




 本文对Linux缺页异常处理源码进行分析与实践。先介绍缺页异常知识,如MMU转换、触发缺页中断的四种情况。接着分析Linux 0.11和5.15源码,0.11源码通过三个if语句处理,5.15涉及do_page_fault等多个函数,为缺页进程分配物理页框。
本文对Linux缺页异常处理源码进行分析与实践。先介绍缺页异常知识,如MMU转换、触发缺页中断的四种情况。接着分析Linux 0.11和5.15源码,0.11源码通过三个if语句处理,5.15涉及do_page_fault等多个函数,为缺页进程分配物理页框。
缺页异常处理源码分析并实践:
本文章是在阅读了相关博客、书本的前提下撰写的,是站在前人的肩膀上对所学内容的汇总,包含了部分个人理解。本文章会放出参考博客的链接。
一、缺页异常知识储备:
CPU访问到的是虚拟地址,通过MMU将虚拟地址转换成物理地址,而MMU上的这种虚拟地址和物理地址的转换关系是需要创建的==(怎么创建?通过触发缺页中断)==,当没有创建一个虚拟地址到物理地址的映射,或者创建了这样的映射,但那个物理页不可写的时候,MMU将会通知CPU产生了一个缺页异常。
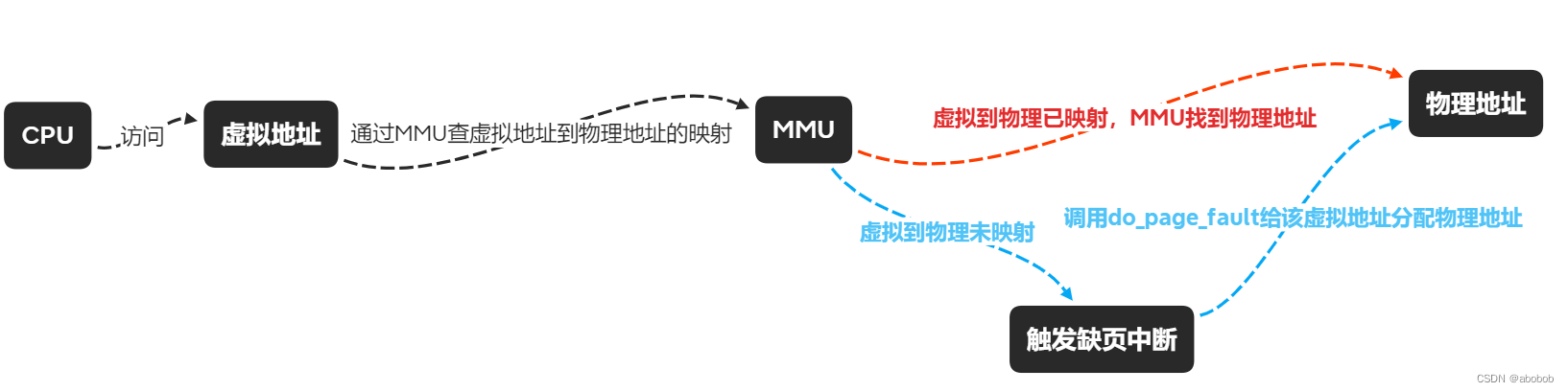
而何时会触发缺页中断呢?在这里可以总结为以下四种情况:
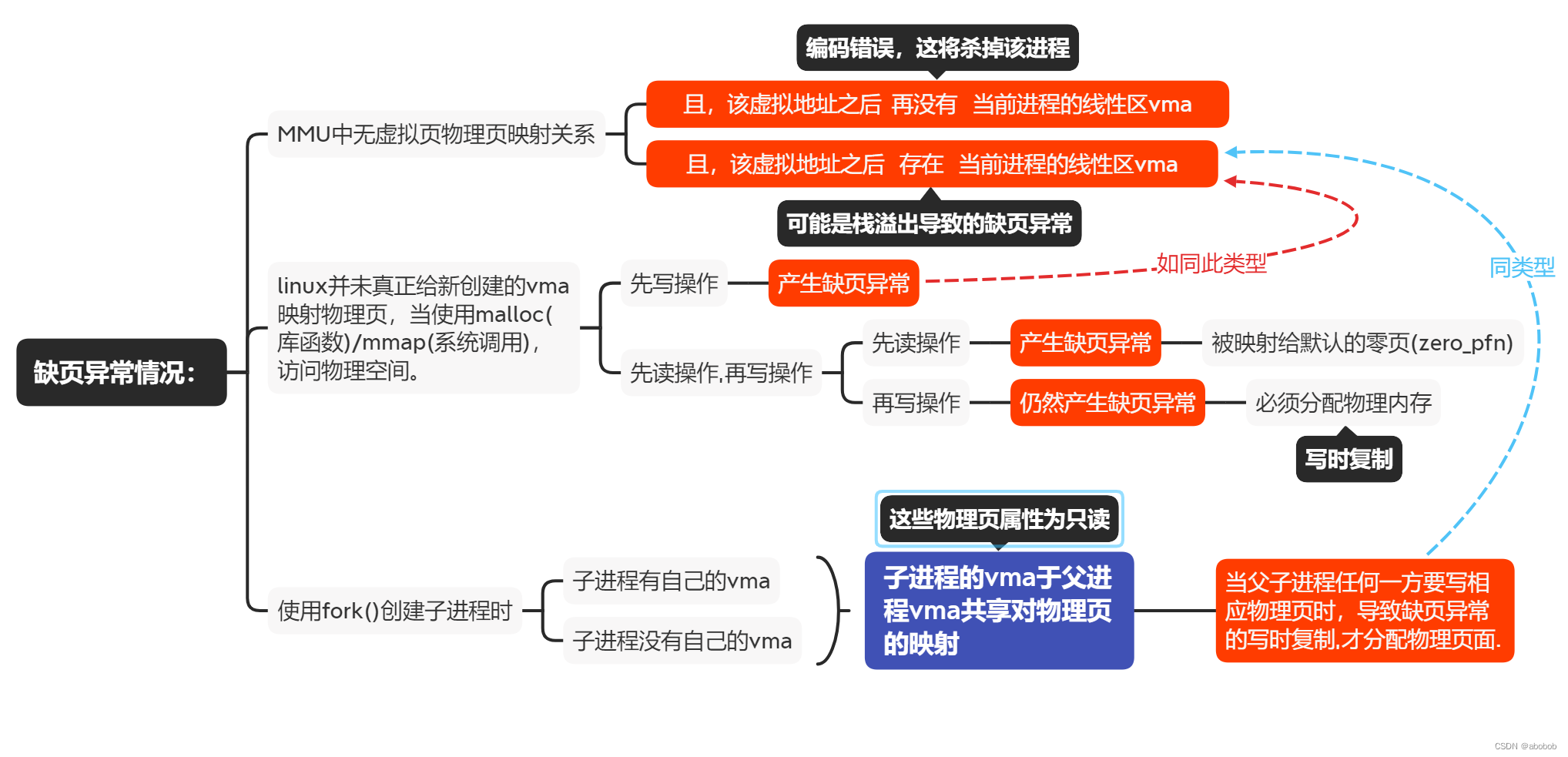
- MMU中无虚拟地址——>物理地址的映射关系;
- linux并未真正给新创建的vma映射物理页,当使用malloc(库函数)/mmap(系统调用),访问物理空间。
- 使用fork()创建子进程后,父子进程任何一方要写相应物理页时,导致缺页异常的写时复制,才分配物理页面。
不到万不得以,Linux是不会轻易交出物理地址的;
本章节参考如下文章:https://zhuanlan.zhihu.com/p/583396235?
二、源码分析:
再有了一定的知识储备后,开始着手对内核中缺页异常源码的阅读和分析,主要是Linux0.11及Linux5.15中源码的分析;
2.1、linux0.11源码分析:
本部分参考了csdn中如下博主的链接:https://blog.youkuaiyun.com/THEANARKH/article/details/100549972?
