




 本文介绍了数据中台的由来、定义、与传统数仓的区别及其价值。数据中台旨在提高数据共享能力,避免重复计算,助力企业数智化发展。适合建设数据中台的企业通常有大量数据应用场景、存在数据孤岛、面临效率和成本挑战。文章还探讨了阿里3One体系,并概述了数据中台建设的整体架构、元数据管理、指标管理、数据质量控制等方面的关键要素。
本文介绍了数据中台的由来、定义、与传统数仓的区别及其价值。数据中台旨在提高数据共享能力,避免重复计算,助力企业数智化发展。适合建设数据中台的企业通常有大量数据应用场景、存在数据孤岛、面临效率和成本挑战。文章还探讨了阿里3One体系,并概述了数据中台建设的整体架构、元数据管理、指标管理、数据质量控制等方面的关键要素。
目录
1 为什么需要数据中台
1.1 数据中台的由来
随着互联网的高速发展,背后对数据的需求越来越多,数据的应用场景也越来越多。大规模数据的应用,也逐渐暴露出一些问题。业务发展前期,为了快速实现业务的需求,烟囱式的开发导致企业不同业务线,甚至相同业务线的不同应用之间,数据都是割裂的。两个数据应用的相同指标,展示的结果不一致,导致运营对数据的信任度下降。数据割裂的另外一个问题,就是大量的重复计算、开发,导致的研发效率的浪费,计算、存储资源的浪费,大数据的应用成本越来越高。这些问题的根源在于,数据无法共享。
于是乎在2016 年,阿里巴巴率先提出了“数据中台”的口号。2018、2019数据中台在各行业开始不断崛起。数据中台的核心,是避免数据的重复计算,通过数据服务化,提高数据的共享能力,赋能数据应用以及企业的数智化发展。
