会先去train.txt文件中读取训练样本的名称,然后根据名称再去train_npz文件夹下读取npz文件。所以每一步都很重要,必须正确!
三、TransUnet模型训练
1.下载官方预训练权重
预训练权重官方下载地址
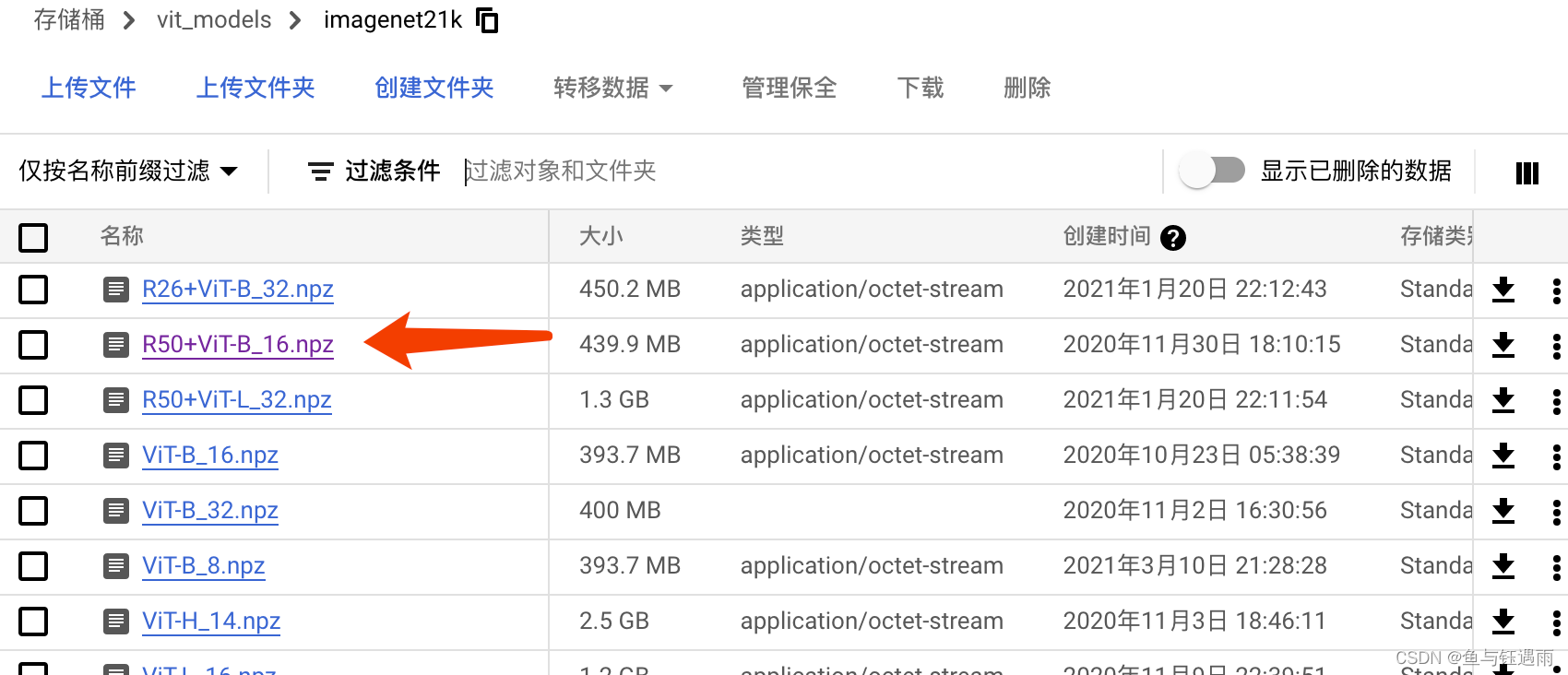
下载上图所示这个,下载后放到如下文件夹中,这组文件夹都需要我们自己创建:
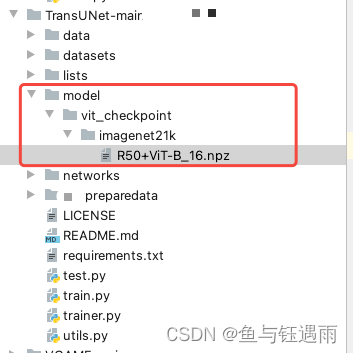
2.修改数据读取文件的代码
找到datasets/dataset_synapse.py文件中的Synapse_dataset类,修改__getitem__函数。
class Synapse_dataset(Dataset):
def __init__(self, base_dir, list_dir, split, transform=None):
self.transform = transform # using transform in torch!
