



 这篇博客详细记录了如何将动漫人脸检测的txt数据集转换为所需格式,包括txt之间的格式转换、txt拆分为多个文件以及txt转为YOLO所需的XML标注文件。过程中涉及Python的文件读写操作,如使用seek()和truncate()实现文件内容覆盖,以及批量重命名文件的方法。
这篇博客详细记录了如何将动漫人脸检测的txt数据集转换为所需格式,包括txt之间的格式转换、txt拆分为多个文件以及txt转为YOLO所需的XML标注文件。过程中涉及Python的文件读写操作,如使用seek()和truncate()实现文件内容覆盖,以及批量重命名文件的方法。
txt、csv、YOLO数据集的转化
在做动漫的人脸检测时,其中用的是labellmg标注的xml文件,我自己找的是txt文件,并且格式也不符合要求,今天做了一下转化,记录如下:
一、txt文本的一些操作
示例:名为origin2one.py的文件,主要任务是将已有的txt数据集转为想要的格式
转化前格式:

转化后:

其中前四个是xmin,ymin,xmax,ymax,最后是标签label(猪爸爸)
代码如下:
import numpy as np
if __name__ == '__main__':
old = ""
new = ""
i = 0
with open('data/test.csv', 'r+', encoding='utf-8') as filetxt:
lines = filetxt.readlines()
lineuses = ""
filetxt.seek(0)
for line in lines:
line = line.strip('\n')
tmp = "personai_icartoonface_rectrain_05012/personai_icartoonface_rectrain_05012_" + "{0:0>7}".format(str(i)) +".jpg,"
i += 1
old = tmp
lineuses = lineuses + "".join(line).replace(old, new) + ',pigFa\n'
filetxt.truncate()
filetxt.write("".join(lineuses))
""""
在使用Python进行txt文件的读写时,当打开文件后,首先用read()对文件的内容读取,然后再用write()写入,这时发现虽然是用“r+”模式打开,按道理是应该覆盖的,但是却出现了追加的情况。
这是因为在使用read后,文档的指针已经指向了文本最后,而write写入的时候是以指针为起始,因此就产生了追加的效果。
如果想要覆盖,需要先seek(0),然后使用truncate()清除后,即可实现重新覆盖写入
"""
二、txt文本的进一步操作
示例:名为one2multi.py的文件,主要任务是将已有的一个txt数据集按行转为多个txt文件(因为后续需要)
之前格式:
之后格式:
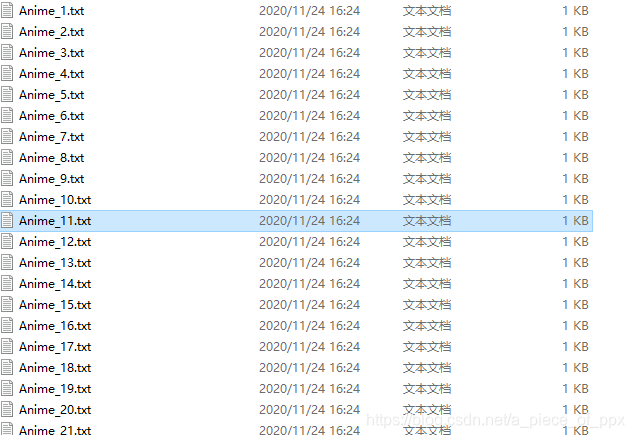

