




 本文详细介绍了在Python中使用主成分分析(PCA)进行数据降维的过程,包括解决读取数据时的类型转换问题,处理缺失值的方法,以及如何正确计算协方差矩阵和特征值分解。同时,探讨了在不同数据类型下使用特定函数的注意事项。
本文详细介绍了在Python中使用主成分分析(PCA)进行数据降维的过程,包括解决读取数据时的类型转换问题,处理缺失值的方法,以及如何正确计算协方差矩阵和特征值分解。同时,探讨了在不同数据类型下使用特定函数的注意事项。
问题1:
今天在做作业的时,读取文本testSet.txt后,运用map函数将其转换为float型,结果返回迭代器如下
def loadDataSet(fileName, delim='\t'):
fr = open(fileName)
stringArr = [line.strip().split(delim) for line in fr.readlines()]
datArr = [map(float,line) for line in stringArr]
return mat(datArr)
import os
os.chdir(r"E:\learning\algorithm\machine_learning_practice\code\11_pca")
dataMat = loadDataSet("testSet.txt")
map是ptyhon内置的高阶函数,他接收一个函数f和一个list,并通过把函数f依次作用在list的么个元素上,得到一个新的list并返回。
1. 当seq只有一个时,将函数func作用于这个seq的每个元素上,并得到一个新的seq
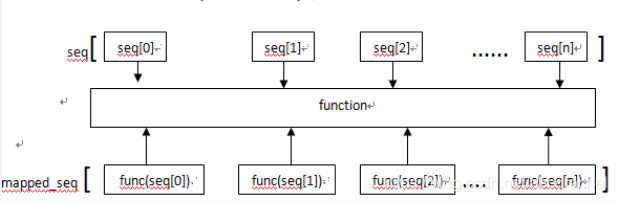
2. 当seq多于一个时,map可以并行地对每个seq执行如下流程:
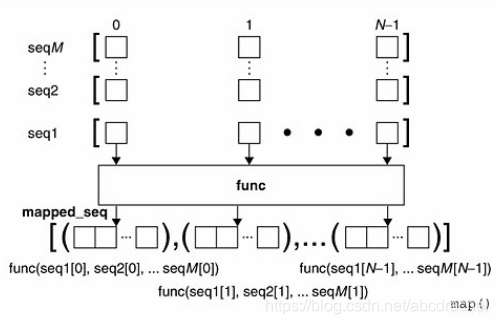
在python2中运用map可以返回列表形式,但在python3中,返回的是一个迭代器,其不可调用。
网上看其他人博客说是可以用list强制转换,就可以返回列表形式,但我进行强制转换后,仍是返回迭代器,被迫只好不用map进行转换转换为float型,即
datArr = [line for line in stringArr]
仅这样改为这样。
问题2 :
但是这样修改后,后面的计算就报错了:
TypeError: cannot perform reduce with flexible type

看了其他博客才知道,原来这样处理后,读出来的数据为字符型,不能进行计算

可以看到dataMat中 dtype = '<U9'。
所以还是需要将数据转换为float型才行,修改如下
def loadDataSet(fileName, delim='\t'):
fr = open(fileName)
stringArr = [line.strip().split(delim) for line in fr.readlines()]
datArr = [line for line in stringArr]
datArr = mat(datArr)
datArr = datArr.astype(float)
return datArr
然后读取的数据即可进行计算了。
知识点1:
covMat = cov(meanRemoved, rowvar=0)
covMat
array([[1.05198368, 1.1246314 ],
[1.1246314 , 2.21166499]])
对给定数据,估计协方差
其中meanRemoved为给定数据,rowvar = 0 表示False,表示每列代表变量,每行代表观测值。
理解协方差矩阵的关键就在于它的计算是不同维度之间的协方差,而不是不同样本之间。
知识点2
eigVals,eigVects = linalg.eig(mat(covMat))
eigVals
Out[69]: array([0.36651371, 2.89713496])
eigVects
Out[70]:
matrix([[-0.85389096, -0.52045195],
[ 0.52045195, -0.85389096]])
计算矩阵的特征值和特征向量
eigVals :特征值; eigVects: 特征向量
问题3
当我直接读半导体数据时,因数据中存在缺失值,则出现下面错误:
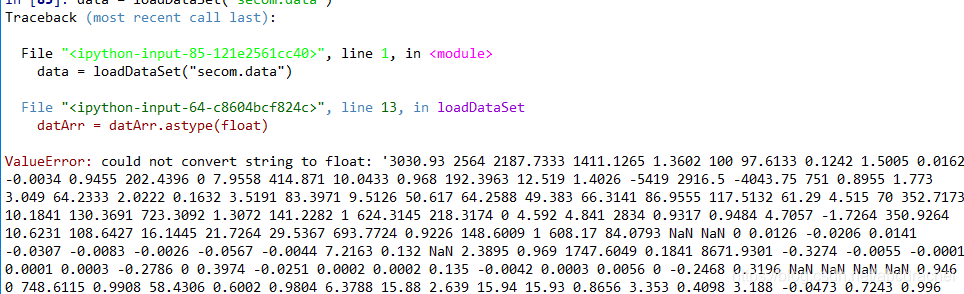
好吧,我只好把读入数据的代码改回原来的形式,但是结果报了如下错误:
TypeError: ufunc 'isnan' not supported for the input types, and the inputs could not be safely coerced to any supported types according to the casting rule ''safe''