self.split = split
self.sample_list = open(os.path.join(list_dir, self.split+'.txt')).readlines()
self.data_dir = base_dir
def __len__(self):
return len(self.sample_list)
def __getitem__(self, idx):
if self.split == "train":
slice_name = self.sample_list[idx].strip('\n')
data_path = self.data_dir + "/" + slice_name + '.npz'
data = np.load(data_path)
image, label = data['image'], data['label']
else:
slice_name = self.sample_list[idx].strip('\n')
data_path = self.data_dir + "/" + slice_name + '.npz'
data = np.load(data_path)
image, label = data['image'], data['label']
image = torch.from_numpy(image.astype(np.float32))
image = image.permute(2, 0, 1)
label = torch.from_numpy(label.astype(np.float32))
sample = {'image': image, 'label': label}
if self.transform:
sample = self.transform(sample)
sample['case_name'] = self.sample_list[idx].strip('\n')
return sample
找到找到datasets/dataset_synapse.py文件中的RandomGenerator类,修改__call__函数。
class RandomGenerator(object):
def __init__(self, output_size):
self.output_size = output_size
def __call__(self, sample):
image, label = sample['image'], sample['label']
if random.random() > 0.5:
image, label = random_rot_flip(image, label)
elif random.random() > 0.5:
image, label = random_rotate(image, label)
x, y,_ = image.shape
if x != self.output_size[0] or y != self.output_size[1]:
image = zoom(image, (self.output_size[0] / x, self.output_size[1] / y,1), order=3) # why not 3?
label = zoom(label, (self.output_size[0] / x, self.output_size[1] / y), order=0)
image = torch.from_numpy(image.astype(np.float32))
image = image.permute(2,0,1)
label = torch.from_numpy(label.astype(np.float32))
sample = {'image': image, 'label': label.long()}
return sample
至此,与数据相关的代码都改好啦。
3.调整训练参数
- train.py文件中的修改部分

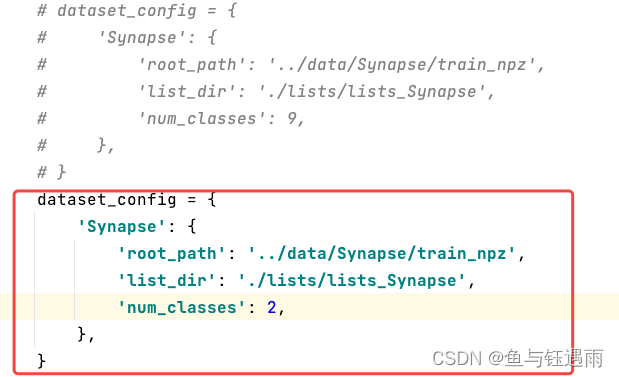

- trainer.py文件中的修改部分
其中trainer.py中的num_worker=8可以不改,只要你的设备支持的话。

OK! 至此 模型的修改基本上就完成了,可以开始训练啦,但是训练的过程中,大多数人会出错,本文第四部分会列举我在实验过程中遇到过的错误以及解决方案,看看下面会不会有和你的相似的错误。
运行代码train.py,在你自己的设备上开始查错纠错吧!!!!
