







介绍
所有的集合框架都包含如下内容
- 接口:是代表集合的抽象数据类型。例如 Collection、List、Set、Map 等。之所以定义多个接口,是为了以不同的方式操作集合对象。
- 实现(类):是集合接口的具体实现。从本质上讲,它们是可重复使用的数据结构,例如:ArrayList、LinkedList、HashSet、HashMap。
- 算法:是实现集合接口的对象里的方法执行的一些有用的计算,例如:搜索和排序。这些算法被称为多态,那是因为相同的方法可以在相似的接口上有着不同的实现。
JDK中集合相关
- jdk 1.2 开始出现,相关的接口和类都在 java.util 包中,保存的是对象的引用
- jdk 1.2 以前“古老”的集合类:Vector、Hashtable(都是同步的)
Java 集合框架图
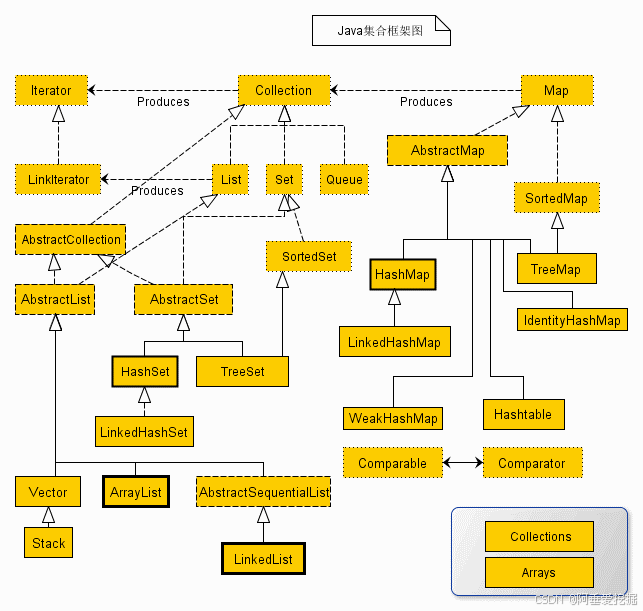
除了集合,还定义了几个 Map 接口和类。Map 里存储的是键/值对。尽管 Map 不是集合,但是它们完全整合在集合中。
Collection 和 Iterator 接口
Collection 接口操作集合元素的方法
Iterable 的子接口
- 增加
- boolean add(Object o):向集合里添加一个元素,如果集合对象被添加操作改变了,则返回 true。
- boolean addAll(Collection c):把集合 c 里的所有元素添加到指定集合里,如果集合对象被添加操作改变了,则返回 true。
- 删除
- boolean remove(Object o):删除集合中第一个符合条件的指定元素 o,返回 true。
- boolean removeAll(Collecrion c):从该集合中删除集合 c 里包含的所有元素,如果删除了一个或一个以上的元素,该方法将返回 true。
- boolean retainAll(Collection c):使该集合中仅保留集合 c 里包含的元素(求两个集合的交集),如果该操作改变了调用该方法的集合,则该方法返回 true。
- void clear():清除集合里的所有元素,将集合长度变为 0。
- 查询
- boolean contains(Object o):判断集合里是否包含指定元素 o。
- boolean containsAll(Collection c):判断集合里是否包含集合 c 里的所有元素。
- boolean isEmpty():判断集合是否为空,当集合长度为 0 时返回 true,否则返回 false。
- int size():返回集合里元素的个数。
- 其它操作
- Iterator iterator():获取一个 Iterator 对象(迭代器)。
- Object[] toArray():把集合转换成一个数组,所有的集合元素变成对应的数组元素(转化 Object 数组时,没有必要使用 toArray[new Object[0]],可以直接使用 toArray())。
- T[] toArray(T[] a):返回一个包含此集合中所有元素的数组;返回数组的运行时类型是指定数组的类型。如果指定的数组 a 能容纳该集合,则 a 将在其中返回;否则,将分配一个具有指定数组的运行时类型和此集合大小的新数组(集合转化为类型 T 数组时,尽量传入空数组 T[0])。
- 默认方法
- Stream stream()
- Stream parallelStream()
- boolean removeIf(Predicate filter):删除满足给定谓词的此集合的所有元素。
- void forEach(Consumer action):对 Iterable 的每个元素执行给定的操作。
使用 Iterator 遍历集合元素
- Iterator 接口用于遍历(即迭代访问)Collection 集合中的元素。
- 通过把集合元素的值传给了迭代变量。
- 在创建 Iterator 迭代器之后,除非通过迭代器自身的 remove() 方法对 Collection 集合里的元素进行修改,否则在对 Collection 集合进行修改后再使用迭代器进行迭代访问时,迭代器会抛出 ConcurrentModificationException。
- 实例方法
- boolean hasNext():如果集合里仍有元素可以迭代,则返回 true 。
- Object next():返回集合里的下一个元素。
- void remove():删除集合里上一次 next 方法返回的元素。
- 快速失败(fail-fast)
- 在用迭代器遍历一个集合对象时,如果遍历过程中对集合对象的内容进行了修改(增加、删除、修改,modCount != expectedmodCount),则会抛出 ConcurrentModificationException。
- java.util 包下的集合类都是快速失败的,不能在多线程下发生并发修改。
// 引入 ArrayList 和 Iterator 类
import java.util.ArrayList;
import java.util.Iterator;
public class Test {
public static void main(String[] args) {
// 创建集合
ArrayList<String> sites = new ArrayList<String>();
sites.add("Google");
sites.add("Baidu");
sites.add("Taobao");
sites.add("Zhihu");
// 获取迭代器
Iterator<String> it = sites.iterator();
// 输出集合中的所有元素
while(it.hasNext()) {
System.out.println(it.next());
}
}
}执行以上代码,输出结果如下:
Baidu
Taobao
Zhihu
使用 foreach 循环遍历集合元素
与使用 Iterator 接口迭代访问集合元素类似,foreach 循环中的迭代变量也不是集合元素本身,系统只是依次把集合元素的值赋给迭代变量,所以在遍历时不能对 Collection 集合里的元素进行修改,否则会抛出 ConcurrentModificationException(可以使用特殊的集合 CopyOnWriteArrayList、CopyOnWriteSet、ConcurrentHashMap)
public static void main(String[] args) {
List<String> list = Arrays.asList("A", "B", "C");
for (String s : list) { //集合类同样支持这种语法
System.out.println(s);
}
}但是由于仅仅是语法糖,实际上编译之后:
public static void main(String[] args) {
List<String> list = Arrays.asList("A", "B", "C");
Iterator var2 = list.iterator(); //这里使用的是List的迭代器在进行遍历操作
while(var2.hasNext()) {
String s = (String)var2.next();
System.out.println(s);
}
}List
List 是集合类型的一个分支,它的主要特性有:
- 是一个有序的集合,插入元素默认是插入到尾部,按顺序从前往后存放,每个元素都有一个自己的下标位置
- 列表中允许存在重复元素
在 List 接口中,定义了列表类型需要支持的全部操作,List 直接继承自前面介绍的 Collection 接口,其中很多地方重新定义了一次Collection 接口中定义的方法,这样做是为了更加明确方法的具体功能,当然,为了直观,这里就省略掉:
//List是一个有序的集合类,每个元素都有一个自己的下标位置
//List中可插入重复元素
//针对于这些特性,扩展了Collection接口中一些额外的操作
public interface List<E> extends Collection<E> {
...