1.2 数据中台是什么
数据中台是一套“让企业数据用起来”的机制,是一套能持续不断把数据变成资产并服务共享于业务的机制。

数据中台是指通过数据技术,对全域数据(结构化数据和非结构化数据)进行采集汇聚、存储、计算、加工,同时统一数据标准和口径、规范数据质量和安全权限,最终将资产通过服务共享开放出去,进而为客户提供高效服务,赋能各类型的数据应用。
数据中台的宗旨,是避免数据的重复计算,消除数据标准和口径不一致的问题,通过数据服务化,提高数据的共享能力,赋能数据应用,加速企业的数据价值变现。
1.3 数据中台与传统数仓的区别

1.4 数据中台的价值
数据中台改变了企业原来利用数据的形式(传统数仓、BI),通过业务数据化、数据资产化、资产服务化、服务业务化的四化良性高效闭环,加速了从数据资源到数据资产到价值变现的过程,提高了企业的业务响应力、创新力、价值力。通过降本增效,数据化智能运营,打造出数据驱动的智能化企业,从而更高效的为企业创造更多的价值。
2 哪些企业适合做数据中台
不可否认,数据中台的构建需要非常大的投入
一方面数据中台的建设离不开系统支撑,研发系统需要投入大量的人力,而这些系统是否能够匹配中台建设的需求,还需要持续打磨。
另外一方面,面对大量的数据需求,要花费额外的人力去做数据模型的重构,也需要下定决心。