## 集群运行代码
略
四、开始训练遇到的bug以及修改记录
注意,每个人的基础实验环境不同,遇到的bug也各不相同。并不是每个都会遇到,也并不是出了这里记录的没有别的bug,有其他bug大家可以在评论区讨论。
1. 缺失包
- No module named ‘ml_collections’
pip install ml_collections
- No module named ‘tensorboardX’
pip install tensorboardX
- No module named ‘medpy’
pip install medpy
2. 没有Cuda环境
AssertionError: Torch not compiled with CUDA enabled
修改原代码中的.cuda()部分,按照如下内容的例子全部改掉,有多处
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 改
net = ViT_seg(config_vit, img_size=args.img_size, num_classes=config_vit.n_classes).to(device) #改
第一处:
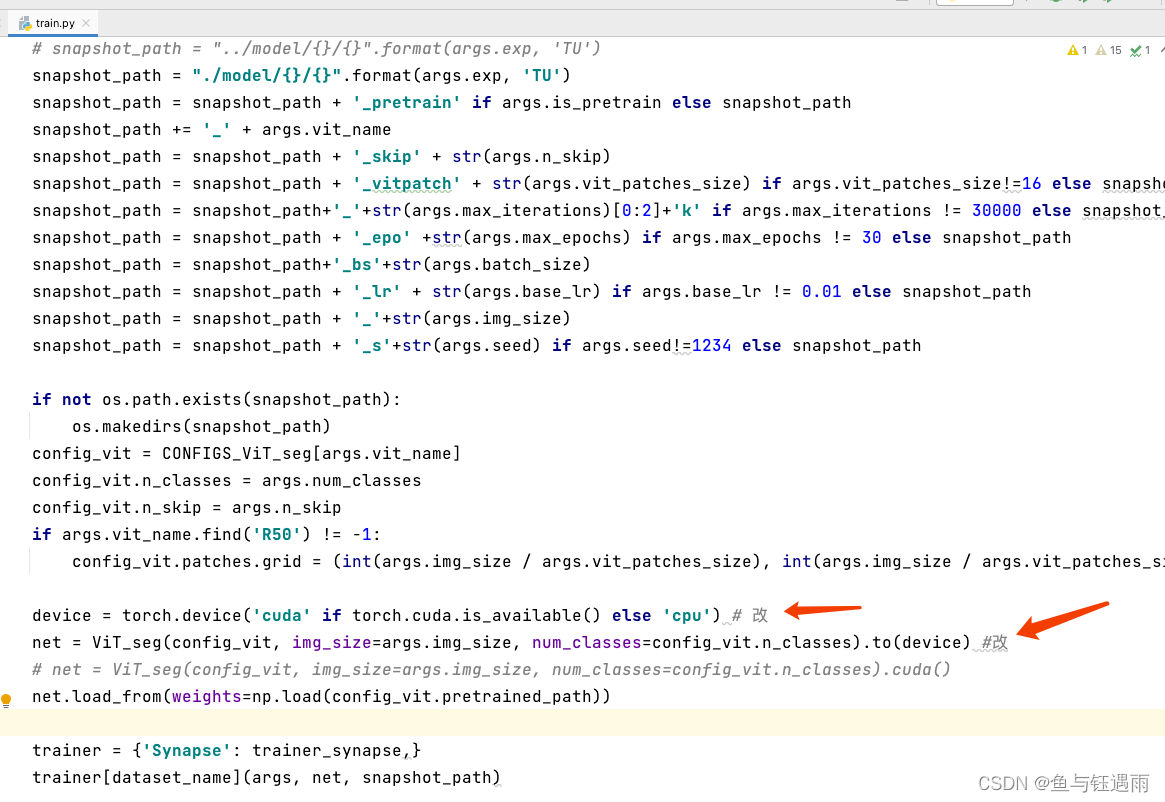
第二处:

3. FileNotFoundError: [Errno 2] No such file or directory: ‘…/model/vit_checkpoint/imagenet21k/R50+ViT-B_16.npz’
FileNotFoundError: [Errno 2] No such file or directory: ‘…/model/vit_checkpoint/imagenet21k/R50+ViT-B_16.npz’