//将给定集合中所有元素插入到当前结合的给定位置上(后面的元素就被挤到后面去了,跟我们之前顺序表的插入是一样的)
boolean addAll(int index, Collection<? extends E> c);
...
//Java 8新增方法,可以对列表中每个元素都进行处理,并将元素替换为处理之后的结果
default void replaceAll(UnaryOperator<E> operator) {
Objects.requireNonNull(operator);
final ListIterator<E> li = this.listIterator(); //这里同样用到了迭代器
while (li.hasNext()) {
li.set(operator.apply(li.next()));
}
}
//对当前集合按照给定的规则进行排序操作,这里同样只需要一个Comparator就行了
@SuppressWarnings({"unchecked", "rawtypes"})
default void sort(Comparator<? super E> c) {
Object[] a = this.toArray();
Arrays.sort(a, (Comparator) c);
ListIterator<E> i = this.listIterator();
for (Object e : a) {
i.next();
i.set((E) e);
}
}
...
//-------- 这些是List中独特的位置直接访问操作 --------
//获取对应下标位置上的元素
E get(int index);
//直接将对应位置上的元素替换为给定元素
E set(int index, E element);
//在指定位置上插入元素,就跟我们之前的顺序表插入是一样的
void add(int index, E element);
//移除指定位置上的元素
E remove(int index);
//------- 这些是List中独特的搜索操作 -------
//查询某个元素在当前列表中的第一次出现的下标位置
int indexOf(Object o);
//查询某个元素在当前列表中的最后一次出现的下标位置
int lastIndexOf(Object o);
//------- 这些是List的专用迭代器 -------
//迭代器我们会在下一个部分讲解
ListIterator<E> listIterator();
//迭代器我们会在下一个部分讲解
ListIterator<E> listIterator(int index);
//------- 这些是List的特殊转换 -------
//返回当前集合在指定范围内的子集
List<E> subList(int fromIndex, int toIndex);
...
}ArrayList
ArrayList 是 List 接口的典型实现类本质上。
ArrayList是对象引用的一个变长数组ArrayList 是线程不安全的,而 Vector 是线程安全的,即使为保证 List 集合线程安全,也不推荐使用VectorArrays.asList(…) 方法返回的 List 集合既不是 ArrayList 实例,也不是 Vector 实例。
Arrays.asList(…) 返回值是一个固定长度的 List 集合。
ArrayList集合数据存储的结构是数组结构。
元素增删慢,查找快,由于日常开发中使用最多的功能为查询数据、遍历数据,所以ArrayList是最常用的集合。
使用
import java.util.ArrayList;
public class Test {
public static void main(String[] args) {
ArrayList<String> sites = new ArrayList<String>();
sites.add("Google");
sites.add("Baidu");
sites.add("Taobao");
sites.add("Weibo");
System.out.println(sites);
System.out.println(sites.get(1)); // 访问第二个元素
sites.set(2, "Wiki"); // 第一个参数为索引位置,第二个为要修改的值
System.out.println(sites);
sites.remove(3); // 删除第四个元素
System.out.println(sites);
System.out.println(sites.size());//计算大小
//使用 for 来迭代数组列表中的元素
for (int i = 0; i < sites.size(); i++) {
System.out.println(sites.get(i));
}
}
}常用方法
| 方法 | 描述 |
| add(int index,E element) | 将元素插入到指定位置的 arraylist 中。
|
| addAll(int index, Collection c) | 添加集合中的所有元素到 arraylist 中。
|
| clear() | 删除 arraylist 中的所有元素。 |
| clone() | 复制一份 arraylist,属于浅拷贝。 |
| contains(Object obj) | 判断元素是否在 arraylist 。
如果指定的元素存在于动态数组中,则返回 true。 如果指定的元素不存在于动态数组中,则返回 false。 |
| get(int index) | 通过索引值获取 arraylist 中的元素。
返回动态数组中指定索引处的元素。 如果 index 值超出了范围,则抛出 IndexOutOfBoundsException 异常。 |
| indexOf(Object obj) | 返回 arraylist 中元素的索引值。
从动态数组中返回指定元素的位置的索引值。 如果 obj 元素在动态数组中重复出现,返回在数组中最先出现 obj 的元素索引值。 如果动态数组中不存在指定的元素,则该 indexOf() 方法返回 -1。 |
| removeAll(Collection c) | 删除存在于指定集合中的 arraylist 里的所有元素。
如果从动态数组成功删除元素返回 true。 如果动态数组中存在的元素类与指定 collection 的元素类不兼容,则抛出 ClassCastException 异常。 如果动态数组中包含 null 元素,并且指定 collection 不允许 null 元素,则抛出 NullPointerException 异常。 |
| remove(Object obj)// 删除指定元素 remove(int index)// 删除指定索引位置的元素 | 删除 arraylist 里的单个元素。
如果 obj 元素出现多次,则删除在动态数组中最第一次出现的元素。 如果传入元素,删除成功,则返回 true。 如果传入索引值,则返回删除的元素。 注意:如果指定的索引超出范围,则该方法将抛出 IndexOutOfBoundsException 异常。 |
| size() | 返回 arraylist 里元素数量。 |
| isEmpty() | 判断 arraylist 是否为空。 如果数组中不存在任何元素,则返回 true。 如果数组中存在元素,则返回 false。 |
| subList(int fromIndex, int toIndex) | 截取部分 arraylist 的元素。
返回给定的动态数组截取的部分。 如果fromIndex 小于 0 或大于数组的长度,则抛出 IndexOutOfBoundsException 的异常。 如果 fromIndex 大于 toIndex 的值则抛出 IllegalArgumentException 异常。 注意:该动态数组包含的元素起始于 fromIndex 位置,直到元素索引位置为 toIndex-1,而索引位置 toIndex 的元素并不包括。 |
| set(int index, E element) | 替换 arraylist 中指定索引的元素。
返回之前在 index 位置的元素 。 如果 index 值超出范围,则抛出 IndexOutOfBoundsException 异常。 |
| sort(Collection c) | 对 arraylist 元素进行排序。
sort() 方法不返回任何值,它只是更改动态数组列表中元素的顺序。 |
| toArray(T [] arr) | 将 arraylist 转换为数组。
注意:这里 T 指的是数组的类型。 如果参数 T[] arr 作为参数传入到方法,则返回 T 类型的数组。 如果未传入参数,则返回 Object 类型的数组。 |
| toString() | 将 arraylist 转换为字符串。 |
| ensureCapacity(int minCapacity) | 设置指定容量大小的 arraylist。
没有返回值。 |
| lastIndexOf(Object obj) | 返回指定元素在 arraylist 中最后一次出现的位置。
从动态数组中返回指定元素最后出现的位置的索引值。 如果 obj 元素在动态数组中重复出现,返回在数组中最后出现 obj 的元素索引值。 如果动态数组中不存在指定的元素,则该 lastIndexOf() 方法返回 -1。 |
| retainAll(Collection c) | 保留 arraylist 中在指定集合中也存在的那些元素。
如果 arraylist 中删除了元素则返回 true。 如果 arraylist 类中存在的元素与指定 collection 的类中元素不兼容,则抛出 ClassCastException 异常。 如果 arraylist 包含 null 元素,并且指定 collection 不允许 null 元素,则抛出 NullPointerException 。 |
| containsAll(Collection c) | 查看 arraylist 是否包含指定集合中的所有元素。
如果动态数组中包含的集合中的所有元素,则返回 true。 如果 arraylist 中存在的元素与指定 collection 中的元素不兼容,则抛出 ClassCastException。 如果 collection 中包含 null 元素,并且 arraylist 中不允许 null值,则抛出 NullPointerException 异常。 |
| trimToSize() | 将 arraylist 中的容量调整为数组中的元素个数。 |
