



RAG 是 "Retrieval-Augmented Generation" 的缩写,这是一种结合信息检索和生成模型的自然语言处理技术。RAG 模型通常用于提高生成模型在特定任务(如问答、对话生成等)中的性能。

1.大模型的缺陷
知识局限性:缺少垂直领域/非公开知识
知识时效性:训练周期长,成本高
幻觉问题:模型生成的内容与现实世界事实或用户输入不一致
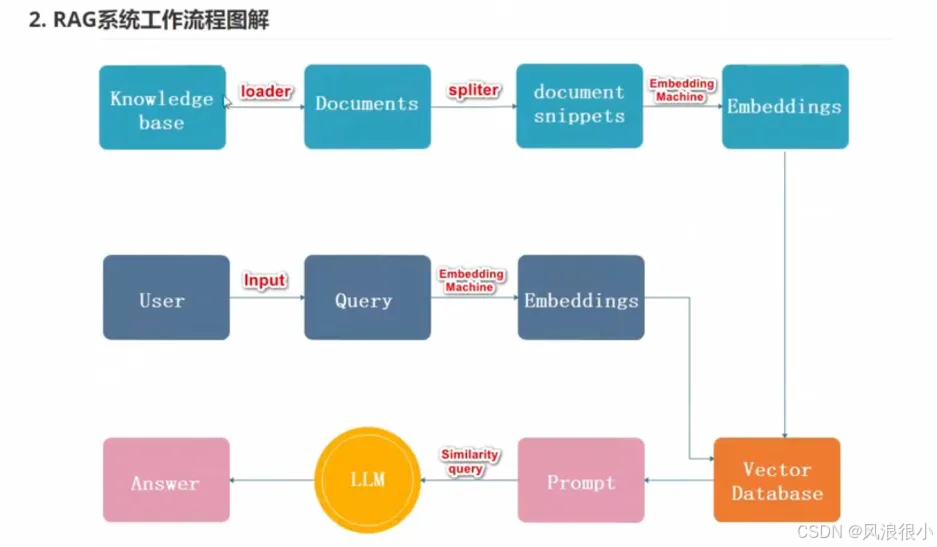
2.RAG系统工作流程图解:
3.向量检索
3.1 检索的方式
1.关键字搜索:通过用户输入的关键字来查找文本数据。
2.语义搜索:不仅考虑关键字的匹配,还考虑词汇之间的语义(文字,语音,语词...)关系,以提供更精准的搜索。
3.2向量与Embeddings(嵌入)的定义
1.向量:向量是一个具有大小和方向的数学对象,通常被表示为有序的数值列表。向量可以存在于任意维度中.
2.Embeddings(嵌入):嵌入是将高维数据映射到低维空间的技术,通常用于捕捉数据中的潜在关系和语义信息。嵌入在自然语言处理中特别常见,用于将单词、句子或其他离散数据表示为向量。
- 词嵌入(Word Embeddings):如Word2Vec、GloVe等模型,将单词转换为固定长度的向量,使得语义相似的单词在向量空间中彼此接近。这有助于在机器学习模型中进行文本分析和理解。
- 图像嵌入(Image Embeddings):在计算机视觉中,图像可以被转换为向量表示,以便进行分类和识别等任务。
嵌入的主要优点是能有效压缩数据维度,同时保留重要的结构和语义信息。通过这种方式,模型可以更好地理解和处理复杂的数据。
from openai import OpenAI
import os
api_key=os.getenv("OPENAI_API_KEY")
client=OpenAI(api_key=api_key)
# 参数一 =》 texts 是一个包含要获取嵌入表示的文本列表
# 参数二 =》 model 则是用来指定要使用的模型的名称
def get_embeddings(texts,model="text-embedding-3-large"):
# 创建一个嵌入向量,结果存储在data中
data =client.embeddings.create(input=texts,model=model).data
# 列表推导式
return [x.embedding for x in data]
if __name__ == '__main__':
test_query=["我爱你"]
vec=get_embeddings(test_query)
print("--------------------")
# "我爱你"文本嵌入表示的列表。
print(vec)
# "我爱你" 文本的嵌入表示
print(vec[0])
# "我爱你" 文本的嵌入表示的维度=3072
print(len(vec[0]))
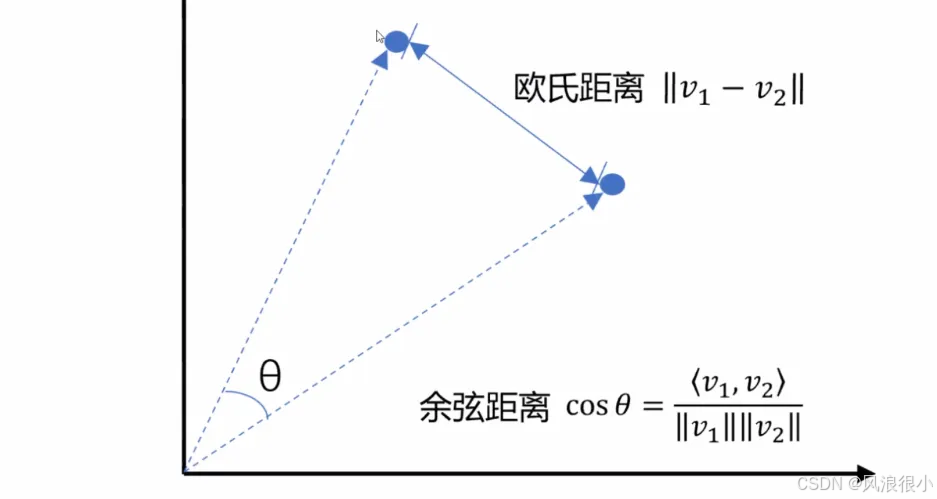
3.3向量间的相似的计算
1.欧式距离
2.余弦距离

















 2524
2524

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