解决方案:在vit_seg_configs.py里面把路径修改一下,就是前面两个点…/改成一个点./ ; 注意,找对方法,别乱找;
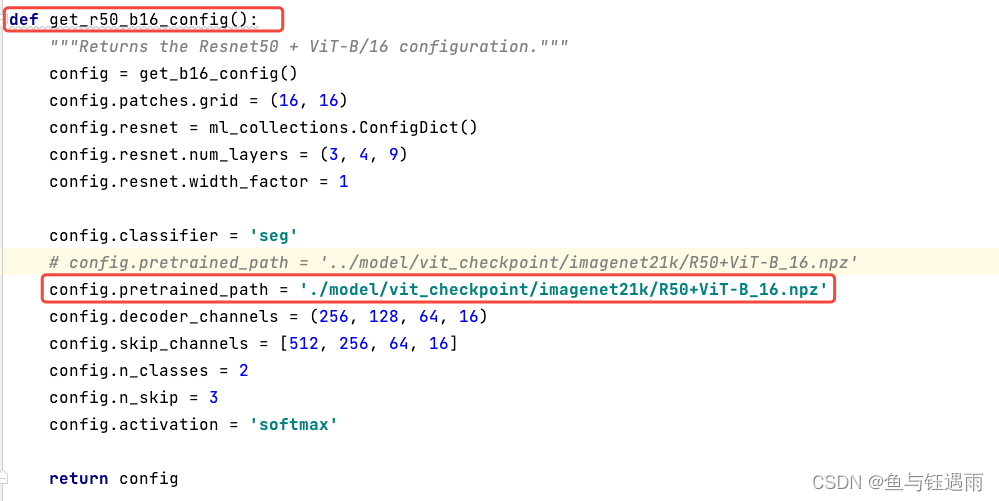
五、训练模型
当出现下面的文字或者界面的时候,就说明已经跑起来了。
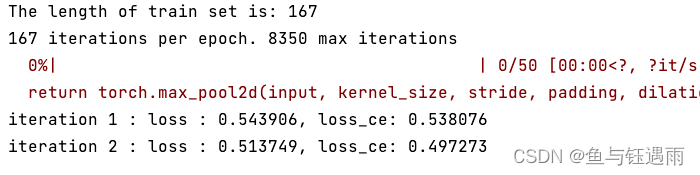
我们慢慢等,看看会不会出问题,如果没问题,下面继续进行测试部分;
哎发现问题了。
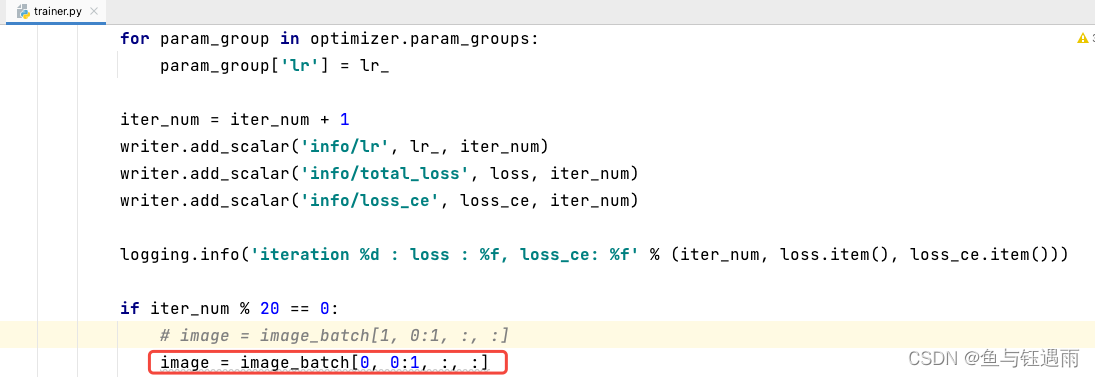
IndexError: index 1 is out of bounds for dimension 0 with size 1
出现该问题的原因是,主要原因就是数据(样本)的个数是奇数,而batch_size开的偶数,因此[1]这个batch_size的位置有问题了,越界了,应该改成0。
修改的部分如下:
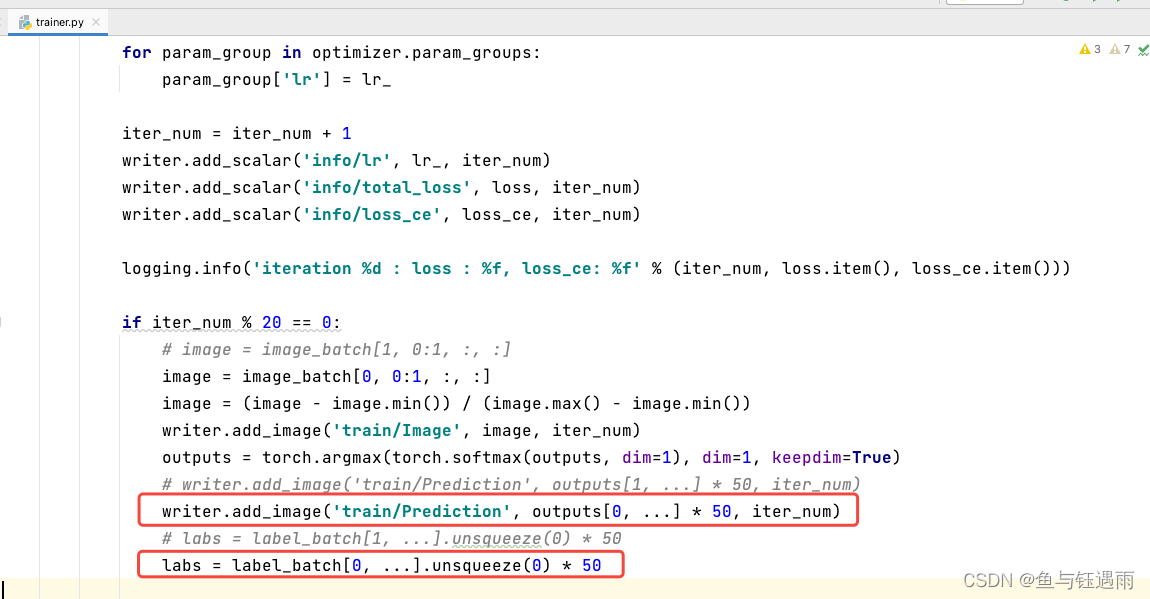
模型训练完成后,会按照代码中的设置保存训练模型的参数文件,和训练日志:
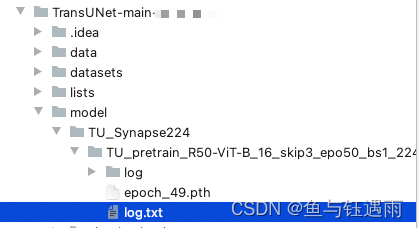
默认是保存最后一次的训练结果,和每50个epoch保存一次的训练结果。
六、预测
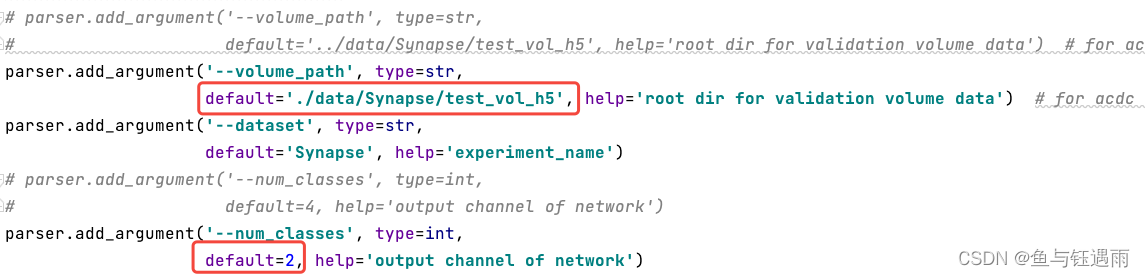
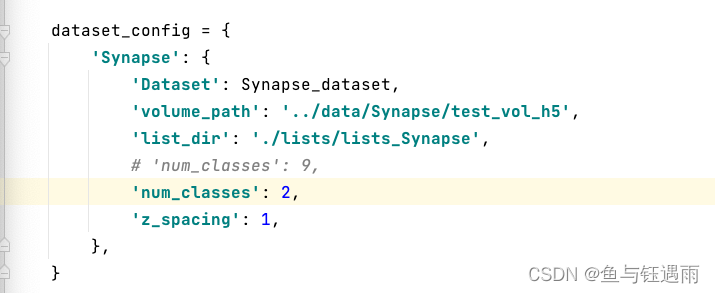
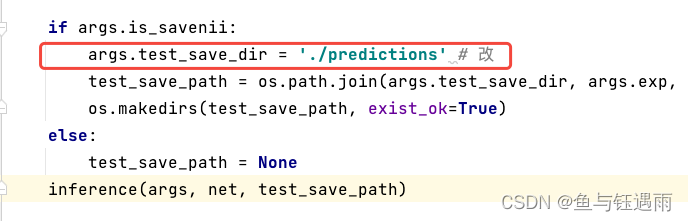
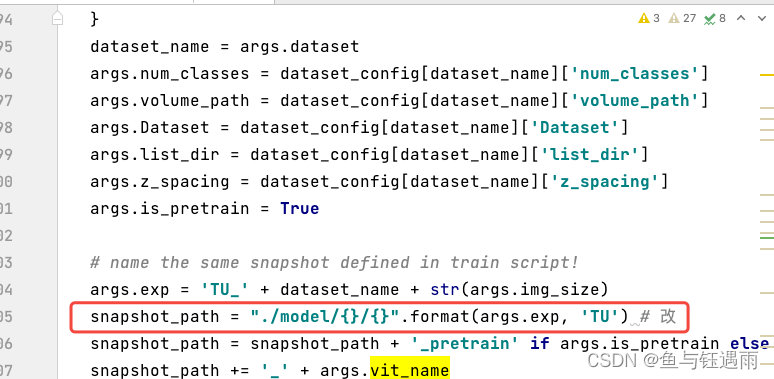