| removeRange(int fromIndex, int toIndex) | 删除 arraylist 中指定索引之间存在的元素。
没有返回值。 该方法仅删除了一部分动态数组元素,从 fromIndex 到 toIndex-1 的动态数组元素。也就是说不包括 toIIndex 索引位置的元素在内。 注意:如果fromIndex 或者 toIndex 索引超出范围,或者说 toIndex < fromIndex,则抛出 IndexOutOfBoundException 异常。 |
| replaceAll(UnaryOperator operator) | 将给定的操作内容替换掉数组中每一个元素。
没有返回值。 |
| removeIf(Predicate filter) | 删除所有满足特定条件的 arraylist 元素。 |
| forEach() | 遍历 arraylist 中每一个元素并执行特定操作。 |
LinkedList
- Linkedlist 底层维护了一个双向链表
- Linkedlist 中维护了两个属性 first 和l ast 分别指向首节点和尾节点。
- 每个节点(Node对象),里面又维护了prev、next.item三个属性,其中通过prev指向前一个,通过next指向后一个节点。最终实现双向链表。
- 所以 LinkedList 的元素的添加和删除,不是通过数组完成的,相对来说效率较高。
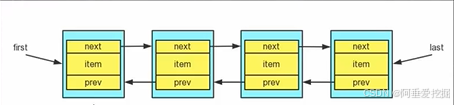
以下情况使用 ArrayList :
- 频繁访问列表中的某一个元素。
- 只需要在列表末尾进行添加和删除元素操作。
以下情况使用 LinkedList :
- 你需要通过循环迭代来访问列表中的某些元素。
- 需要频繁的在列表开头、中间、末尾等位置进行添加和删除元素操作。
LinkedList 继承了 AbstractSequentialList 类。
LinkedList 实现了 Queue 接口,可作为队列使用。
LinkedList 实现了 List 接口,可进行列表的相关操作。
LinkedList 实现了 Deque 接口,可作为队列使用。
LinkedList 实现了 Cloneable 接口,可实现克隆。
LinkedList 实现了 java.io.Serializable 接口,即可支持序列化,能通过序列化去传输。
使用
// 引入 LinkedList 类
import java.util.LinkedList;
public class Test {
public static void main(String[] args) {
LinkedList<String> sites = new LinkedList<String>();
sites.add("Google");
sites.add("Baidu");
sites.add("Taobao");
sites.add("Weibo");
System.out.println(sites);
// 使用 addFirst() 在头部添加元素
sites.addFirst("Wiki");
System.out.println(sites);
// 使用 addLast() 在尾部添加元素
sites.addLast("Weixin");
System.out.println(sites);
// 使用 removeFirst() 移除头部元素
sites.removeFirst();
System.out.println(sites);
// 使用 removeLast() 移除尾部元素
sites.removeLast();
System.out.println(sites);
// 使用 getFirst() 获取头部元素
System.out.println(sites.getFirst());
// 使用 getLast() 获取尾部元素
System.out.println(sites.getLast());
//迭代列表中的元素
for (int size = sites.size(), i = 0; i < size; i++) {
System.out.println(sites.get(i));
}
for (String i : sites) {
System.out.println(i);
}
}
}模拟一个简单的双向链表
public class LinkedList01 {
public static void main(String[] args) {
//模拟一个简单的双向链表
Node jack = new Node("jack");
Node tom = new Node("tom");
Node hsp = new Node("hsp");
//连接三个结点,形成双向链表
//jack -> tom -> hsp
jack.next = tom;
tom.next = hsp;
//hsp -> tom -> jack
hsp.pre = tom;
tom.pre = jack;
Node first = jack;
//让 first 引用指向 jack,就是双向链表的头结点
Node last = hsp;
//让 last 引用指向 hsp,就是双向链表的尾结点
//演示,从头到尾进行遍历
System.out.println("===从头到尾进行遍历===");
while (true) {
if(first == null) {
break;
}
//输出 first 信息
System.out.println(first);
first = first.next;
}
//演示,从尾到头的遍历
System.out.println("====从尾到头的遍历====");
while (true) {
if(last == null) {
break;
}
//输出 last 信息
System.out.println(last);
last = last.pre;
}
//演示链表的添加对象/数据,是多么的方便
//要求,是在 tom --------- 这里直接,插入一个对象 smith
//1. 先创建一个 Node 结点,name 就是 smith
Node smith = new Node("smith");
//下面就把 smith 加入到双向链表了
smith.next = hsp;
smith.pre = tom;
hsp.pre = smith;
tom.next = smith;
//让 first 再次指向 jack
first = jack;
//让 first 引用指向 jack,就是双向链表的头结点
System.out.println("===从头到尾进行遍历===");
while (true) {
if(first == null) {
break;
}
//输出 first 信息
System.out.println(first);
first = first.next;
}
last = hsp;
//让 last 重新指向最后一个结点 //演示,从尾到头的遍历
System.out.println("====从尾到头的遍历====");
while (true) {
if(last == null) {
break;
}
//输出 last 信息
System.out.println(last);
last = last.pre;
}
}
}
//定义一个 Node 类,Node 对象 表示双向链表的一个结点
class Node {
public Object item; //真正存放数据
public Node next; //指向后一个结点
public Node pre; //指向前一个结点
public Node(Object name) {
this.item = name;
}
public String toString() {
return "Node name=" + item;
}
}常用方法
| 方法 | 描述 |
| public boolean add(E e) | 链表末尾添加元素,返回是否成功,成功为 true,失败为 false。 |
| public void add(int index, E element) | 向指定位置插入元素。 |
| public boolean addAll(Collection c) | 将一个集合的所有元素添加到链表后面,返回是否成功,成功为 true,失败为 false。 |
| public boolean addAll(int index, Collection c) | 将一个集合的所有元素添加到链表的指定位置后面,返回是否成功,成功为 true,失败为 false。 |
| public void addFirst(E e) | 元素添加到头部。 |
| public void addLast(E e) | 元素添加到尾部。 |
| public boolean offer(E e) | 向链表末尾添加元素,返回是否成功,成功为 true,失败为 false。 |
| public boolean offerFirst(E e) | 头部插入元素,返回是否成功,成功为 true,失败为 false。 |
| public boolean offerLast(E e) | 尾部插入元素,返回是否成功,成功为 true,失败为 false。 |
| public void clear() | 清空链表。 |
| public E removeFirst() | 删除并返回第一个元素。 |
| public E removeLast() | 删除并返回最后一个元素。 |
| public boolean remove(Object o) | 删除某一元素,返回是否成功,成功为 true,失败为 false。 |
| public E remove(int index) | 删除指定位置的元素。 |
| public E poll() | 删除并返回第一个元素。 |
| public E remove() | 删除并返回第一个元素。 |
| public boolean contains(Object o) | 判断是否含有某一元素。 |
| public E get(int index) | 返回指定位置的元素。 |
| public E getFirst() | 返回第一个元素。 |
| public E getLast() | 返回最后一个元素。 |
| public int indexOf(Object o) | 查找指定元素从前往后第一次出现的索引。 |
| public int lastIndexOf(Object o) | 查找指定元素最后一次出现的索引。 |