2.1.1、源码展示:
以下为0.11相关源码的注释几自己理解:
void do_no_page(unsigned long error_code,unsigned long address)
{
int nr[4];
unsigned long tmp;
unsigned long page;
int block,i;
//取得线性地址对应页的页首地址,与0xfffff000即减去页偏移;
address &= 0xfffff000;//线性地址对应页的页首地址
//算出离代码段首地址的偏移;
tmp = address - current->start_code;
// tmp大于等于end_data说明是访问堆或者栈的空间时发生的缺页,直接申请一页
//如果缺页的是堆、栈的空间,则直接分配一页新的物理地址。
if (!current->executable || tmp >= current->end_data) {
get_empty_page(address);//直接申请一页,此时current->end_data > tmp+4kb;
return;
}
// 是否有进程已经使用了
/*否则先判断是否有另一个进程和当前进程使用了同一个执行文件。
是的话,则判断是否可以共享*/
if (share_page(tmp))
return;
/*都不满足,则到硬盘中把一页内容加载到内存中,并且修改页表项内容*/
// 获取一页,4kb
/*get_free_page()从操作系统的内存池中分配一个空闲的物理页或虚拟页
oom 通常是 "Out of Memory" 的缩写,表示内存耗尽的情况。
在这里,它表示系统遇到了内存分配失败,无法继续正常运行。*/
if (!(page = get_free_page()))
oom();
/* remember that 1 block is used for header 一块用于开头*/
/*
算出要读的硬盘块号,但是最多读四块。
tmp/BLOCK_SIZE算出线性地址对应页的
页首地址离代码块距离了多少块,然后读取页首
地址对应的块号,所以需要加一。比如距离2块的距离,则
需要读取的块是第三块
*/
block = 1 + tmp/BLOCK_SIZE;//即当前线性地址对应的逻辑硬盘块号;
for (i=0 ; i<4 ; block++,i++)// 查找文件前4块对应的物理硬盘号
nr[i] = bmap(current->executable,block);// bmap算出逻辑块号对应的物理块号
/*bread_page用于从磁盘上读取一个页面(page)的数据*/
bread_page(page,current->executable->i_dev,nr);
/*
tmp是小于end_data的,因为从tmp开始加载了4kb的数据,
所以tmp+4kb(4096)后大于end_data,所以大于的部分需要清0,
i即超出的字节数
*/
i = tmp + 4096 - current->end_data;//i即超出的字节数
tmp = page + 4096;
// page是物理页首地址,加上4kb,从后往前清0
while (i-- > 0) {
tmp--;
*(char *)tmp = 0;//将 tmp 指针所指的内存位置的值设置为 0
/*首先,tmp 被强制类型转换为 char 指针,
这是因为我们想要将这个位置视为一个字符(1 字节),然后将其值设置为 0。
这通常用于清零内存区域,也可以用于将字符数组的内容清零。*/
}
// 建立线性地址和物理地址的映射
if (put_page(page,address))//当页面不再被需要或引用时,相关的代码会调用put_page()函数来减少页面的引用计数。
return;
// 失败则释放刚才申请的物理页
free_page(page);
oom();
}
2.1.2、0.11源码分析:
- 源码调用关系与分析:

do_no_page是linux0.11源码中用于缺页中断具体处理函数;代码逻辑可以简化为三个if语句:
- ①如果缺页的是堆、栈的空间,则直接分配一页新的物理地址。
- ②否则先判断是否有另一个进程和当前进程使用了同一个执行文件。是的话,则判断是否可以共享。
- ③都不满足,则到硬盘中把一页内容加载到内存中,并且修改页表项内容。
①中主要是使用get_empty_page()函数来直接获得一个新的物理地址,并把页对应的物理地址存储在页面项中。其中通过put_page()函数来建立物理地址和虚拟地址之间的关联;其中get_empty()函数以及put_page()函数的源码分析如下:
- get_empty_page():
/*给address分配一个新的页,并且把页对应的物理地址存储在页面项中*/
void get_empty_page(unsigned long address)
{
unsigned long tmp;
if (!(tmp=get_free_page()) || !put_page(tmp,address)) {
free_page(tmp); /* 0 is ok - ignored */
oom();
}
}
- put_page():
/*
* This function puts a page in memory at the wanted address.