- 修改test.py文件


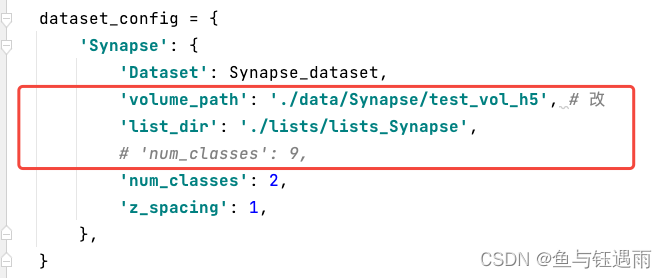

- 修改utils.py文件
def test_single_volume(image, label, net, classes, patch_size=[256, 256], test_save_path=None, case=None, z_spacing=1):
image, label = image.squeeze(0).cpu().detach().numpy(), label.squeeze(0).cpu().detach().numpy()
_,x, y = image.shape
if x != patch_size[0] or y != patch_size[1]:
#缩放图像符合网络输入
image = zoom(image, (1,patch_size[0] / x, patch_size[1] / y), order=3)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
input = torch.from_numpy(image).unsqueeze(0).float().to(device)
net.eval()
with torch.no_grad():
out = torch.argmax(torch.softmax(net(input), dim=1), dim=1).squeeze(0)
out = out.cpu().detach().numpy()
if x != patch_size[0] or y != patch_size[1]:
#缩放图像至原始大小
