




Canal增量同步MySQL数到Elasticsearch
调研背景
由于业务发展迅速,店铺商品分库越来越多(目前已有8个MySQL分库)且分库中表数据行数越来越大,大的表已经达到了5KW+,业务需要对商品模糊查询或根据其他字段查询,这些查询的字段很多在数据库中都没有索引,查询命中数据很慢(有些数据根本就查询不出来)且会给数据库库带来很大的压力.所以目前希望将MySQL中的商品数据实时同步到Elasticsearch,利用ES的强大搜索性能来满足我们当前的业务需求.
功能需求
- 首先需要一个稳定的能存储数据达到TB级别的ES集群;
- 其次需要将所有店铺商品分库中已有的所有数据初始化到ES集群;
- 最后后需要实时同步所有店铺商品分库中发生变更的记录到ES集群保证后续数据一致性;
技术需求
- 需要一个能迁移大数据量的方案用于第一次初始化;(后续调研)
- 需要一个能实时同步变更数据的方案保证数据一致性;(即本次调研的中间件Canal)
Canal简介
Canal是阿里巴巴开源的 基于数据库增量日志解析,提供增量数据订阅&消费的数据同步中间件,在阿里内部也有长时间的使用.
GitHub地址: https://github.com/alibaba/canal
Canal简介地址: https://github.com/alibaba/canal/wiki/Introduction
工作原理
mysql主备复制实现
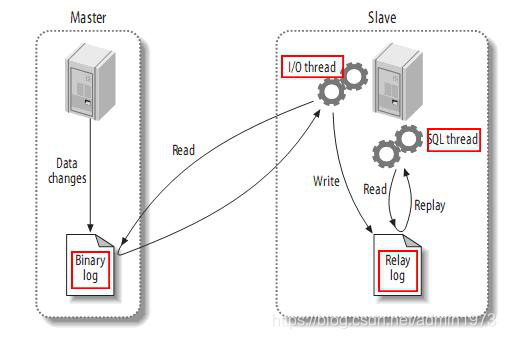
1.master将改变记录到二进制日志(binary log)中(这些记录叫做二进制日志事件,binary log events,可以通过show binlog events进行查看);从上层来看,复制分成三步:
2.slave将master的binary log events拷贝到它的中继日志(relay log);
3.slave重做中继日志中的事件,将改变反映它自己的数据。
canal的工作原理
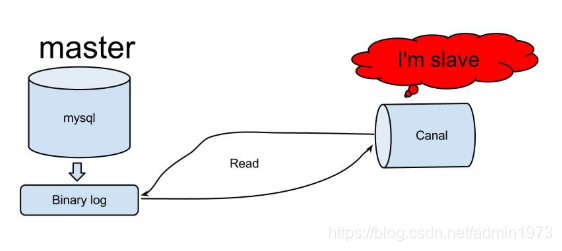
canal模拟mysql slave的交互协议,伪装自己为mysql slave,向mysql master发送dump协议原理相对比较简单:
- mysql master收到dump请求,开始推送binary log给slave(也就是canal)
- canal解析binary log对象(原始为byte流)
架构
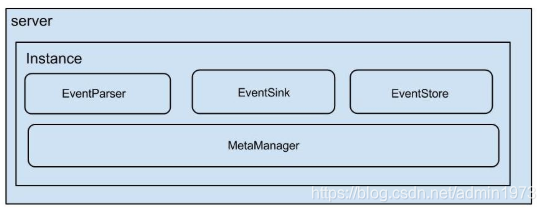
server代表一个canal运行实例,对应于一个jvm;说明:
- instance对应于一个数据队列 (1个server对应1..n个instance)
instance模块:
- eventParser (数据源接入,模拟slave协议和master进行交互,协议解析)
- eventSink (Parser和Store链接器,进行数据过滤,加工,分发的工作)
- e
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 855
855

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