| public E peek() | 返回第一个元素。 |
| public E element() | 返回第一个元素。 |
| public E peekFirst() | 返回头部元素。 |
| public E peekLast() | 返回尾部元素。 |
| public E set(int index, E element) | 设置指定位置的元素。 |
| public Object clone() | 克隆该列表。 |
| public Iterator descendingIterator() | 返回倒序迭代器。 |
| public int size() | 返回链表元素个数。 |
| public ListIterator listIterator(int index) | 返回从指定位置开始到末尾的迭代器。 |
| public Object[] toArray() | 返回一个由链表元素组成的数组。 |
| public T[] toArray(T[] a) | 返回一个由链表元素转换类型而成的数组。 |
Vector
Vector底层是一个对象数组, protected Object[] elementData。
Vector 是线程同步的,即线程安全,Vector类的操作方法带有 synchronized。
public class Vector_ {
@SuppressWarnings({"all"})
public static void main(String[] args) {
//无参构造器
//有参数的构造
Vector vector = new Vector(8);
for (int i = 0; i < 10; i++) {
vector.add(i);
}
vector.add(100);
System.out.println("vector=" + vector);
//解读源码
//1. new Vector() 底层
/*
public Vector() {
this(10);
}
补充:如果是 Vector vector = new Vector(8);
走的方法:
public Vector(int initialCapacity) {
this(initialCapacity, 0);
}
2. vector.add(i)
2.1 //下面这个方法就添加数据到vector集合
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
}
2.2 //确定是否需要扩容 条件 : minCapacity - elementData.length>0
private void ensureCapacityHelper(int minCapacity) {
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
2.3 //如果 需要的数组大小 不够用,就扩容 , 扩容的算法
//newCapacity = oldCapacity + ((capacityIncrement > 0) ?
// capacityIncrement : oldCapacity);
//就是扩容两倍.
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
*/
}
}比较 ArrayList 和 Vector

Set
- 无序(添加和取出的顺序不一致),没有索引即元素录入后虽然顺序不对,但是位置是固定的 。
- 不允许重复元素,所以最多包含一个null 。
HashSet
HashSet 是 Set 接口的典型实现,大多数时候使用 Set 集合时都使用这个实现类。HashSet 按 Hash 算法来存储集合中的元素,因此具有很好的存取和查找性能。
HashSet 具有以下特点:
- 不能保证元素的排列顺序,HashSet 不是线程安全的,集合元素可以是 null。
- 当向 HashSet 集合中存入一个元素时,HashSet 会调用该对象的 hashCode() 方法来得到该对象的 hashCode 值,然后根据 hashCode 值决定该对象在 HashSet 中的存储位置。
- HashSet 集合判断两个元素相等的标准:两个对象通过 hashCode() 方法比较相等,并且两个对象的 equals() 方法返回值也相等。
- 如果两个元素的 equals() 方法返回 true,但它们的 hashCode() 返回值不相等,hashSet 将会把它们存储在不同的位置,但依然可以添加成功。
- 对于存放在Set容器中的对象,对应的类一定要重写equals()和hashCode(Object obj)方法,以实现对象相等规则。存储JavaAPI中提供的类型元素时,不需要重写元素的hashCode和equals方法。
使用
// 引入 HashSet 类
import java.util.HashSet;
public class Test {
public static void main(String[] args) {
HashSet<String> sites = new HashSet<String>();
sites.add("Google");
sites.add("Baidu");
sites.add("Taobao");
sites.add("Zhihu");
sites.add("Baidu"); // 重复的元素不会被添加
System.out.println(sites);
System.out.println(sites.contains("Taobao"));//判断元素是否存在于集合当中
sites.remove("Taobao"); // 删除元素,删除成功返回 true,否则为 false
System.out.println(sites);
System.out.println(sites.size()); //计算 HashSet 中的元素数量
//使用 for-each 来迭代
for (String i : sites) {
System.out.println(i);
}
sites.clear(); //删除集合中所有元素
System.out.println(sites);
}
}自定义类型的存储
重写 hashCode() 方法的基本原则:在程序运行时,同一个对象多次调用 hashCode() 方法应该返回相同的值;当两个对象的 equals() 方法比较返回 true 时,这两个对象的 hashCode() 方法的返回值也应相等;对象中用作 equals() 方法比较的 Field,都应该用来计算 hashCode 值;
class Student {
private String name;
private int age;
public Student(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student [name=" + name + ", age=" + age + "]";
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if(!(obj instanceof Student)){
System.out.println("类型错误");
return false;
}
Student other = (Student) obj;
return this.age == other.age && this.name.equals(other.name);
}
}
public class HashSetDemo {
public static void main(String[] args) {
//创建HashSet对象
HashSet hs = new HashSet();
//给集合中添加自定义对象
hs.add(new Student("zhangsan",21));
hs.add(new Student("lisi",22));
hs.add(new Student("wangwu",23));
hs.add(new Student("zhangsan",21));
//取出集合中的每个元素
Iterator it = hs.iterator();
while(it.hasNext()){
Student s = (Student)it.next();
System.out.println(s);
}
}
}LinkedHashSet
基本介绍
- LinkedHashset 是Hashset 的子类 。
- LinkedHashSet 底层是一个 LinkedHashMap,底层维护了一个 数组+双向链表 。
- LinkedHashSet 根据元素的 hashCode 值来决定元素的存储位置,同时使用链表维护元素的次序(图),这使得元素看起来是以插入顺序保存的 。
- LinkedHashSet 不允许添重复元素 。
底层机制和源代码分析
- LinkedHashSet 加入顺序和取出元素/数据的顺序一致。
- LinkedHashSet 底层维护的是一个LinkedHashMap(是HashMap的子类)。
- LinkedHashSet 底层结构 (数组table+双向链表)。
- 添加第一次时,直接将 数组table 扩容到 16 ,存放的结点类型是 LinkedHashMap Entry。
- 数组是 HashMapEntry类型。
public class LinkedHashSetSource {
public static void main(String[] args) {
//分析一下LinkedHashSet的底层机制
Set set = new LinkedHashSet();
set.add(new String("AA"));
set.add(456);
set.add(456);
set.add(new Customer("刘", 1001));
set.add(123);
set.add("HSP");
System.out.println("set=" + set);
//1. LinkedHashSet 加入顺序和取出元素/数据的顺序一致
//2. LinkedHashSet 底层维护的是一个LinkedHashMap(是HashMap的子类)
//3. LinkedHashSet 底层结构 (数组table+双向链表)
//4. 添加第一次时,直接将 数组table 扩容到 16 ,存放的结点类型是 LinkedHashMap$Entry
//5. 数组是 HashMap$Node[] 存放的元素/数据是 LinkedHashMap$Entry类型
/*
//继承关系是在内部类完成.