我回去查看为啥会这错误时,发现仍然是数据非元素形式,而是一系列迭代器。痛哭!!!
datMat[:,0]
Out[104]: matrix([[<map object at 0x00000252D3B19400>]], dtype=object)
datMat[:,0].A
Out[105]: array([[<map object at 0x00000252D3B19400>]], dtype=object)
~isnan(datMat[:,i].A)
Traceback (most recent call last):
File "<ipython-input-106-3714e7a1ebd1>", line 1, in <module>
~isnan(datMat[:,i].A)
TypeError: ufunc 'isnan' not supported for the input types, and the inputs could not be safely coerced to any supported types according to the casting rule ''safe''
这里很奇怪的是,当我再用修改后的读入数据时,竟然没有报错了。我也是很诧异呀。
最后附上代码
# -*- coding: utf-8 -*-
"""
Created on Mon Jul 1 12:38:48 2019
@author: Rachel
"""
from numpy import *
def loadDataSet(fileName, delim='\t'):
fr = open(fileName)
stringArr = [line.strip().split(delim) for line in fr.readlines()]
datArr = [line for line in stringArr]
datArr = mat(datArr)
datArr = datArr.astype(float)
return datArr
def pca(dataMat, topNfeat=9999999):
meanVals = mean(dataMat, axis=0)
meanRemoved = dataMat - meanVals #remove mean
covMat = cov(meanRemoved, rowvar=0)
eigVals,eigVects = linalg.eig(mat(covMat))
eigValInd = argsort(eigVals) #sort, sort goes smallest to largest
eigValInd = eigValInd[:-(topNfeat+1):-1] #cut off unwanted dimensions
redEigVects = eigVects[:,eigValInd] #reorganize eig vects largest to smallest
lowDDataMat = meanRemoved * redEigVects#transform data into new dimensions
reconMat = (lowDDataMat * redEigVects.T) + meanVals
return lowDDataMat, reconMat
def replaceNanWithMean():
datMat = loadDataSet('secom.data', ' ')
numFeat = shape(datMat)[1]
for i in range(numFeat):
meanVal = mean(datMat[nonzero(~isnan(datMat[:,i].A))[0],i]) #values that are not NaN (a number)
datMat[nonzero(isnan(datMat[:,i].A))[0],i] = meanVal #set NaN values to mean
return datMat
#%%
import matplotlib.pyplot as plt
import os
os.chdir(r"E:\learning\algorithm\machine_learning_practice\code\11_pca")
dataMat = loadDataSet("testSet.txt")
lowDmat,reconMat = pca(dataMat,1)
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(dataMat[:,0].flatten().A[0],dataMat[:,1].flatten().A[0],marker="^",s=90)
ax.scatter(reconMat[:,0].flatten().A[0],reconMat[:,1].flatten().A[0],marker="o",s=50,c="red")
#lowDmat,reconMat = pca(dataMat,2)
#%%
datMat = replaceNanWithMean()


















 853
853

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