所以数据中台的建设,需要结合企业的现状,根据需要进行选择。我认为企业在选择数据中台的时候,应该考虑这样几个因素:
1、 企业是否有大量的数据应用场景: 数据中台本身并不能直接产生业务价值,数据中台的本质是支撑快速地孵化数据应 用。所以当你的企业有较多数据应用的场景时(一般有3个以上就可以考虑)。
2、 经过了快速的信息化建设,企业存在较多的业务数据的孤岛,需要整合各个业务系统的数据,进行关联的分析,此时,你需要构建一个数据中台。
3、 当你的团队正在面临效率、质量和成本的苦恼时,面对大量的开发,却不知道如何提高效能,数据经常出问题而束手无策,老板还要求你控制数据的成本,这个时候,数据中台可以帮助你。
4、 当你所在的企业面临经营困难,需要通过数据实现精益运营,提高企业的运营效率的时候,你需要构建一个数据中台,同时结合可视化的BI数据产品,实现数据从应用到中台的完整构建,这种类型往往出现在传统企业中。
5、 企业规模也是必须要考虑的一个因素,数据中台因为投入大,收益偏长线,所以更适合业务相对稳定的大公司,并不适合初创型的小公司。

如果你的公司有以上几个特征,基本不要怀疑,请把数据中台提上日程吧。
3 数据中台建设方法论与策略
关于数据中台的建设,目前并没有一个标准的解决方案,也没有一个数据中台能适用于所有的公司,每个公司都应该结合自己的业务规模及数据需求现状来研发适合自己公司的数据中台。阿里是最早提出中台概念的,阿里数据中台的3One建设体系(OneId、OneData、OneService)也成了业界建设数据中台的主要参考方法论,这里我们大概介绍下,并推荐一些建设策略供大家参考。