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
*/
}
}
class Customer {
private String name;
private int no;
public Customer(String name, int no) {
this.name = name;
this.no = no;
}
}TreeSet
底层机制
TreeSet()构造器需传入Comparator接口的匿名内部类,因为底层 Comparable k = (Comparator) key;
若没有传入,则需要把传入的类实现 Comparable 接口 。
若按照compare方法比较value相同则无法加入value 。
public class TreeSet_ {
public static void main(String[] args) {
//1. 当我们使用无参构造器,创建TreeSet时,默认按字母排序
//2. 如果希望添加的元素,按照字符串大小来排序
//3. 使用TreeSet 提供的一个构造器,可以传入一个比较器(匿名内部类)
// 并指定排序规则
//4. 简单看看源码
/*
1. 构造器把传入的比较器对象,赋给了 TreeSet的底层的 TreeMap的属性this.comparator
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}
2. 在 调用 treeSet.add("tom"), 在底层会执行到
if (cpr != null) {//cpr 就是我们的匿名内部类(对象)
do {
parent = t;
//动态绑定到我们的匿名内部类(对象)compare
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else //如果相等,即返回0,这个Key就没有加入
return t.setValue(value);
} while (t != null);
}
*/
// TreeSet treeSet = new TreeSet();
TreeSet treeSet = new TreeSet(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
//下面 调用String的 compareTo方法进行字符串大小比较
//如果老韩要求加入的元素,按照长度大小排序
//return ((String) o2).compareTo((String) o1);
return ((String) o1).length() - ((String) o2).length();
}
});
//添加数据.
treeSet.add("jack");
treeSet.add("tom");//3
treeSet.add("sp");
treeSet.add("a");
treeSet.add("abc");//3
System.out.println("treeSet=" + treeSet);
}
}Map
- Map与Collection井列存在,用于保存具有映射关系的数据
- Map 中的key 和 value 可以是任何引用类型的数据,会封装到HashMap$Node对象中
- Map 中的key 不允许重复,原因和HashSet 一样(key一样就会去替换value值)
- Map 中的value 可以重复
- Map 的key可以为null,value也可以为null,key为null只有能有一个,value为null可以为多个
- 常用String类作为Map的key
- key 和 value 之间存在单向一对一关系,即通过指定的 key 总能找到对应的 value
- Map存放数据的key-value示意图,一对 k-y是放在一个Node中的,有因为Node 实现了 Entry 接口
使用
//Map并不是Collection体系下的接口,而是单独的一个体系,因为操作特殊
//这里需要填写两个泛型参数,其中K就是键的类型,V就是值的类型,比如上面的学生信息,ID一般是int,那么键就是Integer类型的,而值就是学生信息,所以说值是学生对象类型的
public interface Map<K,V> {
//-------- 查询相关操作 --------
//获取当前存储的键值对数量
int size();
//是否为空
boolean isEmpty();
//查看Map中是否包含指定的键
boolean containsKey(Object key);
//查看Map中是否包含指定的值
boolean containsValue(Object value);
//通过给定的键,返回其映射的值
V get(Object key);
//-------- 修改相关操作 --------
//向Map中添加新的映射关系,也就是新的键值对
V put(K key, V value);
//根据给定的键,移除其映射关系,也就是移除对应的键值对
V remove(Object key);
//-------- 批量操作 --------
//将另一个Map中的所有键值对添加到当前Map中
void putAll(Map<? extends K, ? extends V> m);
//清空整个Map
void clear();
//-------- 其他视图操作 --------
//返回Map中存放的所有键,以Set形式返回
Set<K> keySet();
//返回Map中存放的所有值
Collection<V> values();
//返回所有的键值对,这里用的是内部类Entry在表示
Set<Map.Entry<K, V>> entrySet();
//这个是内部接口Entry,表示一个键值对
interface Entry<K,V> {
//获取键值对的键
K getKey();
//获取键值对的值
V getValue();
//修改键值对的值
V setValue(V value);
//判断两个键值对是否相等
boolean equals(Object o);
//返回当前键值对的哈希值
int hashCode();
...
}
...
