




 本文介绍了一种针对交通监控场景的车辆细粒度识别方法,利用3D Bounding Box进行图像正则化和数据增强。通过3Dbbox的估计和图像处理技术,显著提高了车辆类型识别的准确率,同时降低了错误率。文章提出了一种不需要3Dbbox先验信息的估计方法,并创建了一个大型车辆数据集BoxCar116K,包含多种角度的车辆样本,用于训练和测试。实验结果表明,该方法在多个CNN结构上均取得了显著的性能提升,与现有方法相比,准确率提高了12个百分点,错误率降低了50%。
本文介绍了一种针对交通监控场景的车辆细粒度识别方法,利用3D Bounding Box进行图像正则化和数据增强。通过3Dbbox的估计和图像处理技术,显著提高了车辆类型识别的准确率,同时降低了错误率。文章提出了一种不需要3Dbbox先验信息的估计方法,并创建了一个大型车辆数据集BoxCar116K,包含多种角度的车辆样本,用于训练和测试。实验结果表明,该方法在多个CNN结构上均取得了显著的性能提升,与现有方法相比,准确率提高了12个百分点,错误率降低了50%。
BoxCars:Improving Fine-Grained Recognition of Vehicles using 3D Bounding Boxes in Traffic Surveillance
Abstract
本文中我们专注于交通应用中的细粒度车辆识别研究。本文提出了一种与当前细粒度识别(自动部件识别,bilinear pooling)发展方向一致的算法。此外,与其它专注于细粒度车辆识别的方法相比,我们不将自己局限于正面/侧面的视角,而是允许任意角度的车辆识别。我们的方法基于车辆轮廓周报的3Dbbox。Bbox可以自动通过交通监控数据生成。低于无法进行精准构建的场景,我们提出了一种3Dbbox估计的方法。3DBbox用来通过“unpacking”图像到水平面从而正则化图像的视角。本文还提出在CNN训练过程中,随机改变样本的颜色,在图像随机位置增加一个带有随机噪声的矩形区域的方法。我们收集了一个大型的细粒度车辆数据集BoxCar116K,数据集包含从不同监控摄像机拍摄的不同角度的车厢样本11.6万张。我们进行了一系列实验,实验结果证明我们的方法极大的提升了分类的准确率(与不加入提出的方法相比,准确率增加了12个百分点而错误率降低与50%)。我们还展示了我们的方法比STOA细粒度识别方法表现更好。
1、Introduction
无论从应用角度(监控,数据检索等)还是从适用于其他领域的一般性细粒度研究的角度来看,细粒度车辆识别任务都是有趣的。例如Gebru在文献【1】中提出了一种基于车辆细粒度识别的人口统计估计的方法。本文将介绍一种显著提高了多个SOTA的CNN结构在车辆细粒度识别任务中性能的方法。我们的目标场景是交通监控环境,即从任意角度拍摄的车辆图片—我们不将自己局限于前/后视角。由于这些样本是由监控摄像机拍摄的,因此他们具有一定的挑战性—目标通常较小,而且是从普通的角度拍摄(一定高度)。我们利用不同摄像机的图像构建训练和测试集,因为在监视应用程序中,摄像机在什么视角下拍摄道路通常是不可知的。
专注于细粒度车辆识别的方法通常有一定的局限性—他们可以局限于前/后视角或者对所有车都使用3D CAD模型。这两种限制都在大规模部署的时候很不实用。也有一些利用常见方法进行细粒度车辆识别。这些方法主要遵循几个主要方向—自动部件识别【2,3】,bilinear pooling【4,5】,或利用细粒度结构标签【6,7】。我们的方法并不局限于任何特定的视角,也不需要车辆的三维模型。
我们提出了一种正胶的方法,使用改进输入实现更好的图片正则化与数据增强的CNN网络(因此,我们的方法可与其它的方法进行组合)。我们使用车辆轮廓的3Dbbox来正则化车辆样本(见图4例)。这些工作是基于我们之前的会议论文【8】;它进一步提升了算法那表现,我们主要提供了一种无需先验知识的3Dbbox构建方法(见图1)。我们对分类输入的修改能够显著提高分类精度(高达12个百分点,分类误差减少近50%)。
本文的主要贡献如下:
- 对我们之前的方法进行复杂彻底的评估【8】。
- 新的数据增强技术进一步提高了我们与之前SOTA的车辆细粒度识别方法的优势(Ⅲ-C)。
- 通过对训练与测试过程中3Dbbox的估计消除了文献【8】中算法的对3Dbbox的要求(Ⅲ-D)。
- 我们给BoxCars数据集收集了更多的样本,将数据集的大小增加了1倍(Ⅳ)。
我们将公开建立的数据集与算法的源码,以供将来参考与对比。
2、Related Work
