




 该博客探讨了使用单参数θ1进行梯度下降的情况,通过公式展示其成本函数的迭代过程。无论导数的正负,θ1都会收敛到最小值。当导数为负时,θ1增加;为正时,θ1减小。同时强调了调整学习率α的重要性,以确保算法在合理时间内收敛。在最小值处,导数为0,θ1更新为自身减去零,即保持不变。
该博客探讨了使用单参数θ1进行梯度下降的情况,通过公式展示其成本函数的迭代过程。无论导数的正负,θ1都会收敛到最小值。当导数为负时,θ1增加;为正时,θ1减小。同时强调了调整学习率α的重要性,以确保算法在合理时间内收敛。在最小值处,导数为0,θ1更新为自身减去零,即保持不变。
In this video we explored the scenario where we used one parameter θ1θ_1θ1 and plotted its cost function to implement a gradient descent. Our formula for a single parameter was :
Repeat until convergence:
θ1:=θ1−αddθ1J(θ1)θ1:=θ_1−α\dfrac {d}{dθ_1}J(θ_1)θ1:=θ1−αdθ1dJ(θ1)
Regardless of the slope’s sign for ddθ1J(θ1)\dfrac {d}{dθ_1}J(θ_1)dθ1dJ(θ1), θ1θ_1θ1 eventually converges to its minimum value. The following graph shows that when the slope is negative, the value of θ1θ_1θ1 increases and when it is positive, the value of θ1θ_1θ1 decreases.

On a side note, we should adjust our parameter ααα to ensure that the gradient descent algorithm converges in a reasonable time. Failure to converge or too much time to obtain the minimum value imply that our step size is wrong.
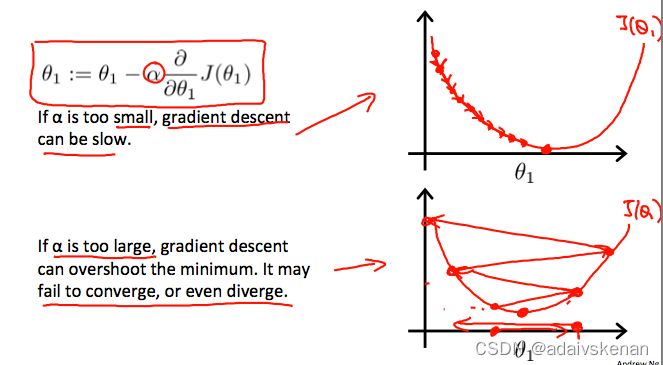
How does gradient descent converge with a fixed step size ααα?
The intuition behind the convergence is that ddθ1J(θ1)\dfrac {d}{dθ_1}J(θ_1)dθ1dJ(θ1) approaches 0 as we approach the bottom of our convex function. At the minimum, the derivative will always be 0 and thus we get:
θ1:=θ1−α∗0θ1:=θ1−α∗0θ1:=θ1−α∗0


















 1661
1661

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









