 HashMap深入解析
HashMap深入解析





 本文详细解析了HashMap在Java7和Java8中的底层实现原理,包括数组加链表结构和升级后的数组加链表加红黑树结构。探讨了HashMap的插入、删除操作,以及链表转红黑树的优化策略,旨在帮助开发者深入了解HashMap的工作机制。
本文详细解析了HashMap在Java7和Java8中的底层实现原理,包括数组加链表结构和升级后的数组加链表加红黑树结构。探讨了HashMap的插入、删除操作,以及链表转红黑树的优化策略,旨在帮助开发者深入了解HashMap的工作机制。
HashMap是Java中最常用的类之一,使用它的时候,有很多小的细节需要大家注意。下面通过他的原理和一些面试题目进行讲解。
Java7底层实现
java7中用 HashMap底层算法使用了数组加链表的结构
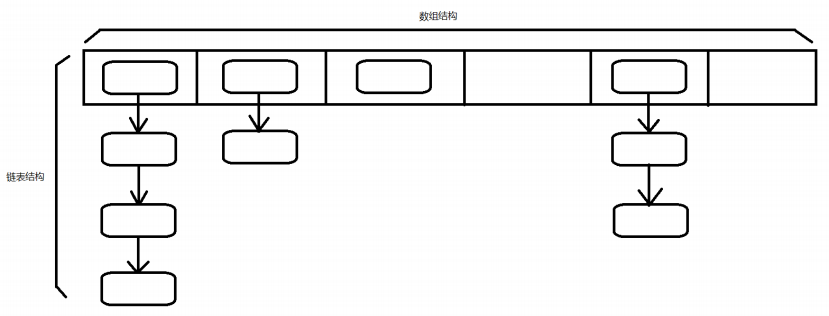
- 插入元素
计算待插入元素的hashcode值, 通过Hash算法, 算出此hashcode值在数组中对应下标, 然后查这个下标位置的链表, 没有的话直接插入, 如果有的话, 查询链表, 并与新元素equals 如果返回的都是false 则把新元素放在链表第一个位置上, 如果有返回true的, 则插入失败 - 数组扩容→加载因子
当HashMap中的元素个数超过数组大小(数组长度)*loadFactor(负载因子)时,就会进行数组扩容,loadFactor的默认值(DEFAULT_LOAD_FACTOR)是0.75,这是一个折中的取值。也就是说,默认情况下,数组大小为16,那么当HashMap中的元素个数超过16×0.75=12(这个值就是阈值或者边界值threshold值)的时候,就把数组的大小扩展为2×16=32,即扩大一倍,然后重新计算每个元素在数组中的位置,而这是一个非常耗性能的操作,所以如果我们已经预知HashMap中元素的个数,那么预知元素的个数能够有效的提高HashMap的性能。
进行扩容,会伴随着一次重新hash分配,并且会遍历hash表中所有的元素,是非常耗时的。在编写程序中,要尽量避免resize。
Java8底层实现
HashMap的内存结构进行升级 数组+链表+红黑树
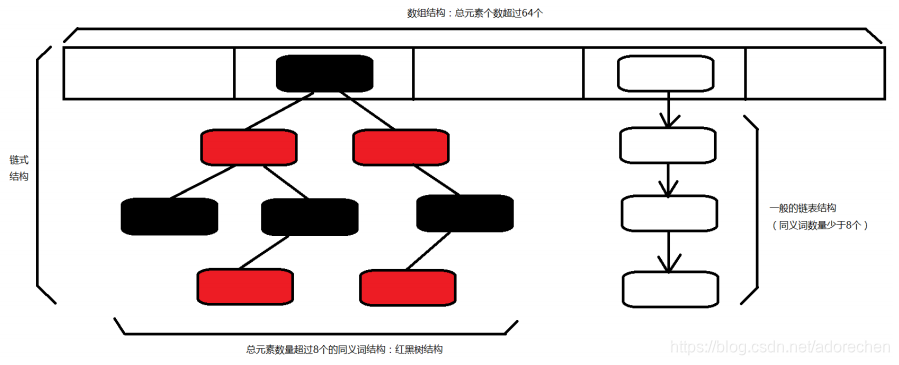
- *当前HashMap中元素总数超过64个, 且某一组链表中元素数量>=8个 则将此链表结构变成红黑树结构
- 红黑树结构牺牲了添加元素的性能, 增加了查找元素的效率
面试题目
1. 有1000_000条不同的记录需要插入到HashMap,怎样插入并说明理由?
这里考察的是capacity 和loadFactor, 当插入记录达到capacity*loadFactor时,需要对HashMap重新分配空间(rebuilt)和拷贝数据。所以对于需要插入很多数据时,比较好的方法是初始容量分配size*2的空间。
<p>As a general rule, the default load factor (.75) offers a good * tradeoff between time and space costs. Higher values decrease the * space overhead but increase the lookup cost (reflected in most of * the operations of the <tt>HashMap</tt> class, including * <tt>get</tt> and <tt>put</tt>). The expected number of entries in * the map and its load factor should be taken into account when * setting its initial capacity, so as to minimize the number of * rehash operations. If the initial capacity is greater than the * maximum number of entries divided by the load factor, no rehash * operations will ever occur.
import java.util.HashMap; /** * to insert 1000_000 elements into hashmap, test the impact of initial values on hashmap performance. * best performance: entity size * 2; * worst performance: default capacity size; */ public class HashMapTest { static final int SIZE = 1000_000; public static void main(String[] args) { testMap(0); testMap((int)(SIZE/0.75+16)); testMap(SIZE * 2); testMap(SIZE * 3); } public static void testMap(int capacity) { long start = System.currentTimeMillis(); HashMap<Integer, Integer> map; if (capacity <= 0) { map = new HashMap<>(); } else { map = new HashMap<>(capacity); } for (int i=0; i<SIZE; i++) { map.put(i, i); } System.out.println("capacity: " + capacity +", cost: "+ (System.currentTimeMillis() - start) + "ms"); } }
capacity: 0, cost: 119ms
capacity: 1333349, cost: 65ms
capacity: 2000000, cost: 32ms
capacity: 3000000, cost: 70ms
2. HashMap怎样删除满足条件的元素?
* <p>The iterators returned by all of this class's "collection view methods" * are <i>fail-fast</i>: if the map is structurally modified at any time after * the iterator is created, in any way except through the iterator's own * <tt>remove</tt> method, the iterator will throw a * {@link ConcurrentModificationException}. Thus, in the face of concurrent * modification, the iterator fails quickly and cleanly, rather than risking * arbitrary, non-deterministic behavior at an undetermined time in the * future.
