




 本文详细介绍Mycat数据库中间件的读写分离配置及按月分片策略,包括schema.xml与rule.xml的具体设置,实现数据库的高效负载均衡与数据分片。
本文详细介绍Mycat数据库中间件的读写分离配置及按月分片策略,包括schema.xml与rule.xml的具体设置,实现数据库的高效负载均衡与数据分片。
一、下载Mycat源码
github下载地址
https://github.com/MyCATApache/Mycat-Server
下载完成以后用开发工具打开,将pom中报错的插件注释掉
下面将具体介绍如何做读写分离和按月分片配置
二、读写分离配置
做Mycat读写分离之前需要确保Mysql的主从复制已经成功启动
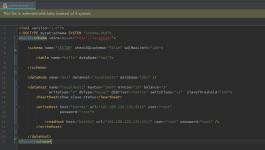
1.schema.xml配置
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100">
<table name="hello" dataNode="dn1"/>
</schema>
<dataNode name="dn1" dataHost="localhost1" database="db1" />
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="3"
writeType="0" dbType="mysql" dbDriver="native" switchType="-1" slaveThreshold="100">
<heartbeat>show slave status</heartbeat>
<writeHost host="hostM1" url="192.168.120.135:3316" user="root"
password="root">
<readHost host="hostS1" url="192.168.120.135:3317" user="root" password="root" />
</writeHost>
</dataHost>
其中 schema标签下
schema标签用于配置mycat的逻辑库,TESTDB就是逻辑库的名称,类似于mysql的database,可以配置多个逻辑库
checkSQLschema 当该值为true时,如执行select * from TESTDB.hello 。mycat会把语句修改为 select * from hello 去掉TESTDB。
sqlMaxLimit 在分库的情况下默认返回最大数量(没有limit语句的时候)
table 标签下
name:逻辑表表名
dataNode:数据节点
dataNode 数据节点标签下
name:数据节点名称
dataHost:数据节点对应的主机名称
database:节点对应的主机上真实数据库
dataHost 标签主要讲下面几个参数:
name:主机名称
balance:
0:不开启读写分离机制,所有读操作都发送到当前可用的writeHost上
1:全部的readHost与stand by writeHost参与select语句的负载均衡,简单的说,当双主双从模式(M1-S1,M2-S2 并且M1 M2互为主备),正常情况下,M2,S1,S2都参与select语句的负载均衡。
2:所有读操作都随机的在writeHost、readHost上分发
3:所有读请求随机的分发到writeHst对应的readHost执行,writeHost不负担读写压力。(1.4之后版本有)
switchType:
-1不自动切换
1 默认值 自动切换
2 基于MySql主从同步的状态决定是否切换
配置balance="3"表示写在hostM1,读在hostS1上,这就实现了主从的读写分离,switchType='-1'意味着当主挂掉的时候,不进行自动切换,即hostS1不会被提升为主,仍只提供读的功能。这就避免了将数据写进slave的可能性
heartbeat 标签表示心跳
writeHost:主库即写库的配置信息
readHost:从库即读库的配置信息
最终配置截图如下:
2.登录mycat
启动Mycat
在server.xml中查看mycat用户名和密码
<user name="root" defaultAccount="true">
<property name="password">123456</property>
<property name="schemas">TESTDB</property>
</user>
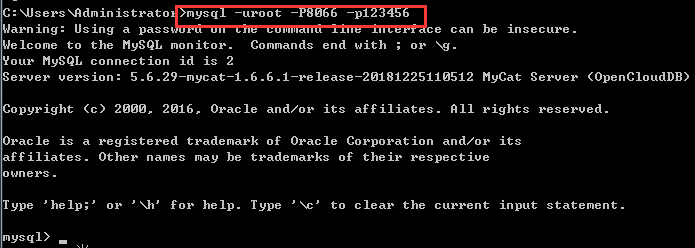
然后在本地打开cmd命令窗口,登录mycat,如图:
切换数据库
use TESTDB
使用show tables;可以看到已经有了一个hello表,但是现在物理数据库还没有创建db1,所以使用desc hello查看表结构会报错:
ERROR 1146 (HY000): Table 'db1.hello' doesn't exist
首先登陆主库,创建数据库db1
create database db1 default charset utf8 collate utf8_general_ci;