3.1 阿里3One体系
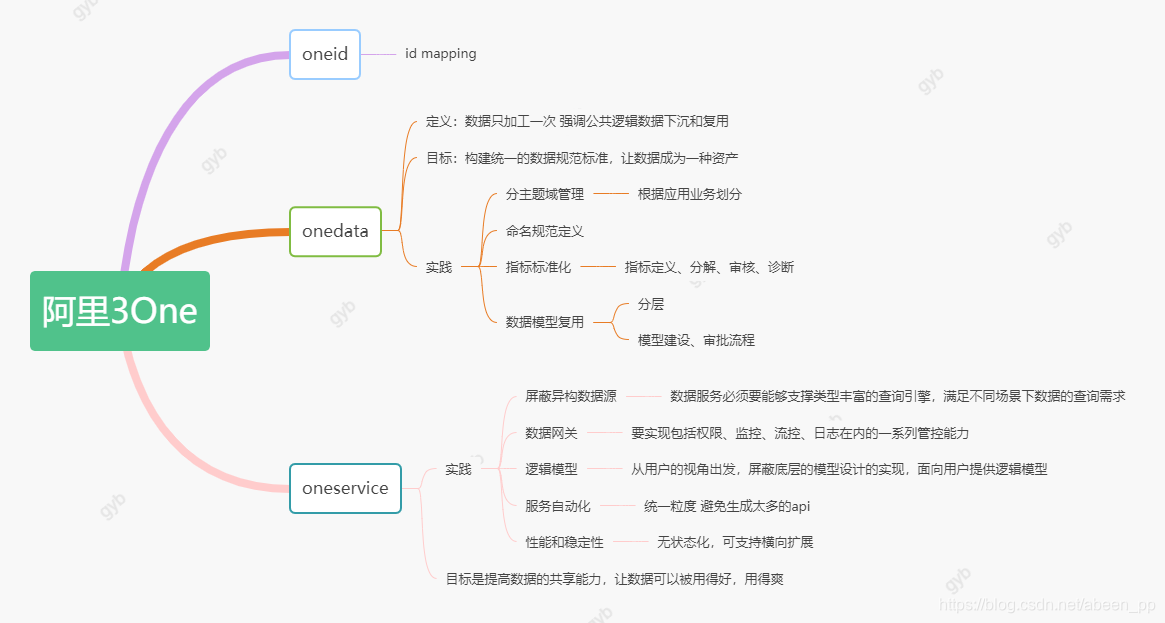
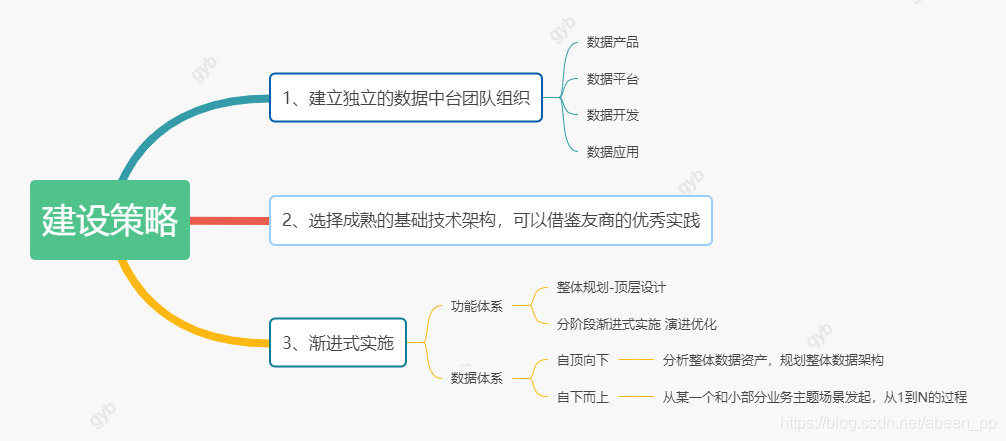
3.2 相关建设策略
4 数据中台建设方案
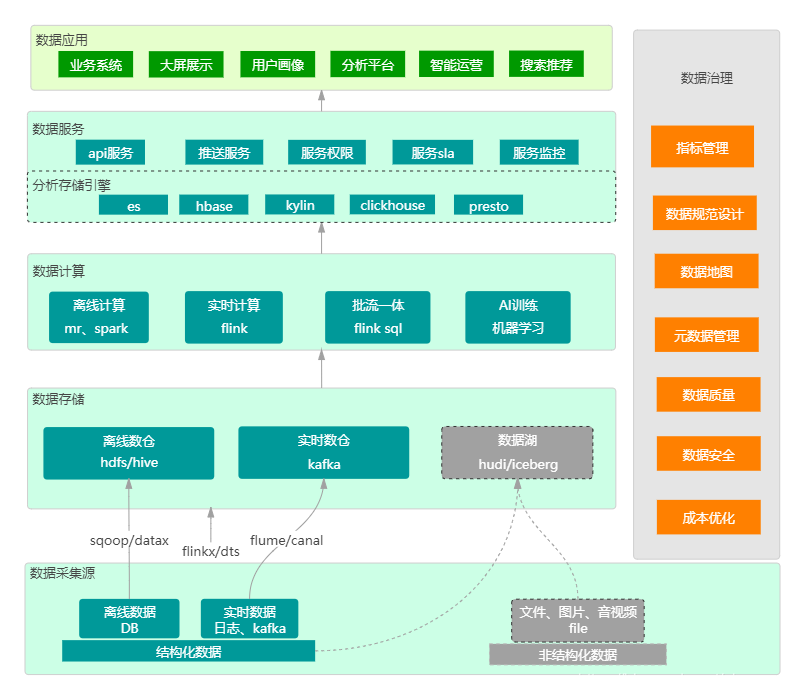
4.1 整体架构
4.2 元数据
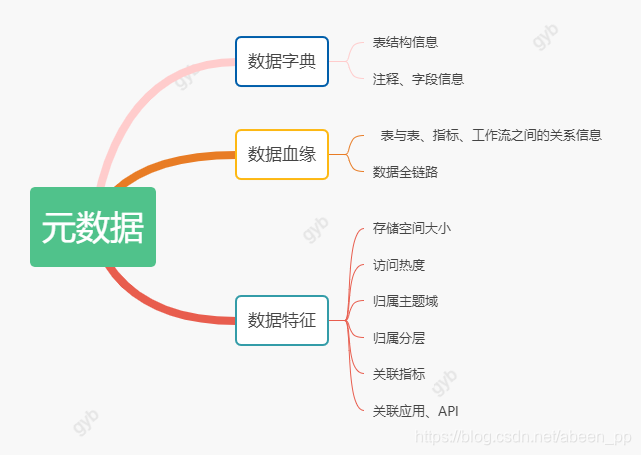
4.2.1 元数据包括哪些
4.2.2 元数据中心整体架构
目前开源方案有:Netflix Metacat(数据字典采集) 、Apache Atlas(数据血缘采集) 。我们设计时可以参考借鉴开源的部分实现思路。
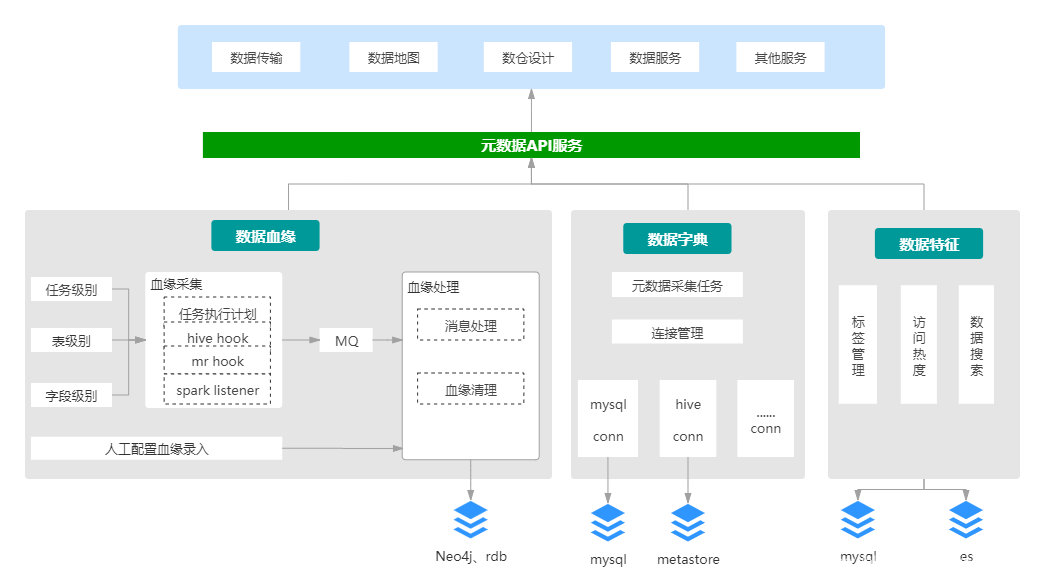
4.3 数据地图
数据地图是基于元数据中心构建的一站式企业数据资产目录,可以看作是元数据中心的界面。数据开发、分析师、数据运营、算法工程师都可以在数据地图上进行数据的检索,解决了“不知道有哪些数据?”“到哪里找数据?”“如何准确的理解数据”的难题。
主要功能有:
1、支持根据标签(主题域、分层信息、指标)、表名、字段名等进行检索;
2、支持表级和字段级检索;
3、数据总览目录 支持按技术资产 业务资产 指标资产等目录进行下砖导览;
