







 本文介绍了Boosting提升法的基本原理及其运作流程。通过迭代过程自适应改变训练样本分布,使基分类器聚焦于难以分类的样本。文章详细解释了如何为每个训练样本分配权重,并在每次迭代后调整这些权重,以确保后续分类器能够更加关注之前分类错误的样本。
本文介绍了Boosting提升法的基本原理及其运作流程。通过迭代过程自适应改变训练样本分布,使基分类器聚焦于难以分类的样本。文章详细解释了如何为每个训练样本分配权重,并在每次迭代后调整这些权重,以确保后续分类器能够更加关注之前分类错误的样本。
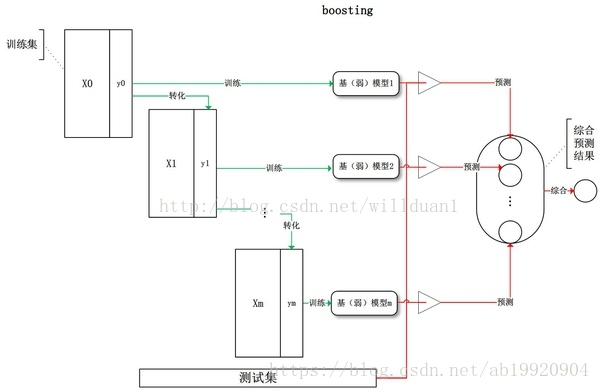
Boosting 提升法
1. boosting是一个迭代的过程,用于自适应地改变训练样本的分布,使得基分类器聚焦在那些很难分的样本上。
2. boosting会给每一训练样本赋予一个权值,而且可以在每轮提升过程结束时自动地调整权值。开始时,所有的样本都赋予相同的权值1/n,从而使得它们被选作训练的可能性都是一样的。根据训练样本的抽样分布来抽取样本,得到新的样本集。然后,由该训练集归纳一个分类器,并用它对原始数据集中的所有样本进行分类。每轮提升结束时,更新训练集样本的权值。增加被错误分类的样本的权值,减小被正确分类的样本的权值,这使得分类器在随后的迭代中关注那些很难分类的样本,

















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









