



一、选择好自己的镜像租用
二、开启成功后,点击jupyterlab
三、将压缩包上传到sutodl-dmp文件夹下:
然后在命令行中依次输入以下指令安装zip和unzip。
apt-get update && apt-get install -y zip
apt-get update && apt-get install -y unzip
解压缩文件夹
1.把文件解压到当前目录下
1.把文件解压到当前目录下
unzip test.zip
2.如果要把文件解压到指定的目录下,需要用到-d参数
unzip -d /temp test.zip
3. 解压的时候,有时候不想覆盖已经存在的文件,那么可以加上-n参数
unzip -n test.zip
unzip -n -d /temp test.zip
4. 只查看一下zip压缩包中包含哪些文件,不进行解压缩
unzip -l test.zip
5. 查看显示的文件列表还包含压缩比率
unzip -v test.zip
6. 检查zip文件是否损坏
unzip -t test.zip
7.将压缩文件test.zip在指定目录下解压缩,如果已有相同的文件存在,要求unzip命令覆盖原先的文件
unzip -o test.zip -d /temp
四、替换数据集
五、在终端中激活虚拟环境
source activate base
若想使用conda激活虚拟环境的话,直接使用会出现以下问题:
在执行 conda activate base 命令时遇到了 CommandNotFoundError 错误,这表明你的 shell 尚未正确配置以使用 conda activate 命令。Conda 需要对 shell 进行初始化设置,之后才能使用 conda activate 来激活环境。
步骤 1:初始化 shell
你需要使用 conda init 命令来初始化你的 shell。依据你所使用的 shell 类型,选择对应的初始化命令:
若使用的是 bash 或 zsh
在终端输入以下命令:
conda init bash
步骤 2:关闭并重新打开终端
在执行 conda init 命令之后,你得关闭当前的终端窗口,然后重新打开一个新的终端,这样新的配置才能生效。
步骤 3:再次尝试激活环境
在新的终端中,再次尝试执行以下命令来激活 base 环境:
conda activate base
六、进入到解压后的文件夹,找到requirements.txt文件
在终端输入:
pip install -r requirements.txt
七、更改绝对路径
八、更改完成后,在pycharm中相应文件下运行train_final.py即可。
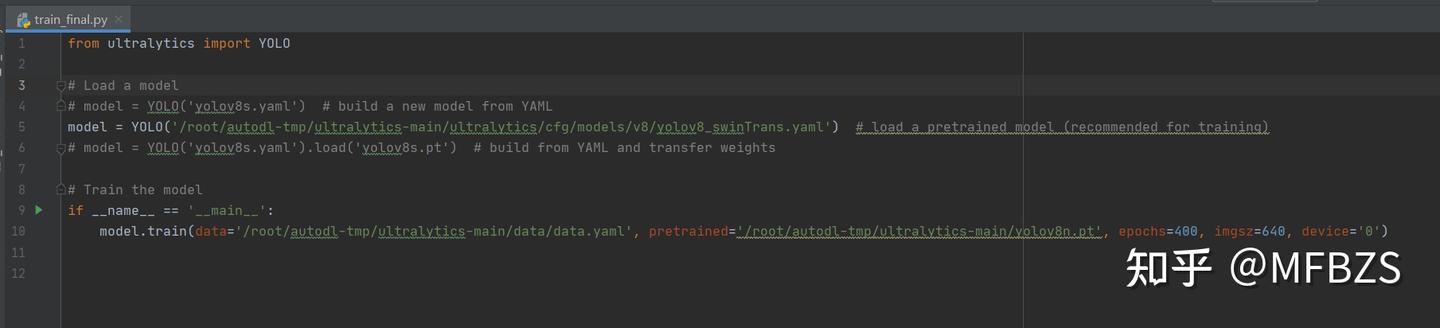
或者也可直接在autodl终端中运行:
python train.py
九、导出文件:比如我想导出最近的一次执行结果的文件
zip -r autodl-tmp/ultralytics-main/runs/detect/train26.zip autodl-tmp/ultralytics-main/runs/detect/train26

















 1633
1633

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