* It returns the physical address of the page gotten, 0 if
* out of memory (either when trying to access page-table or
* page.)
*/
/*page是物理地址,address是线性地址。
建立物理地址和线性地址的关联,即给页表和页目录项赋值*/
unsigned long put_page(unsigned long page,unsigned long address)
{
unsigned long tmp, *page_table;
/* NOTE !!! This uses the fact that _pg_dir=0 */
/*用于检查一个页面(通常是虚拟内存页)的地址是否在合法的内存范围内,
以确保不会出现非法内存访问。*/
if (page < LOW_MEM || page >= HIGH_MEMORY)
printk("Trying to put page %p at %p\n",page,address);
/*mem_map 是一个指向页表的指针数组,
用于跟踪系统中每个页面的状态和分配情况。
当内核需要分配一个物理页面用于存储数据时,
它可以使用 mem_map 来查找空闲页面并标记它们为已分配状态。
当页面不再需要时,内核可以将其标记为空闲,以供将来的分配。*/
/*mem_map 还可以用于建立页帧号(通常是页面在物理内存中的索引)
与实际物理地址之间的映射关系。这对于内核来说是很重要的,
因为它需要知道页面在物理内存中的位置*/
//page对应的物理页面没有被分配则说明有问题;
if (mem_map[(page-LOW_MEM)>>12] != 1)
printk("mem_map disagrees with %p at %p\n",page,address);
/*计算页目录项的偏移地址,页目录首地址在物理地址0处。
这里算出偏移地址后,就是绝对地址,与0xffc即四字节对齐*/
page_table = (unsigned long *) ((address>>20) & 0xffc);
if ((*page_table)&1)// 页目录项已经指向了一个有效的页表;
//算出页表首地址,*page_table的高20位是有效地址
page_table = (unsigned long *) (0xfffff000 & *page_table);
else {
//页目录项还没有指向有效的页表,分配一个新的物理页
if (!(tmp=get_free_page()))
return 0;
//把页表地址写到页目录项,tmp为页表的物理地址,或7代表页面是用户级、可读、写、执行、有效
*page_table = tmp|7;
// 页目录项指向页表的物理地址
page_table = (unsigned long *) tmp;
}
/*
address是32位,右移12为变成20位,再与3ff就是取得低10位,
即address在页表中的索引,或7代表该页面是用户级、可读、写、执行、有效
*/
page_table[(address>>12) & 0x3ff] = page | 7;
/* no need for invalidate */
return page;
}
②中主要是通过share_page()函数来判断当前位置的可执行文件是否与其他进程共享;其代码逻辑是依次判断:
- 当前进程是否有可执行文件;
- 当前进程的可执行文件是否已共享;
- 当前进程的可执行文件已共享,则找到不是当前进程,但执行了该可执行文件的进程,并通过try_to_share()去共享该可执行文件的地址;
以下是两个代码的注释:
- share_page():
/*
* share_page() tries to find a process that could share a page with
* the current one. Address is the address of the wanted page relative
* to the current data space.
*
* We first check if it is at all feasible by checking executable->i_count.
* It should be >1 if there are other tasks sharing this inode.
*/
// 判断有没有多个进程执行了同一个可执行文件
static int share_page(unsigned long address)
{
struct task_struct ** p;
if (!current->executable)//如通过当前进程没有可执行文件,则退出
return 0;
/*i_count 通常是一个表示文件引用计数的字段。
这个字段用于跟踪有多少个进程正在共享同一个文件*/
if (current->executable->i_count < 2)//未共享文件;
return 0;
for (p = &LAST_TASK ; p > &FIRST_TASK ; --p) {
if (!*p)
continue;
if (current == *p)
continue;
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2329
2329

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