/** * wrong deletion, throw out exception: java.util.ConcurrentModificationException */ public static void wrongDelete() { HashMap<Integer, Integer> map = new HashMap<>(10*2); for (int i=0; i<10; i++) { map.put(i, i); } for (Integer key: map.keySet()) { if (key % 2 == 0) { map.remove(key); } } }
/** * use keySet, values(), entrySet iterator.remove to delete key/value. */ public static void rightDelete() { HashMap<Integer, Integer> map = new HashMap<>(10*2); for (int i=0; i<10; i++) { map.put(i, i); } // use iterator.remove to remove key and value Iterator<Integer> itr = map.keySet().iterator(); while (itr.hasNext()) { Integer key = itr.next(); if (key % 2 == 0) { itr.remove(); } } for (Integer key: map.keySet()) { System.out.println(key +"=" + map.get(key)); } }
3. Java8之前HashMap底层是怎样实现的?Java8又是怎样实现的?
Java8之前是数组+链表;
Java8是数组+链表+红黑树,链表size>=8时转化为红黑树。
4.为什么要进行链表转红黑树的优化?
比如某些人通过找到你的hash碰撞值,来让你的HashMap不断地产生碰撞,那么相同key位置的链表就会不断增长,当你需要对这个HashMap的相应位置进行查询的时候,就会去循环遍历这个超级大的链表,性能及其地下。java8使用红黑树来替代超过8个节点数的链表后,查询方式性能得到了很好的提升,从原来的是O(n)到O(logn)。
Tree bins (i.e., bins whose elements are all TreeNodes) are * ordered primarily by hashCode, but in the case of ties, if two * elements are of the same "class C implements Comparable<C>", * type then their compareTo method is used for ordering. (We * conservatively check generic types via reflection to validate * this -- see method comparableClassFor). The added complexity * of tree bins is worthwhile in providing worst-case O(log n) * operations when keys either have distinct hashes or are * orderable, Thus, performance degrades gracefully under * accidental or malicious usages in which hashCode() methods * return values that are poorly distributed, as well as those in * which many keys share a hashCode, so long as they are also * Comparable. (If neither of these apply, we may waste about a * factor of two in time and space compared to taking no * precautions. But the only known cases stem from poor user * programming practices that are already so slow that this makes * little difference.)
5. 为什么链表转化为红黑树的门槛是8?
查看java8 HashMap注释大意是:在hashcode随机分布时,链表长度和红黑树的出现概率复合泊松分布。在链表长度为8时,红黑树出现概率为百万分子6(非常小的概率)。
* Because TreeNodes are about twice the size of regular nodes, we * use them only when bins contain enough nodes to warrant use * (see TREEIFY_THRESHOLD). And when they become too small (due to * removal or resizing) they are converted back to plain bins. In * usages with well-distributed user hashCodes, tree bins are * rarely used. Ideally, under random hashCodes, the frequency of * nodes in bins follows a Poisson distribution * (http://en.wikipedia.org/wiki/Poisson_distribution) with a * parameter of about 0.5 on average for the default resizing * threshold of 0.75, although with a large variance because of * resizing granularity. Ignoring variance, the expected * occurrences of list size k are (exp(-0.5) * pow(0.5, k) / * factorial(k)). The first values are: * * 0: 0.60653066 * 1: 0.30326533 * 2: 0.07581633 * 3: 0.01263606 * 4: 0.00157952 * 5: 0.00015795 * 6: 0.00001316 * 7: 0.00000094 * 8: 0.00000006 * more: less than 1 in ten million
参考:
https://zhuanlan.zhihu.com/p/72296421
https://www.cnblogs.com/QingzeHe/p/11289971.html

















 4640
4640

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