4、表详细信息包括表的基础信息,字段信息、分区信息、产出信息以及数据血缘信息等。
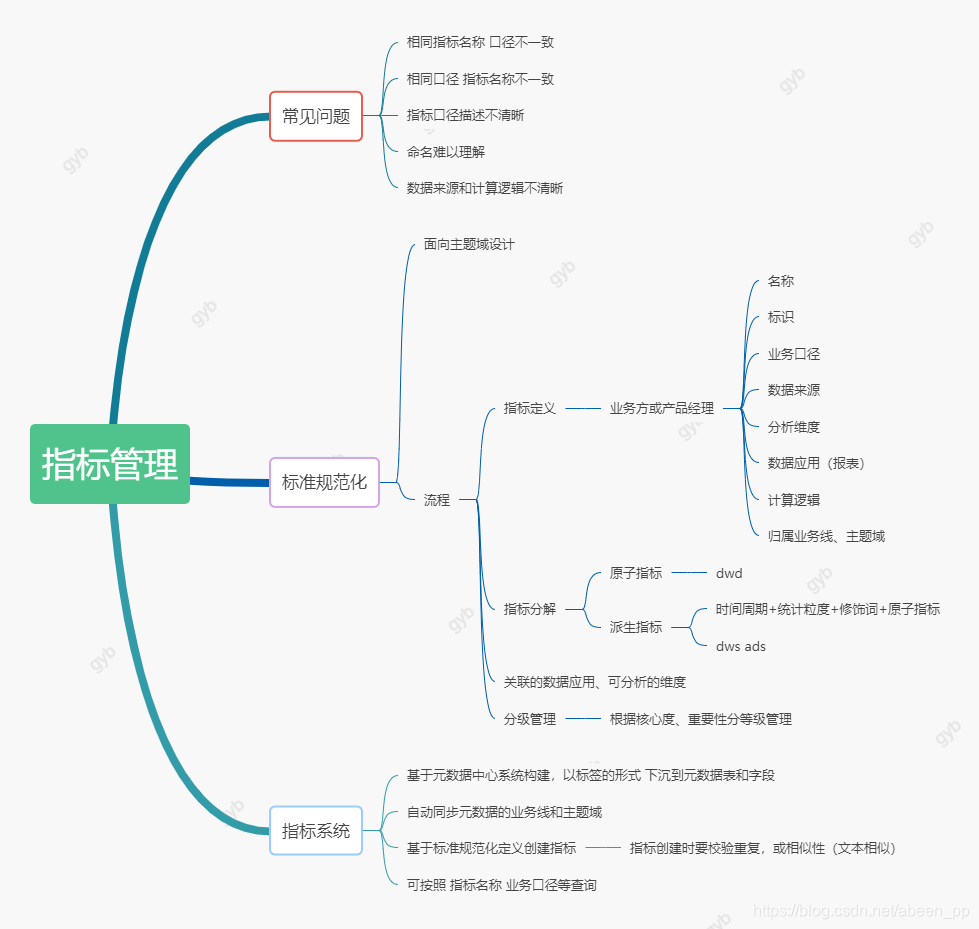
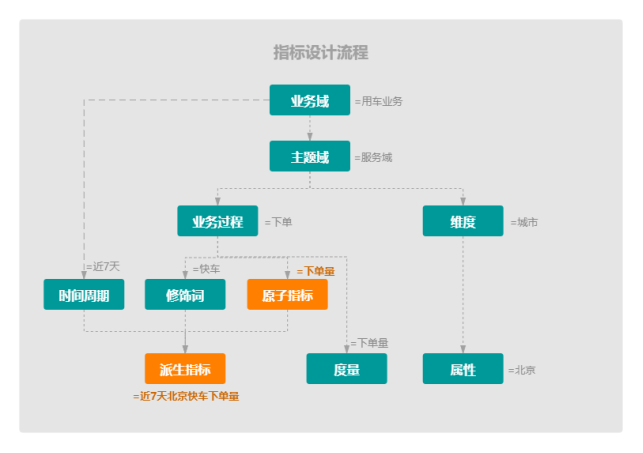
4.4 指标管理
4.5 数据模型规范设计
4.5.1 数仓模型介绍

说明:
1、数据贴源层ODS:基本保持和业务数据源的表结构、表记录数一致,相当于是原始数据的备份;
2、数据公共层CDM:
包括明细层DWD和汇总层DWS,以及公共维度DIM
DWD的明细事实表和DIM的维表数据由ODS层加工而成
DWS一般是公共指标数据,由DWD明细事实表和维表进行汇总加工而成
数据公共层主要采用维度建模方法作为理论基础,更多地采用维度退化手法,将维度退化到事实表中,减少事实表与维表的关联,提高明细数据表的易用性,比如可以将事实表设计为复合结构的宽表;同时在汇总数据层,加强指标的维度退化,采取更多地宽表化手段构建公共指标数据层,提升公共指标的复用性,减少重复加工。主要功能如下:
· 组合相关与相似的数据:数据清理整合、规范化,形成明细宽表,同一份数据要归一(DWD);
· 公共指标统一加工:构建命名规范、口径一致和算法统一的统计指标(DWS);
· 建立一致性维度:建立一致的数据分析维表,降低数据计算口径,算法不一的风险(DIM);
3、数据应用层ADS:存放数据产品应用需要的个性化的统计指标数据,一般不直接作为服务对外提供;