prediction = zoom(out, (x / patch_size[0], y / patch_size[1]), order=0)
else:
prediction = out
metric_list = []
for i in range(1, classes):
metric_list.append(calculate_metric_percase(prediction == i, label == i))
if test_save_path is not None:
a1 = copy.deepcopy(prediction)
a2 = copy.deepcopy(prediction)
a3 = copy.deepcopy(prediction)
a1[a1 == 1] = 0
a2[a2 == 1] = 255
a3[a3 == 1] = 0
a1 = Image.fromarray(np.uint8(a1)).convert('L')
a2 = Image.fromarray(np.uint8(a2)).convert('L')
a3 = Image.fromarray(np.uint8(a3)).convert('L')
prediction = Image.merge('RGB', [a1, a2, a3])
prediction.save(test_save_path+'/'+case+'.png')
return metric_list
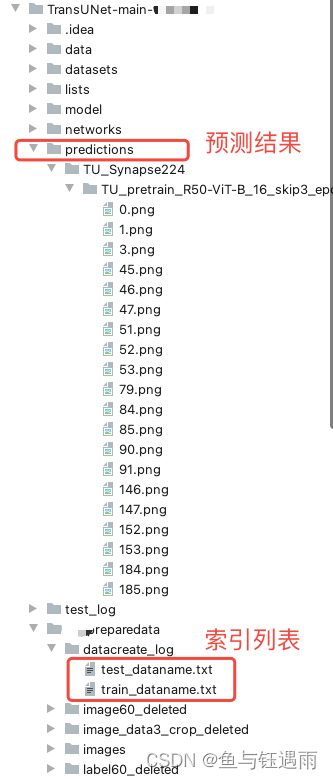
最终根据预测结果和索引列表,查原图和标签,做对比。 也可用来组合生成掩码图。



















 3970
3970











 到【灌水乐园】发言
到【灌水乐园】发言