}Map中定义了非常多的方法,尤其是在Java 8之后新增的大量方法。
HashMap
注意事项和细节
- HashMap 是Map 接口使用频率最高的实现类。
- Hashap 是以 key-val 对的方式来存储数据(HashMap$Node类型)。
- key 不能重复,但是值可以重复,允许使用null和null值。
- 如果添加相同的key,则会覆盖原来的 key-val ,等同于修改(key不会替换,val会替换)。
- 与 HashSet 一样,不保证映射的顺序,因为底层是以hash表的方式来存储的(jdk8的hashMap 底层 数组+链表+红黑树)。
- HashMap 没有实现同步,因此是线程不安全的,方法没有做同步互斥的操作,没有 synchronized。
底层机制和源码剖析
- 扩容机制和 Hashset 相同。
- HashMap底层维护了 Node 类型的数组 table,默认为 null。
- 当创建对象时,将加载因子( loadfactor )初始化为 0.75。
- 当添加 key-val 时,通过 key 的哈希值得到在table的索引。然后判断该索引处是否有元素,如果没有元素直接添加。如果该索引处有元素,继续判断该元素的 key 是否和准备加入的 key 相等,如果相等,则直接替换 val:如果不相等需要判断是树结构还是链表结构,做出相应处理。如果添加时发现容量不够,则需要扩容。
- 第1次添加,则需要扩容table容量为16,临界值( threshold )为12。
- 以后再扩容,则需要扩容 table 容量为原来的2倍,临界值为原来的 2 倍,即 24,依次类推。
- 在 Java8 中,如果一条链表的元素个数超过 TREEIFY THRESHOLD(默认是8),并且 table 的大小>=MIN TREEIFY CAPACITY(默认64),就会进行树化(红黑树)。
使用
// 引入 HashMap 类
import java.util.HashMap;
public class Test {
public static void main(String[] args) {
// 创建 HashMap 对象 Sites
HashMap<Integer, String> Sites = new HashMap<Integer, String>();
// 添加键值对
Sites.put(1, "Google");
Sites.put(2, "Baidu");
Sites.put(3, "Taobao");
Sites.put(4, "Zhihu");
System.out.println(Sites);
System.out.println(Sites.get(3));//使用 get(key) 方法来获取 key 对应的 value
System.out.println(Sites.size());//计算 HashMap 中的元素数量
//第一组: 先取出 所有的Key , 通过Key 取出对应的Value
Set keyset = Sites.keySet();
//(1) 增强for
System.out.println("---第一种方式-------");
for (Object key : keyset) {
System.out.println(key + "-" + Sites.get(key));
}
//(2) 迭代器
System.out.println("----第二种方式--------");
Iterator iterator = keyset.iterator();
while (iterator.hasNext()) {
Object key = iterator.next();
System.out.println(key + "-" + Sites.get(key));
}
//第二组: 把所有的values取出
Collection values = Sites.values();
//这里可以使用所有的Collections使用的遍历方法
//(1) 增强for
System.out.println("---取出所有的value 增强for----");
for (Object value : values) {
System.out.println(value);
}
//(2) 迭代器
System.out.println("---取出所有的value 迭代器----");
Iterator iterator2 = values.iterator();
while (iterator2.hasNext()) {
Object value = iterator2.next();
System.out.println(value);
}
//第三组: 通过EntrySet 来获取 k-v
Set entrySet = Sites.entrySet();// EntrySet<Map.Entry<K,V>>
//(1) 增强for
System.out.println("----使用EntrySet 的 for增强(第3种)----");
for (Object entry : entrySet) {
//将entry 转成 Map.Entry
Map.Entry m = (Map.Entry) entry;
System.out.println(m.getKey() + "-" + m.getValue());
}
//(2) 迭代器
System.out.println("----使用EntrySet 的 迭代器(第4种)----");
Iterator iterator3 = entrySet.iterator();
while (iterator3.hasNext()) {
Object entry = iterator3.next();
//System.out.println(next.getClass());//HashMap$Node -实现-> Map.Entry (getKey,getValue)
//向下转型 Map.Entry
Map.Entry m = (Map.Entry) entry;
System.out.println(m.getKey() + "-" + m.getValue());
}
Sites.remove(4);//使用 remove(key) 方法来删除 key 对应的键值对(key-value)
System.out.println(Sites);
Sites.clear();//删除所有键值对(key-value)
System.out.println(Sites);
}
}常用方法
Java HashMap 常用方法列表如下:
| 方法 | 描述 |
| clear() | 删除 hashMap 中的所有键/值对 |
| clone() | 复制一份 hashMap |
| isEmpty() | 判断 hashMap 是否为空 |
| size() | 计算 hashMap 中键/值对的数量 |
| put() | 将键/值对添加到 hashMap 中 |
| putAll() | 将所有键/值对添加到 hashMap 中 |
| putIfAbsent() | 如果 hashMap 中不存在指定的键,则将指定的键/值对插入到 hashMap 中。 |
| remove() | 删除 hashMap 中指定键 key 的映射关系 |
| containsKey() | 检查 hashMap 中是否存在指定的 key 对应的映射关系。 |
| containsValue() | 检查 hashMap 中是否存在指定的 value 对应的映射关系。 |
| replace() | 替换 hashMap 中是指定的 key 对应的 value。 |
| replaceAll() | 将 hashMap 中的所有映射关系替换成给定的函数所执行的结果。 |
| get() | 获取指定 key 对应对 value |
| getOrDefault() | 获取指定 key 对应对 value,如果找不到 key ,则返回设置的默认值 |
| forEach() | 对 hashMap 中的每个映射执行指定的操作。 |
| entrySet() | 返回 hashMap 中所有映射项的集合集合视图。 |
| keySet() | 返回 hashMap 中所有 key 组成的集合视图。 |
| values() | 返回 hashMap 中存在的所有 value 值。 |
| merge() | 添加键值对到 hashMap 中 |
| compute() | 对 hashMap 中指定 key 的值进行重新计算 |
| computeIfAbsent() | 对 hashMap 中指定 key 的值进行重新计算,如果不存在这个 key,则添加到 hashMap 中 |
| computeIfPresent() | 对 hashMap 中指定 key 的值进行重新计算,前提是该 key 存在于 hashMap 中。 |
Hashtable
注意事项和细节
- 存放的元素是键值对:即K-V。
- hashtable 的键和值都不能为 null, 否则会抛出 NulPointerException。
- hashTable 使用方法基本上和 HashMap 一样。
- hashTable 是线程安全的( synchronized ),hashmap 是线程不安全的。
底层机制
- 底层有数组 Hashtable$Entry[] 初始化大小为 11。
- 临界值 threshold 8 = 11 * 0.75。
- 扩容: 按照自己的扩容机制来进行即可。
- 执行 方法 addEntry(hash, key, value, index); 添加K-V 封装到Entry。
- 当 if (count >= threshold) 满足时,就进行扩容(2*n+1)。
- 按照 int newCapacity = (oldCapacity
Hashtable和HashMap

LinkedHashMap
概念及概述
LinkedHashMap 继承自 HashMap,在 HashMap 基础上,通过维护一条双向链表,解决了 HashMap 不能随时保持遍历顺序和插入顺序一致的问题。在一些场景下,该特性很有用,比如缓存。在实现上,LinkedHashMap 很多方法直接继承自 HashMap,仅为维护双向链表覆写了部分方法。
当希望有顺序地去存储key-value时,就需要使用 LinkedHashMap 了。
Collections
基本介绍
- Collections 是一个操作 Set.List 和 Map 等集合的工具类
- Collections 中提供了一系列静态的方法对集合元素进行排序、查询和修改等操作
常用方法
- 排序操作:
- 查找替换:
public class Collections_ {
public static void main(String[] args) {
//创建ArrayList 集合,用于测试.