为了给提出的方法提供上下文,我们总结了现有的细粒度识别方法(包括通用的与专注于车辆的方法)。
A、General Fine-Gained Object Recognition
由于细粒度识别方法通常具有一些共同的特征,因此我们将近年来的文献中的细粒度识别方法分为几个类别。基于部件标注的方法(【9,10】)在这里不做详细的讨论因为通常车辆细粒度分类数据集都没有部件标注。
1)自动部件识别:分类的部分部件可以提供区分度,为细粒度分类任务提供很多信息。然而,假设这些部件位置是已知的是不现实的,因为它需要大量的注释工作。因此,一些论文【2】【3】【11】-【15】试图解决这些问题,并且提出自动部件检测的方法(在训练与测试时)。这些方法的区别主要在于他们用来定位有区分度部件的方式。部件抽取出来的特征通常输入到SVM进行分类。
2)Bilinear Pooling方法:Lin在文献【4】只使用卷积层来提取给双线性分类器分类的特征【16】。Gao在文献【5】中遵循bilinear pooling的方式,提出了一种竞走的bilinear pooling方法,得到了与full bilinear pooling相同的进度且特征数显著降低。
3)其他方法:xie在文献【6】提出使用hyper-class进行数据扩展与细粒度deeplearning。Zhou在文献【7】中使用带有双边图标签利用细粒度标注与粗粒度整体标签(例如轿车、SUV)得到更好的精度。Lin在文献【17】中使用三个神经网络同时进行图像的定位、对齐与分类。三个网络中每个都执行其中的一个任务,之后被连接到一个更大的网络。Yao在文献【13】中提出了一种基于图像随机模板的响应分类方法,利用SVM的响应的综合特征进行分类。Zhang在文献【18】中利用姿态正则化核心与他们的响应包装成特征向量。Chai在文献【19】中提出使用分割算法用于细粒度识别,从而获得图片的前景部分。类似的方法Li在文献【20】中也提了出来;然而,作者使用的是经过针对细粒度识别任务优化与微调过的分割算法。最后Gavves在文献【21】中提出了利用目标proposal获得前景掩模,进行无监督对齐的方法来提升细粒度分类的准确率。
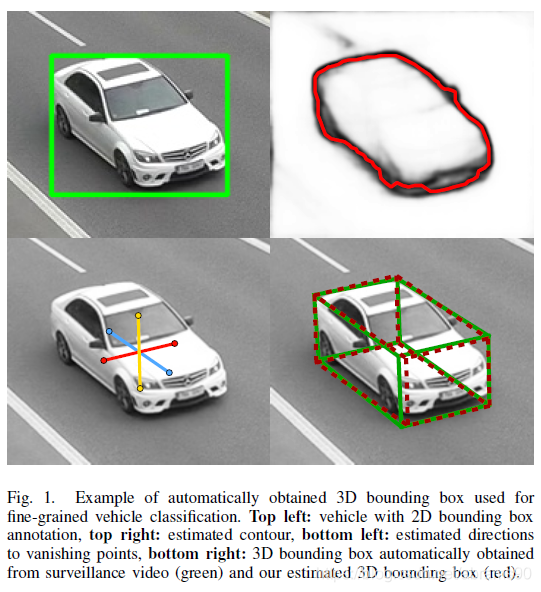
B、Fine-Gained Recognition of Vehicles
车辆细粒度识别的目标是确定车辆的确切类型,即车辆的厂商、车款、车系与年款。识别系统仅仅专注于车辆(与通用细粒度中的鸟与狗等类似)可以从车辆是刚体受益,车辆具有一些独一无二的特征点(例如车牌)与严格的模型(例如3D CAD模型)。
1)限于车辆正面/背面样本的方法:有许多论文【22-29】使用的是常用分类方法:他们检测车上的车牌(作为一个公用的特征点),从车牌周围区域提取特征,且前尾部的车辆区域通常是差异很大的。
也有论文【30-35】直接从前向车辆图片中通过不同方法提取特征,选择性的利用车辆前向结构上的标准部件(例如头灯)。
2)基于3D CAD模型的方法:已经有一些方法利用3D综合模型来处理车辆的视角差异。Lin在文献【36】中提出了联合车辆3D模型拟合与细粒度分类的方法。Hsiao在文献【37】中检测轮廓并使用3D角点匹配3D模型。Krause在问下【38】中提出使用合成数据训练3D模型的几何与与视角分类器,并进行2D图像对齐。Prokaj在文献【39】中提出一种基于离散视点的车辆样本与三维模型的SIFT特征检测方法。
3)其它方法:Gu在文献【40】中提出了一种提取车辆中心的方法,利用bbox的aspect ratio对视角进行粗略估计。然后使用不同外形变化模型来对齐不同视角的数据,使用分割算法进行背景去除。
Stark在文献【41】中提出改进的可形变部件模型(DPM)【42】来处理多类识别问题。,模型通过基于HOG特征【43】的隐藏现行多类SVM构成。作者展示了系统比不同基于线性编码【44】与HOG的方法效果都要好。识别的车辆用于人眼级别的相机校准。
Liu在文献【45】中针对车辆重识别任务采用相对距离,提出使用triplet loss中的Coupled Cluster Loss训练模型。Boonsim在文献【46】提出了夜间车辆细粒度识别的方法。作者利用相对位置与夜间可见特征(灯,车牌)来确定车辆的厂商与车型,这些在车辆
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 378
378




 到【灌水乐园】发言
到【灌水乐园】发言