代码如下:
import os
if __name__ == '__main__':
f = open("C:/Users/He Xiang/PycharmProjects/pythonProject2/data/test(2).txt", "r")
lines = f.readlines()
i = 1
for line in lines:
with open("C:/Users/He Xiang/PycharmProjects/pythonProject2/result/Anime_"+str(i) + ".txt", "a") as mon:
mon.write(line)
i = i + 1
三、txt文本转为xml文件
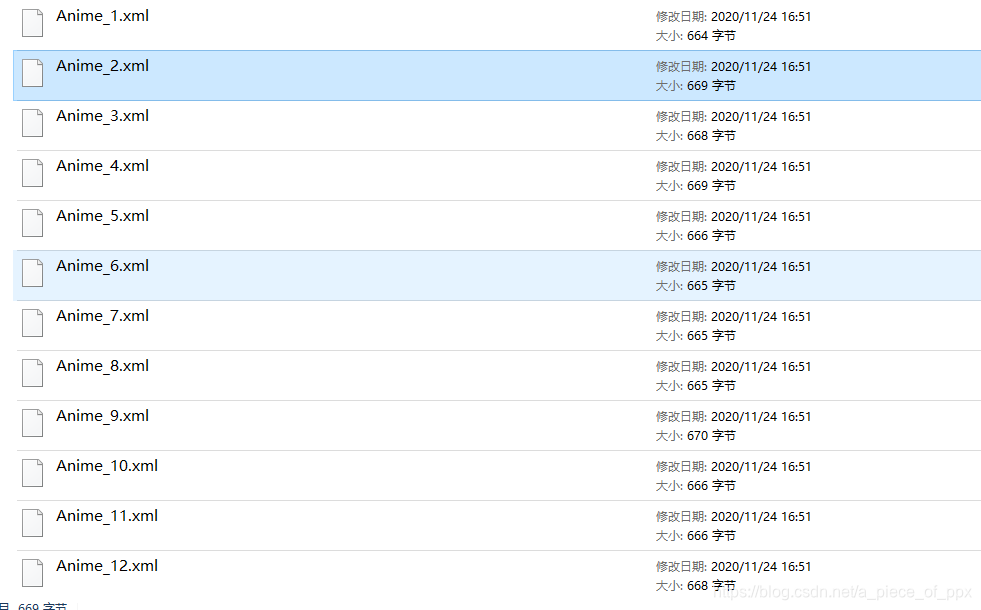
示例:名为main.py的文件,主要任务是将已有的一个txt数据集转为目标检测所需的xml文件
转化前:

之后:

代码如下:
import os
import cv2
headstr = """\
<annotation>
<folder>images</folder>
<filename>%s</filename>
<path>D:/dataset/images/%s</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>%d</width>
<height>%d</height>
<depth>%d</depth>
</size>
<segmented>0</segmented>
"""
objstr = """\
<object>
<name>%s</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>%d</difficult>
<bndbox>
<xmin>%d</xmin>
<ymin>%d</ymin>
<xmax>%d</xmax>
<ymax>%d</ymax>
</bndbox>
</object>
"""
tailstr = '''\
</annotation>
'''
def save_annotations(boxes,img,filename):
H,W,C = img.shape
img_name = filename.split('.')[0] + '.jpg'
head = headstr % (img_name,img_name,W,H,C) #写入头文件
tail = tailstr # 写入尾文件
# 写入boxes
save_path = anno_path + filename.split('.')[0] + '.xml'
f = open(save_path,'w')
f.write(head)
for box in boxes:
f.write(objstr % (box[4],0,int(box[0]),int(box[1]),int(box[2]),int(box[3])))
f.write(tail)
if __name__ == '__main__':
# 设置路径
root_path = 'D:/dataset/'
total_label_path= root_path + 'label/' # txt存储的路径
total_img_path =root_path + 'images/' # 图像存储路径
anno_path = root_path + 'Annotations/' # 存储生成的xml标注文件
# 判断当前路径下是否存在Annotations这个文件夹,若不存在,自动创建一个
if not os.path.exists(anno_path):
os.mkdir(anno_path)
# 逐个读取txt标注文件
for filename in os.listdir(total_label_path):
cur_label_path = total_label_path + filename
cur_img_path = total_img_path + filename.split('.')[0] + '.jpg' # 换一下文件名后缀
cur_boxes=[]
#读取当前txt文件中的内容
with open(cur_label_path,'r') as file:
while True:
line = file.readline().strip() #.strip()用来去掉'\r,\n'
if not line:
break
line_list = [ele for ele in line.split(',')]
cur_boxes.append(line_list)
# 读取当前图像
cur_img = cv2.imread(cur_img_path)
# 进行xml文档存储
save_annotations(cur_boxes,cur_img,filename)
最后结果:


















 1284
1284

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









