







 本文介绍了如何使用Hanlp工具包进行自然语言处理,包括分词、关键词提取、摘要提取、词库维护等操作,并提供了具体的方法签名和示例代码。
本文介绍了如何使用Hanlp工具包进行自然语言处理,包括分词、关键词提取、摘要提取、词库维护等操作,并提供了具体的方法签名和示例代码。
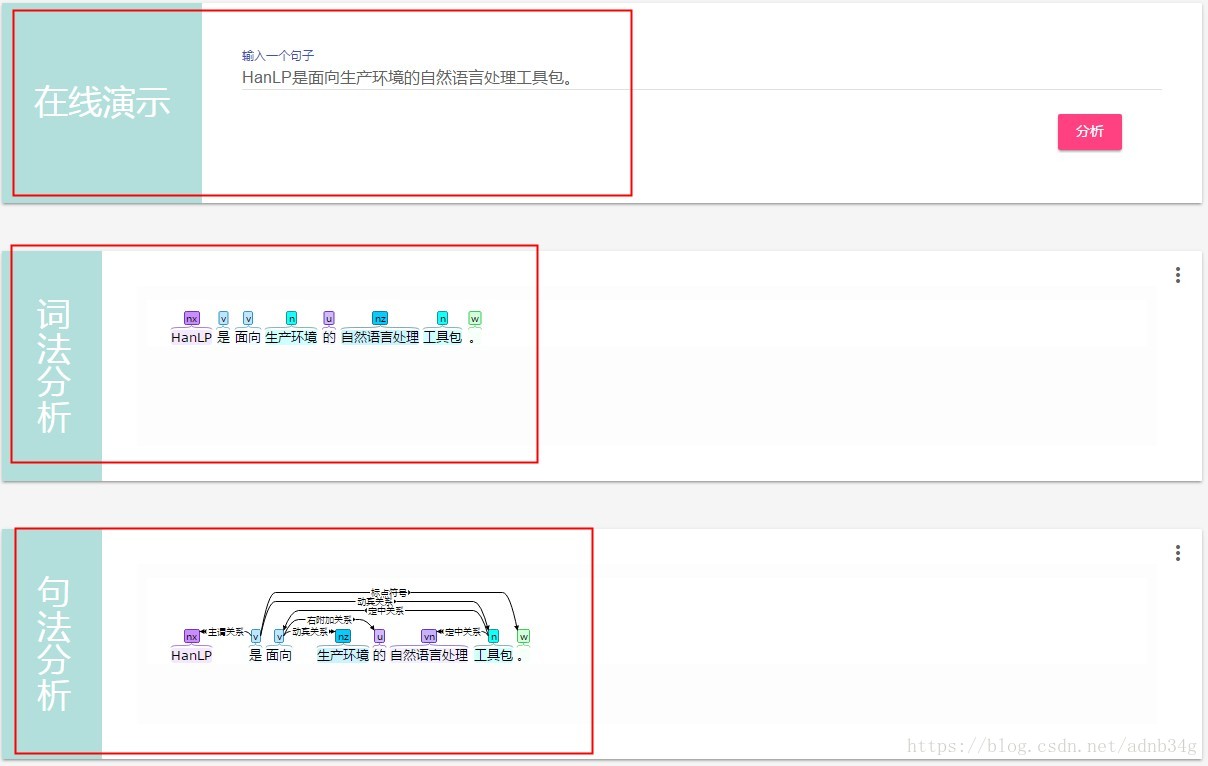
Hanlp是由一系列模型与算法组成的工具包,目标是普及自然语言处理在生产环境中的应用。Hanlp具备功能完善、性能高效、架构清洗、语料时新、可自定义的特点;提供词法分析(中文分词、磁性标注、命名实体识别)、句法分析、文本分类和情感分析等功能。
本篇将用户输入的语句根据词库进行分词、关键词提取、摘要提取、词库维护。
工具类名称:DKNLPBase
1、标准分词
方法签名:List<Term> StandardTokenizer.segment(String txt);
返回:分词列表。
签名参数说明:txt:要分词的语句。
范例:下例验证一段话第5个分词是阿法狗。
程序清单1
public void testSegment() throws Exception
{
String text = "商品和服务";
List<Term> termList = DKNLPBase.segment(text);
assertEquals("商品", termList.get(0).word);
assertEquals("和", termList.get(1).word);
assertEquals("服务", termList.get(2).word);
text = "柯杰解说“李世石VS阿法狗第二局” 结局竟是这样";
termList = DKNLPBase.segment(text);
assertEquals("阿法狗", termList.get(5).word); // 能够识别"阿法狗"
}
2、关键词提取
方法签名:List<String> extractKeyword(String txt,int keySum);
返回:关键词列表.
签名参数说明:txt:要提取关键词的语句,keySum要提取关键词的数量
范例:给出一段话提取一个关键词是“程序员”。
程序清单2
public void testExtractKeyword() throws Exception
{
String content = "程序员(英文Programmer)是从事程序开发、维护的专业人员。" +
"一般将程序员分为程序设计人员和程序编码人员," +
"但两者的界限并不非常清楚,特别是在中国。" +
&nb
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 815
815

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