然后回到mycat,创建表hello
create table hello (id bigint not null primary key,user_id varchar(100),rpt_time DATE, fee decimal,days int);
表创建成功,此时就可以使用desc hello查看表结构了,而且会发现主库和从库上都已经创建了该表
在mycat插入两条测试数据:
insert into hello(id,user_id,rpt_time,fee,days) values(1,@@hostname,'2019-01-01',100,10);
insert into hello(id,user_id,rpt_time,fee,days) values(5000001,@@hostname,'2019-02-01',100,10);
查询
select * from hello;
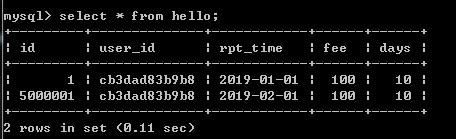
发现并不能验证是从库查询出来的,此时将从库删除一条数据再测,之后记得再次将mysql设置为主从同步
进入从库mysql删除一条sql:
delete from hello where id =1;
再到mycat执行查询操作
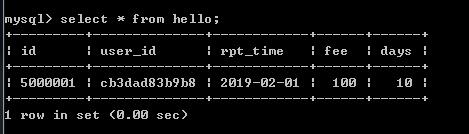
发现现在只能查到一条数据了,因为在从库中id为1的已经被我删除了,说明查询的是从库,读写分离验证成功!
三、按月分片
1.将schema.xml部分配置修改如下:
<table name="hello" primaryKey="id" dataNode="dn$1-12" rule="sharding-by-month" />
其中 table标签下
primaryKey:对应实例数据库中的主键
dataNode="dn$1-12" 表示dn1-dn12的数据节点
rule="sharding-by-month"表示按月分片
dataNode标签下
name="dn$1-12" 表示dn1-dn12的数据节点名称
database="db$1-12"表示对应物理数据库中db1-db12的12个数据库
2.rule.xml分片规则配置文件
<tableRule name="sharding-by-month">
<rule>
<columns>rpt_time</columns>
<algorithm>partbymonth</algorithm>
</rule>
</tableRule>
<function name="partbymonth"
class="io.mycat.route.function.PartitionByMonth">
<property name="dateFormat">yyyy-MM-dd</property>
<!--<property name="sBeginDate">2015-01-01</property>-->
</function>
其中
<columns>rpt_time</columns>表示分片的列名是rpt_time
<property name="dateFormat">yyyy-MM-dd</property>分片的日期格式
注意如果配置了sBeginDate则不能按12个月分库了,会按自然月一直递增,不配置sBeginDate则每个月对应一个库,所以需要12个库与之对应
3.测试分片
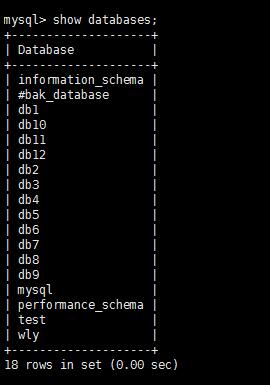
1.在主库中建立db1-db12的12个数据库
重启Mycat
登录mycat
mysql -uroot -p123456 -P8066
切换数据库
use TESTDB
创建表hello
create table hello (id bigint not null primary key,user_id varchar(100),rpt_time DATE, fee decimal,days int);
插入测试数据
insert into hello(id,user_id,rpt_time,fee,days) values(1,@@hostname,'2019-12-31',100,10);
insert into hello(id,user_id,rpt_time,fee,days) values(5000001,@@hostname,'2019-10-01',100,10);
insert into hello(id,user_id,rpt_time,fee,days) values(2,@@hostname,'2018-10-05',100,10);
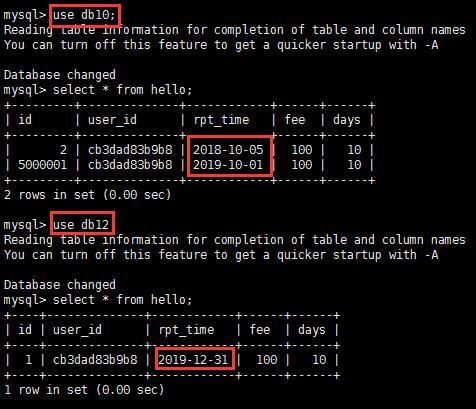
进入主库或者从库查询,发现10月份的数据保存在了db10数据库,12月份的数据保存在了db12数据库,按自然月分片成功!
我的微信公众号



















 1119
1119

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