List list = new ArrayList();
list.add("tom");
list.add("smith");
list.add("king");
list.add("milan");
list.add("tom");
// reverse(List):反转 List 中元素的顺序
Collections.reverse(list);
System.out.println("list=" + list);
// shuffle(List):对 List 集合元素进行随机排序
// for (int i = 0; i < 5; i++) {
// Collections.shuffle(list);
// System.out.println("list=" + list);
// }
// sort(List):根据元素的自然顺序对指定 List 集合元素按升序排序
Collections.sort(list);
System.out.println("自然排序后");
System.out.println("list=" + list);
// sort(List,Comparator):根据指定的 Comparator 产生的顺序对 List 集合元素进行排序
//我们希望按照 字符串的长度大小排序
Collections.sort(list, new Comparator() {
@Override
public int compare(Object o1, Object o2) {
//可以加入校验代码.
return ((String) o2).length() - ((String) o1).length();
}
});
System.out.println("字符串长度大小排序=" + list);
// swap(List,int, int):将指定 list 集合中的 i 处元素和 j 处元素进行交换
//比如
Collections.swap(list, 0, 1);
System.out.println("交换后的情况");
System.out.println("list=" + list);
//Object max(Collection):根据元素的自然顺序,返回给定集合中的最大元素
System.out.println("自然顺序最大元素=" + Collections.max(list));
//Object max(Collection,Comparator):根据 Comparator 指定的顺序,返回给定集合中的最大元素
//比如,我们要返回长度最大的元素
Object maxObject = Collections.max(list, new Comparator() {
@Override
public int compare(Object o1, Object o2) {
return ((String)o1).length() - ((String)o2).length();
}
});
System.out.println("长度最大的元素=" + maxObject);
//Object min(Collection)
//Object min(Collection,Comparator)
//上面的两个方法,参考max即可
//int frequency(Collection,Object):返回指定集合中指定元素的出现次数
System.out.println("tom出现的次数=" + Collections.frequency(list, "tom"));
//void copy(List dest,List src):将src中的内容复制到dest中
ArrayList dest = new ArrayList();
//为了完成一个完整拷贝,我们需要先给dest 赋值,大小和list.size()一样
for(int i = 0; i < list.size(); i++) {
dest.add("");
}
//拷贝
Collections.copy(dest, list);
System.out.println("dest=" + dest);
//boolean replaceAll(List list,Object oldVal,Object newVal):使用新值替换 List 对象的所有旧值
//如果list中,有tom 就替换成 汤姆
Collections.replaceAll(list, "tom", "汤姆");
System.out.println("list替换后=" + list);
}
}Stream流
JDK 1.8 API添加了一个新的抽象称为流 Stream,可以让你以一种声明的方式处理数据。
Stream 使用一种类似用 SQL 语句从数据库查询数据的直观方式来提供一种对 Java 集合运算和表达的高阶抽象。
Stream API可以极大提高Java程序员的生产力,让程序员写出高效率、干净、简洁的代码。
这种风格将要处理的元素集合看作一种流, 流在管道中传输, 并且可以在管道的节点上进行处理, 比如筛选, 排序,聚合等。
元素流在管道中经过中间操作(intermediate operation)的处理,最后由最终操作( terminal operation )得到前面处理的结果。
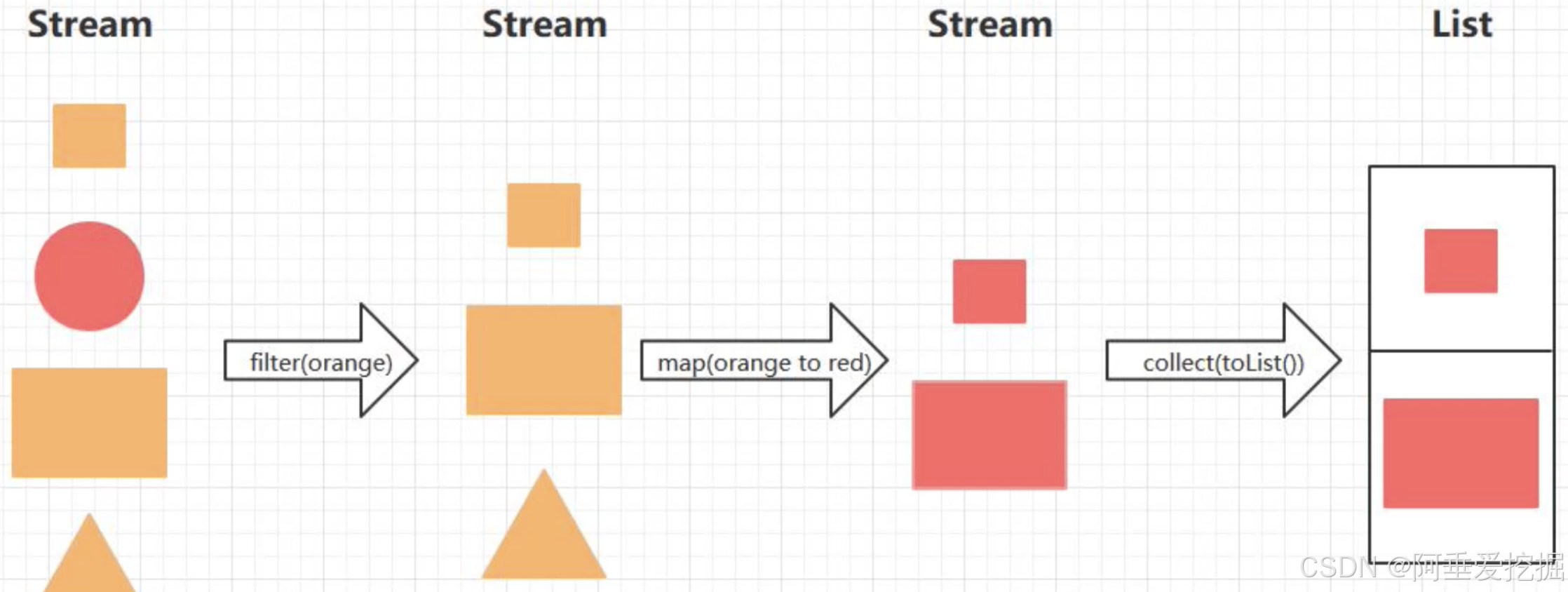
它看起来就像一个工厂的流水线一样!我们就可以把一个Stream当做流水线处理:
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("A");
list.add("B");
list.add("C");
//移除为B的元素
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()){
if(iterator.next().equals("B")) iterator.remove();
}
//Stream操作
list = list //链式调用
.stream() //获取流
.filter(e -> !e.equals("B")) //只允许所有不是B的元素通过流水线
.collect(Collectors.toList()); //将流水线中的元素重新收集起来,变回List
System.out.println(list);
}可能从上述例子中还不能感受到流处理带来的便捷,我们通过下面这个例子来感受一下:
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(3);
list = list
.stream()
.distinct() //去重(使用equals判断)
.sorted((a, b) -> b - a) //进行倒序排列
.map(e -> e+1) //每个元素都要执行+1操作
.limit(2) //只放行前两个元素
.collect(Collectors.toList());
System.out.println(list);
}当遇到大量的复杂操作时,我们就可以使用Stream来快速编写代码,这样不仅代码量大幅度减少,而且逻辑也更加清晰明了(如果你学习过SQL的话,你会发现它更像一个Sql语句)。
注意:不能认为每一步是直接依次执行的!我们可以断点测试一下:
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(3);
list = list
.stream()
.distinct() //断点
.sorted((a, b) -> b - a)
.map(e -> {
System.out.println(">>> "+e); //断点
return e+1;
})
.limit(2) //断点
.collect(Collectors.toList());实际上,stream会先记录每一步操作,而不是直接开始执行内容,当整个链式调用完成后,才会依次进行,也就是说需要的时候,工厂的机器才会按照预定的流程启动。
用一堆随机数来进行更多流操作的演示:
public static void main(String[] args) {
Random random = new Random(); //没想到吧,Random支持直接生成随机数的流
random
.ints(-100, 100) //生成-100~100之间的,随机int型数字(本质上是一个IntStream)
.limit(10) //只获取前10个数字(这是一个无限制的流,如果不加以限制,将会无限进行下去!)
