







 本文分享了神经网络编程中常见的误区,如梯度下降更新规则的理解,矩阵运算中的维度匹配问题,以及算法函数的设计思路,适合初学者借鉴。
本文分享了神经网络编程中常见的误区,如梯度下降更新规则的理解,矩阵运算中的维度匹配问题,以及算法函数的设计思路,适合初学者借鉴。
写前说明:本人代码水平不太好,初学神经网络知识。此文章主要为了记录自己错过的地方,也希望能帮助到有同样困难的同学。
1、梯度下降
def update(self, grads, lr):
self.W1 -= lr * grads["dW1"]
self.W2 -= lr * grads["dW2"]
self.b1 -= lr * grads["db1"]
self.b2 -= lr * grads["db2"]
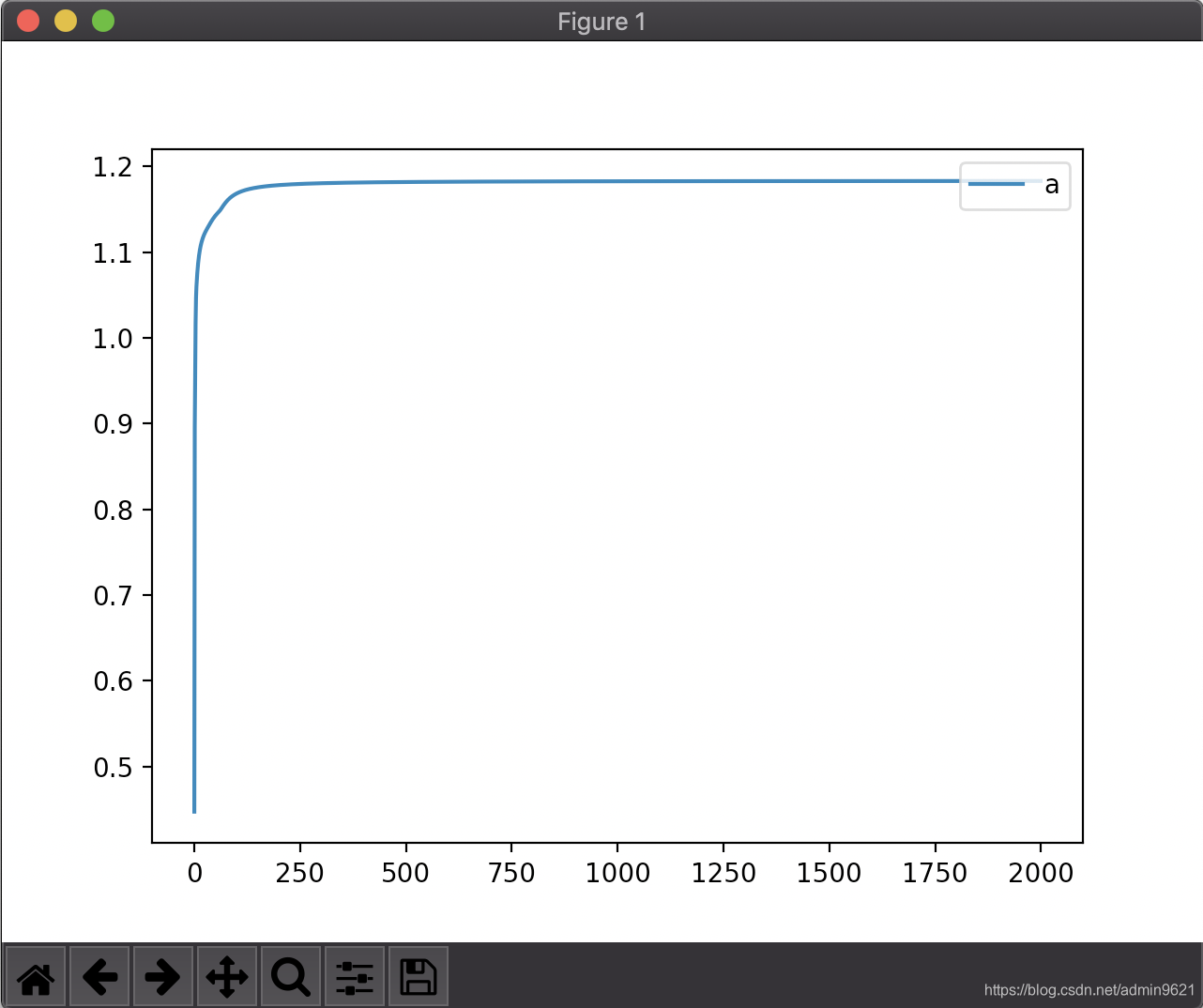
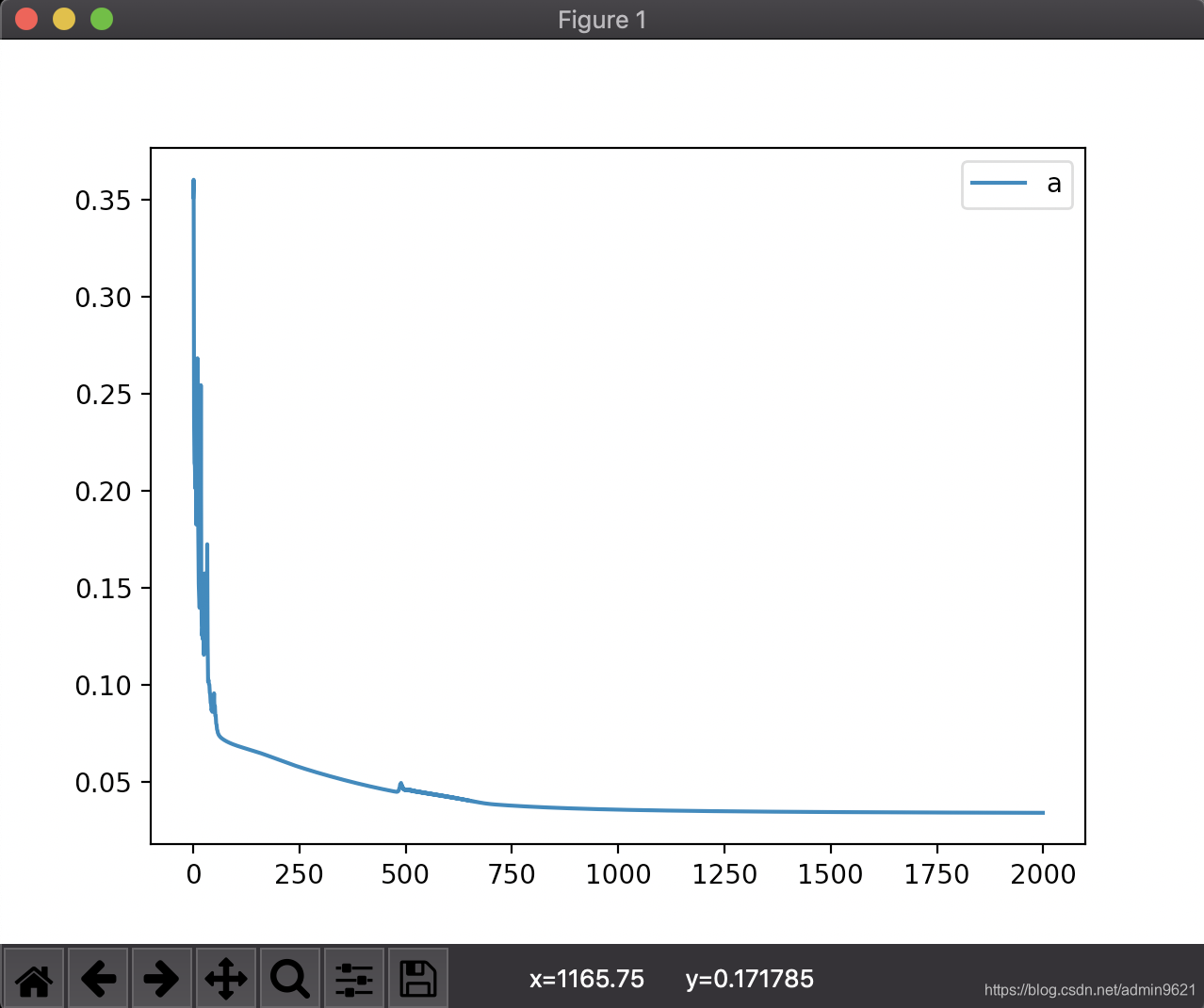
是“减号”啊,下降,不就是减号么!刚开始的我认为w+=dw,dw可以通过计算得出可正可负,所以写正负没有关系。我的天,所以我得出的一直是左图,呜呜呜,要哭了,咋弄咋不对,错误率还上升了。(我觉得这里可以数学分析一波,之后再)
2、关于矩阵、向量、标量的混合计算
****重要****
因为我出现了矩阵相乘时维度缺失;.T(转置)结果没有反应,后来发现是因为是[0,0,0]这种形式,是没有办法实用.T(转置);频繁使用.reshape()添加这个维度结果搞得乱七八槽,复用性极差。
shapes (1,3) and (1,3) not aligned: 3 (dim 1) != 1 (dim 0)
所以应该在一开始读取数据的时候,规整好。假如一个样本是三维的,如[0.1, 0.2, 0.3]。建议不要把samples直接复制成[[0.1, 0.2, 0.3],[0.3,0.4,0.6],……],因为取出第i个数据的时候,X_i = [0.1, 0.2, 0.3],很容易矩阵相乘的时候出问题。搞三个维度,x_0是样本宽度,x_1是样本长度,x_2是样本个数,方法如下
X.reshape(X.shape[0],1,X.shape[1])
把数据规整为[[[0.1, 0.2, 0.3]]\n,[[0.2, 0.3, 0.4]]\n],这样在取出第i个数据的时候X = [[0.1, 0.2, 0.3]],方便后续计算,很规整。
3、关于算法函数如何设计,设计哪些函数,哪些函数之间有调用关系,在询问过我朋友是否愿意公开代码后再补充,写的真的是赏心悦目。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