4、要避免跨层调用或逆向调用,如ODS层数据只能被DWD层调用;
4.5.2 表命名规范


4.5.3 涉及相关功能
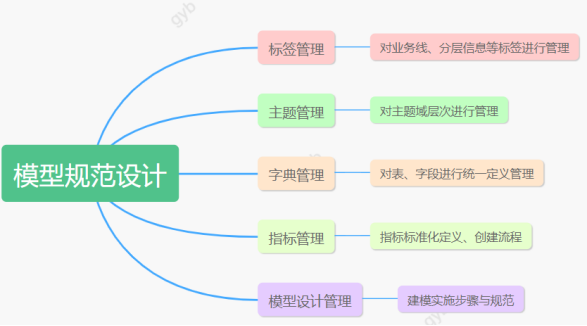
4.5.4 模型设计步骤
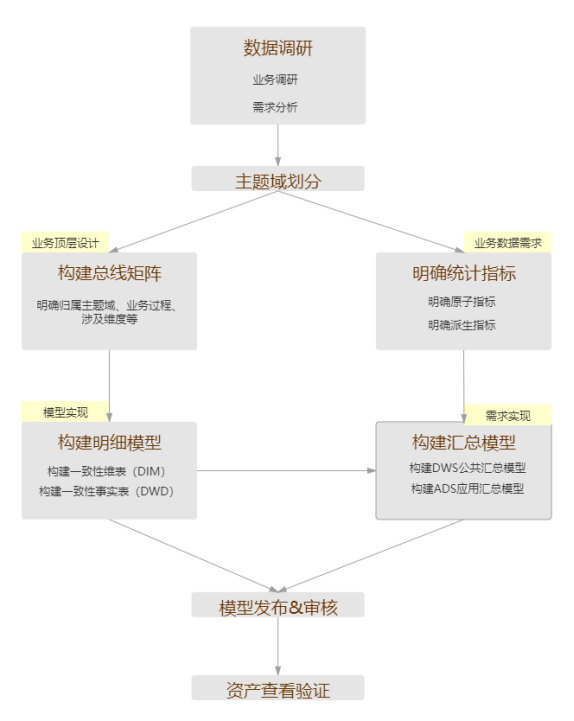
部分流程说明:
1、划分主题域,构建总线矩阵:
主题域是业务过程的抽象集合

构建总线矩阵需要明确每个主题域下有哪些业务过程,业务过程与哪些维度相关,并定义每个主题域下的业务过程和维度。
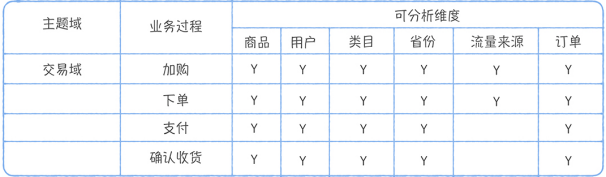
2、模型设计
A)构建一致性维表:
在维度建模中,通常将指标的度量称之为“事实”,将产生度量的环境称之为“维度”。将描述同一个业务实体的的多个维度列组合在一起,就是常说的“维度表”。维度表通常就是指业务过程中的一些基础业务实体信息(比如:商品、用户、时间、区域等),实体的属性 比如商品类别、商品品牌就是维度属性。维度表一般由【代理键、自然键、维度属性】三部分构成。
· 代理键:不具有任何业务含义,仅做维度表数据唯一性区分的属性,通常以主键形式出现,代理键根据场景需要再使用。
· 自然键:具有业务含义,是业务实体一个实例的唯一性区分(如,商品ID),在维度表中不一定做表的主键。

B)构建事实表:

4.6 数据质量
4.6.1 如何提升数据质量