.filter(i -> i < 0) //只保留小于0的数字
.sorted() //默认从小到大排序
.forEach(System.out::println); //依次打印
}Stream用法
filter(Predicate predicate):根据指定的条件筛选元素。
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
List<Integer> result = list.stream().filter(n -> n % 2 == 0).collect(Collectors.toList());
// 输出:[2, 4]
map(Function mapper):将元素转换为另一种类型。
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
List<String> result = list.stream().map(n -> "Number: " + n).collect(Collectors.toList());
// 输出:["Number: 1", "Number: 2", "Number: 3", "Number: 4", "Number: 5"]
flatMap(Function> mapper):将流中的每个元素转换为一个流,然后将所有流合并为一个流。
List<List<Integer>> lists = Arrays.asList(Arrays.asList(1, 2), Arrays.asList(3, 4, 5));
List<Integer> result = lists.stream().flatMap(list -> list.stream()).collect(Collectors.toList());
// 输出:[1, 2, 3, 4, 5]
distinct():去除流中重复的元素。
List<Integer> list = Arrays.asList(1, 2, 3, 2, 4, 1, 5);
List<Integer> result = list.stream().distinct().collect(Collectors.toList());
// 输出:[1, 2, 3, 4, 5]
sorted():对流中元素进行排序。
List<Integer> list = Arrays.asList(5, 3, 1, 2, 4);
List<Integer> result = list.stream().sorted().collect(Collectors.toList());
// 输出:[1, 2, 3, 4, 5]
peek(Consumer action):对流中的元素执行指定的操作。
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
List<Integer> result = list.stream().peek(n -> System.out.println("Processing element: " + n)).collect(Collectors.toList());
// 输出:Processing element: 1 Processing element: 2 Processing element: 3 Processing element: 4 Processing element: 5
limit(long maxSize):截取流中的前N个元素。
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
List<Integer> result = list.stream().limit(3).collect(Collectors.toList()); // 输出:[1, 2, 3]
skip(long n):跳过流中的前N个元素。
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
List<Integer> result = list.stream().skip(3).collect(Collectors.toList());
// 输出:[4, 5]
forEach(Consumer action):对流中的每个元素执行指定的操作。
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
list.stream().forEach(n -> System.out.println(n));
// 输出:1 2 3 4 5
collect(Collector collector):将流中的元素收集到一个容器中。
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
List<Integer> result = list.stream().filter(n -> n % 2 == 0).collect(Collectors.toList());
// 输出:[2, 4]
count():返回流中的元素个数。
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
long count = list.stream().count();
// 输出:5
reduce(T identity, BinaryOperator accumulator):将流中的元素逐个与初始值进行操作,返回最终结果。
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
int sum = list.stream().reduce(0, (a, b) -> a + b);
// 输出:15
findFirst()和findAny():返回流中的第一个元素或任意一个元素。
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
Optional<Integer> first = list.stream().findFirst();
Optional<Integer> any = list.stream().findAny();
// 输出:1
max()和min():返回流中的最大元素或最小元素。
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
Optional<Integer> max = list.stream().max(Integer::compareTo);
Optional<Integer> min = list.stream().min(Integer::compareTo);
// 输出:5 1
allMatch(Predicate predicate)、anyMatch(Predicate predicate)和noneMatch(Predicate predicate):分别返回流中所有元素是否满足指定条件、是否至少有一个元素满足指定条件、是否没有元素满足指定条件。
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
boolean allMatch = list.stream().allMatch(n -> n > 0);
boolean anyMatch = list.stream().anyMatch(n -> n % 2 == 0);
boolean noneMatch = list.stream().noneMatch(n -> n > 5);
// 输出:true true false
总结常用 API
filter(按照条件过滤需要数据);
max(取出流中的最大值);
min(取出流中的最小值);
count(取出流中的数量);
sum(取出流中数据的和);
average(取出流中数据的平均值);
distinct(将流中的数据去重);
sorted(自然排序,默认为升序,可以设置为升序排序或者降序排序);
limit,skip (限制和跳过:可以将流数据的部分截取,可用于后台的分页场景);
map(映射转换);
collect,toList(不可以对集合去重);
collect, toSet(可以集合去重);
toArray(将流数据转为数组);
mapToInt,distinct(将流数据转成IntStream,并去重);
reduce 求和;
reduce 求最大值;
reduce 求最小值;
reduce 求乘积;
findFirst(查找第一个元素);
findAny(任意查找一个元素);
allMatch(判断是否全部满足条件,全部满足返回 true,否则返回false);
anyMatch(判断是否有一个满足条件,只要有一个满足就返回 true,否则都不满足返回false);
noneMatch(判断是否都不满足条件,都不满足返回true,否则返回false);
flatmap(扁平化流处理);
总结
选择集合
1、先判断存储的类型(一组对象[单列]或一组键值对[双列])
2、一组对象[单列]: Collection接口
- 允许重复:List增删多:LinkedList [底层维护双向链表]改查多:ArrayList [底层維护 Object类型的可变数组]
-
不允许重复:Set无序:HashSet [底层是HashMap,维护了一个哈希表,即(数组+链表+红黑树)]排序:Treeset []插入和取出顺序一致:LinkedHashSet [底层维护数组+双向链表]
3、一组键[值对双列]:Map
- 键无序:HashMap [底层是:哈希表 jdk7:数组+链表,jdk8:数组+链表+红黑树]
- 键排序:TreeMap []
- 键插入和取出顺序一致:LinkedHashMap
- 读取文件 Propertie



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











