




 本文介绍如何使用正则表达式进行字符串的查找、分割与替换,通过实例演示去除特殊字符的过程,适合初学者掌握正则表达式的应用技巧。
本文介绍如何使用正则表达式进行字符串的查找、分割与替换,通过实例演示去除特殊字符的过程,适合初学者掌握正则表达式的应用技巧。
一个简单的正则表达式,可能会起大作用。比如说字符集就是这样。一篇文章如果有各种乱码,就可以用这种方法去除。如去除“-,$()#+&*”之类符号是很方便的。按照查找、分割、替换的套路再做一做这样的练习。今天晚了,后续还要操作文件来完善这一点。
import re
p=re.compile(r'[-,$()#+&*]')
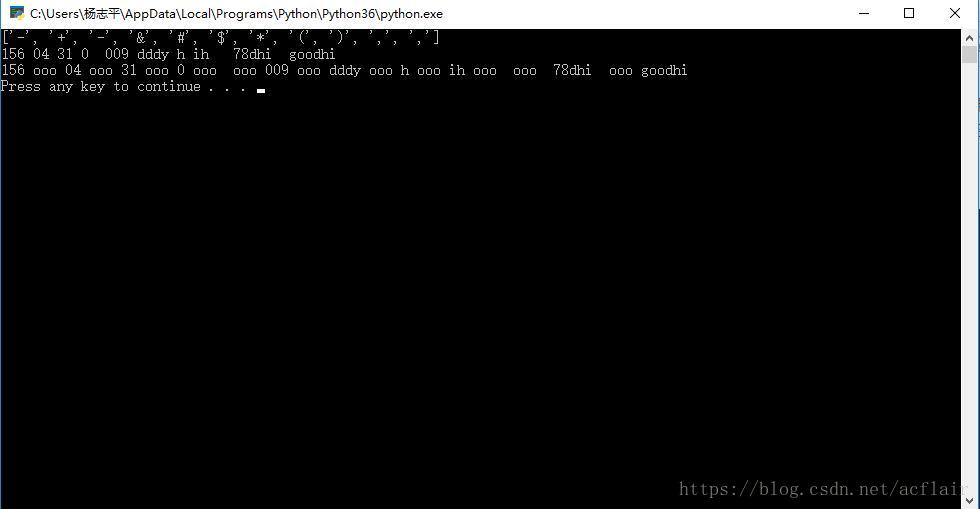
str="156-04+31-0	$dddy*h(ih), 78dhi ,goodhi"
#查找特定单个字符
m=re.findall(p,str)
print(m)
#分割。如果一篇文章当中,要一次去掉某些特定的符号,这句很有效率
subs=re.split(p,str)
print(" ".join(subs))
#替换
print(re.sub(p," ooo ",str))
其结果是:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