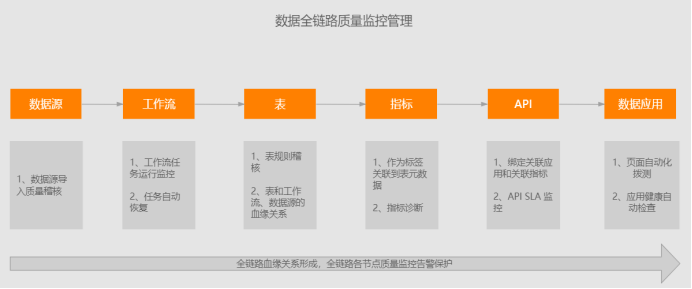
最重要的是能做到:早发现、早恢复,做到数据全链路各环节多层级的质量监控保护体系。
早发现:要能够先于数据使用方发现数据的问题,尽可能在出现问题的源头发现问题,这样就为“早恢复”争取到了大量的时间。
早恢复:要缩短故障恢复的时间,降低故障对数据产出的影响。
一般通过以下的方式去执行:
1、事前定义监控规则
2、事中监控和控制数据生产过程
3、事后分析和问题跟踪闭环
4.6.2 数据质量稽核规则

稽核规则的完整性:优先保障核心指标、核心表、重要工作流的监控,日常再不断完善。
4.6.3 建立全链路数据质量监控
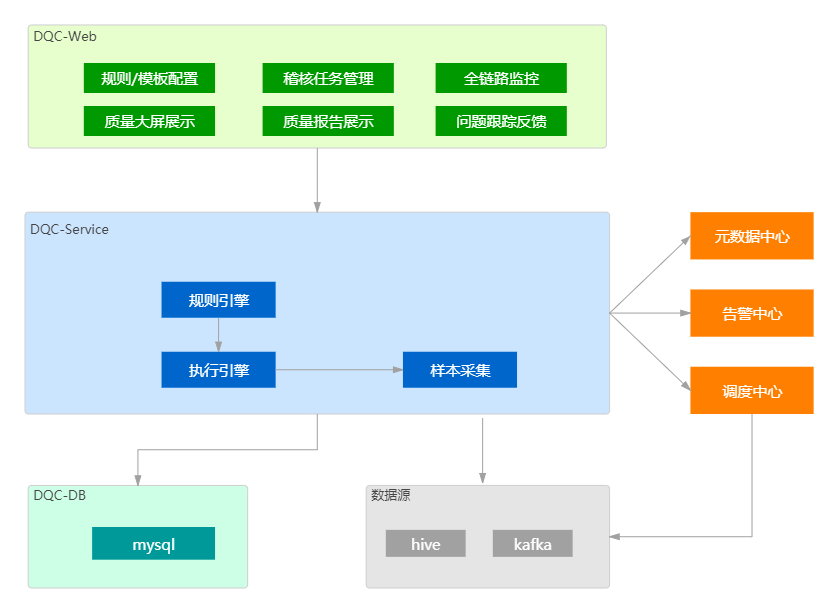
4.6.4 数据质量中心DQC架构
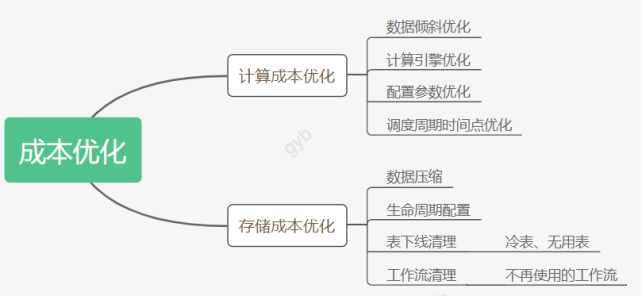
4.7 成本优化
4.8 数据服务
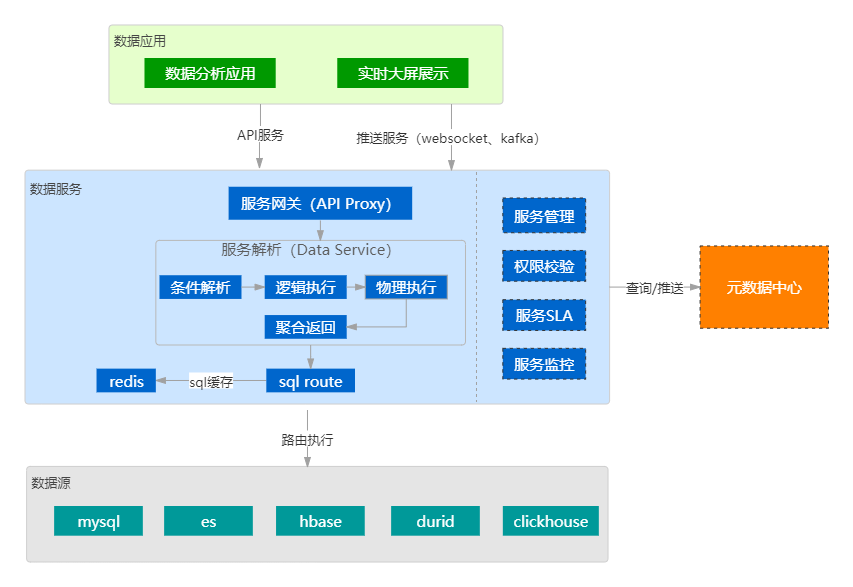
4.8.1 数据服务架构
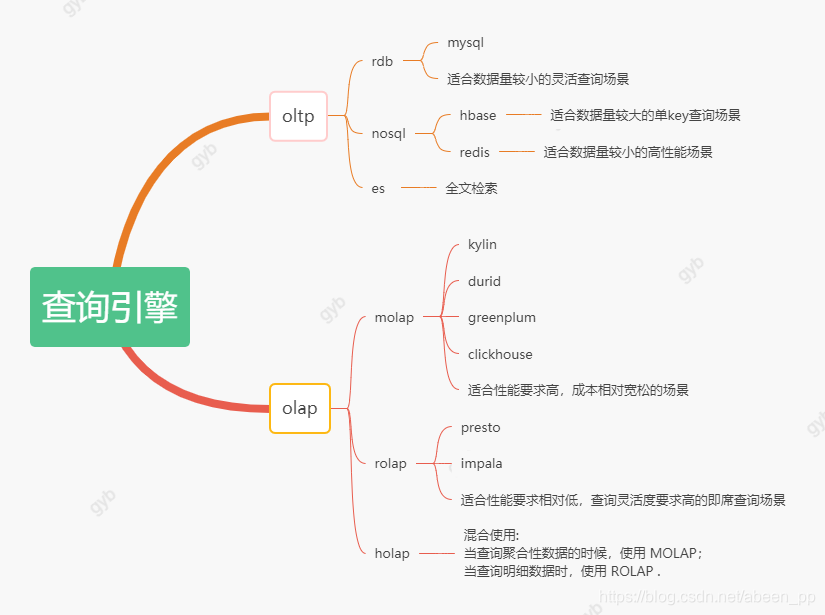
4.8.2 查询引擎选择
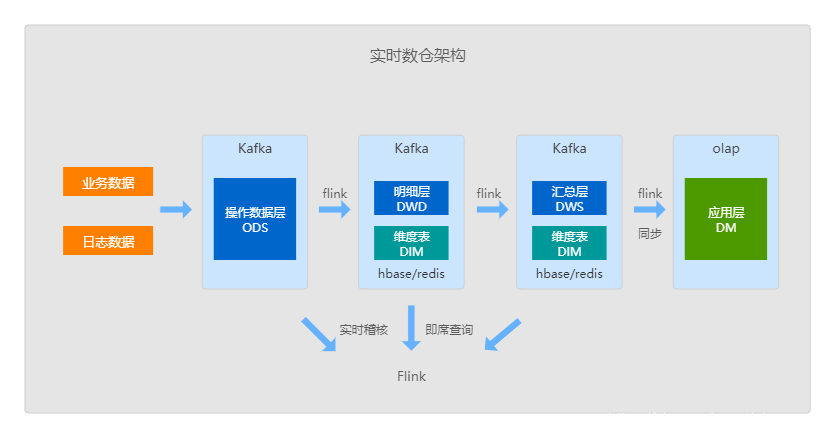
4.9 实时数仓
5 业界数据中台介绍资料
5.1 华为云dayu介绍
华为云智能数据运营平台:https://support.huaweicloud.com/wtsnew-dayu/index.html
5.2 阿里数据中台介绍
Maxcompute:https://help.aliyun.com/product/27797.html?spm=5176.7944453.751670.btn11.2ebc52dfUOpjI7
Dataworks:https://help.aliyun.com/product/72772.html?spm=5176.10695662.881989.3.4da72bf7ggpQpS
Dataworks 公开课 :https://blog.youkuaiyun.com/weixin_34124577/article/details/89590494
Dataworks核心技术讲解:https://yq.aliyun.com/download/2377?do=login&accounttraceid=b05fbf4d1f154cb486c74bc64ed87540pewc
5.3 网易数据中台介绍
网易数据中台实践:https://pan.baidu.com/s/1rXm0F2TvM4dh2TFNg-b4Xg 提取码: 9t3p
5.4 转转数据中台介绍
转转数据中台架构:https://ppt.infoq.cn/slide/show?cid=57&pid=2717


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









