






最近遇到一个需求,管理员可以在后台把商品列表中的某个商品拖动到新的位置,比如插入到任意两个商品中间、拖到第一位或者最后一位。网上搜了下实现方案,大概有几种:
1. 位置值(Position Value)
实现方式:为每个元素分配一个整数位置值(如 sort_order),按升序排列表示顺序。
更新逻辑:当元素被拖动到新位置时,前端将新顺序的元素 ID 和位置值批量发送到后端。后端根据新位置值更新数据库中的 sort_order 字段。
优点:简单直观,适合数据量较小的场景。
缺点:元素位置变化时需批量更新后续所有元素的位置值,效率较低。
2. 链表结构(Linked List)
实现方式:每个元素记录前驱(prev_id)和后继(next_id)的 ID,形成链表结构。
更新逻辑:当元素移动时,只需修改其前驱和后继的指针,以及相邻元素的指针。
优点:插入/删除操作高效,无需批量更新。
缺点:查询时需遍历链表,复杂场景下需额外处理
3. 排序权重(Sort Weight)
实现方式:使用浮点数作为权重(如 sort_weight),允许在现有元素之间插入新位置。
更新逻辑:初始分配整数权重(如 1, 2, 3)。拖动元素时,新权重设为相邻元素的中间值(如拖动元素 A 到元素 B 和 C 之间,权重为 (B.weight + C.weight)/2)。
优点:无需重新排列所有元素,支持动态插入。
缺点:浮点数精度问题,需定期重新索引。
方法1仅适合数据量较小的场景。方法2的链表适合内存操作,不适合磁盘存储,底层数据如果是在磁盘型数据库中,就需要额外维护一层缓存。方法3的排序权重取中值法挺方便的,但是在同一位置不限次插入新元素后,就会触及浮点数精度上限。
于是我设计了一种具有无限精度的字符串生成算法。
字符串的大小比较规则是:从头到尾依次比较每个字符的编码值,如果不相等则区分出了大小,如果相等则继续比较下一个字符,如果一个字符串先结束了,则较短的字符串小于较长的字符串。
因此可以用26个字母生成排序权重字段,字段的初始长度根据需求自定义,比如取8,那取值范围就是‘aaaaaaaa’到‘zzzzzzzz’(26^8约等于2000亿)。代码如下(go语言):
const (
minStr = "aaaaaaaa"
minStrLen = len(minStr)
)
func calcNextSort(sort string) string {
bsort := []byte(sort)
l := len(bsort)
if l < minStrLen {
bsort = append(bsort, minStr[l:]...)
} else if l > minStrLen {
bsort = bsort[:minStrLen]
}
// 第minStrLen个字符的值加一
bsort[minStrLen-1] += 1
if bsort[minStrLen-1] == 'z'+1 {
bsort[minStrLen-1] = 'a'
for i := minStrLen - 2; i >= 0; i-- {
bsort[i] += 1
if bsort[i] != 'z'+1 {
break
} else {
bsort[i] = 'a'
}
}
}
// 去掉末尾的a
for i := minStrLen - 1; i >= 0; i-- {
if bsort[i] == 'a' {
bsort = bsort[:i]
} else {
break
}
}
return string(bsort)
}
在两个元素中间插入时,新元素的排序权重值就是相邻两个元素权重值的中间值。如果字符串的长度不限,那这里就可以无限取中间值。代码如下:
func calcMiddleSort(small, big string) string {
if small == big {
return small
}
if small > big {
small, big = big, small
}
bsmall, bbig := []byte(small), []byte(big)
ls, lb := len(small), len(big)
l := ls
// 末尾追加'a',使其长度相等
if ls > lb {
for i := 0; i < ls-lb; i++ {
bbig = append(bbig, 'a')
}
} else if ls < lb {
l = lb
for i := 0; i < lb-ls; i++ {
bsmall = append(bsmall, 'a')
}
}
var intMiddle []int
carry := 0
// 求中间值
for i := 0; i < l; i++ {
sum := int(bsmall[i]) + int(bbig[i]) + carry
mid := sum / 2
intMiddle = append(intMiddle, mid)
reminder := sum % 2
if reminder == 1 {
carry = 26
} else {
carry = 0
}
}
if carry != 0 {
intMiddle = append(intMiddle, ('a'+'z')/2)
}
carry = 0
// 把中间值转成字母,处理进位
for i := len(intMiddle) - 1; i >= 0; i-- {
intMiddle[i] += carry
if intMiddle[i] > 'z' {
carry = (intMiddle[i] - 'a') / 26
intMiddle[i] = 'a'
} else {
carry = 0
}
}
bmiddle := []byte{}
for i := 0; i < len(intMiddle); i++ {
bmiddle = append(bmiddle, byte(intMiddle[i]))
}
// 保留最多2位不同字符,降低精度,以免字符串过长
diffCount := 0
for i := 0; i < l; i++ {
if bsmall[i] != bmiddle[i] {
diffCount++
}
if diffCount == 2 {
bmiddle = bmiddle[:i+1]
break
}
}
// 去掉末尾的a
for i := len(bmiddle) - 1; i >= 0; i-- {
if bmiddle[i] == 'a' {
bmiddle = bmiddle[:i]
} else {
break
}
}
return string(bmiddle)
}
测试一下效果:
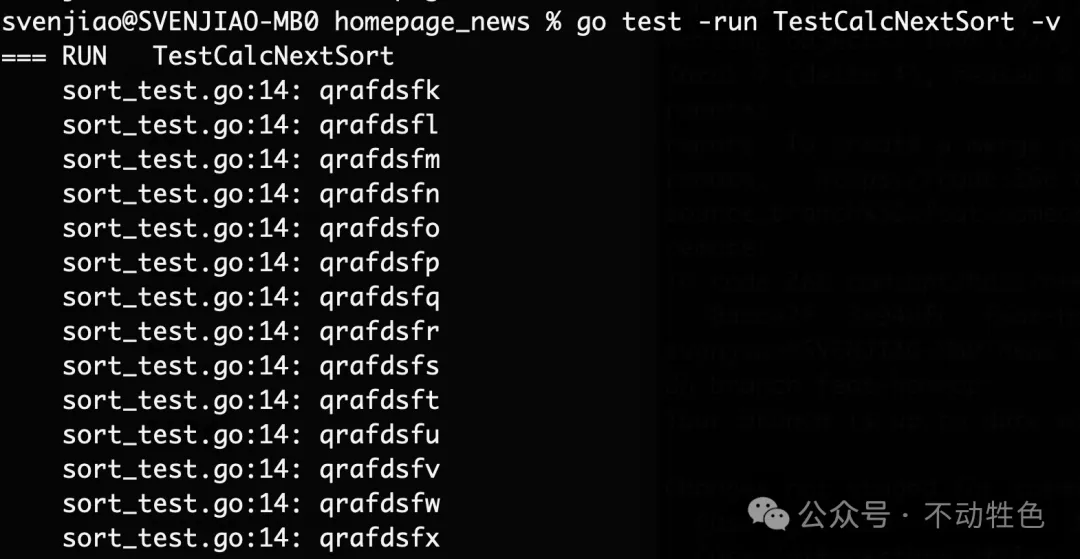
func TestCalcNextSort(t *testing.T) {
// init := "faj"
// init := "fafddsfd"
init := "qrafdsfjfjfjadskfj"
for i := 0; i < 100000000; i++ {
next := calcNextSort(init)
t.Log(next)
init = next
}
}
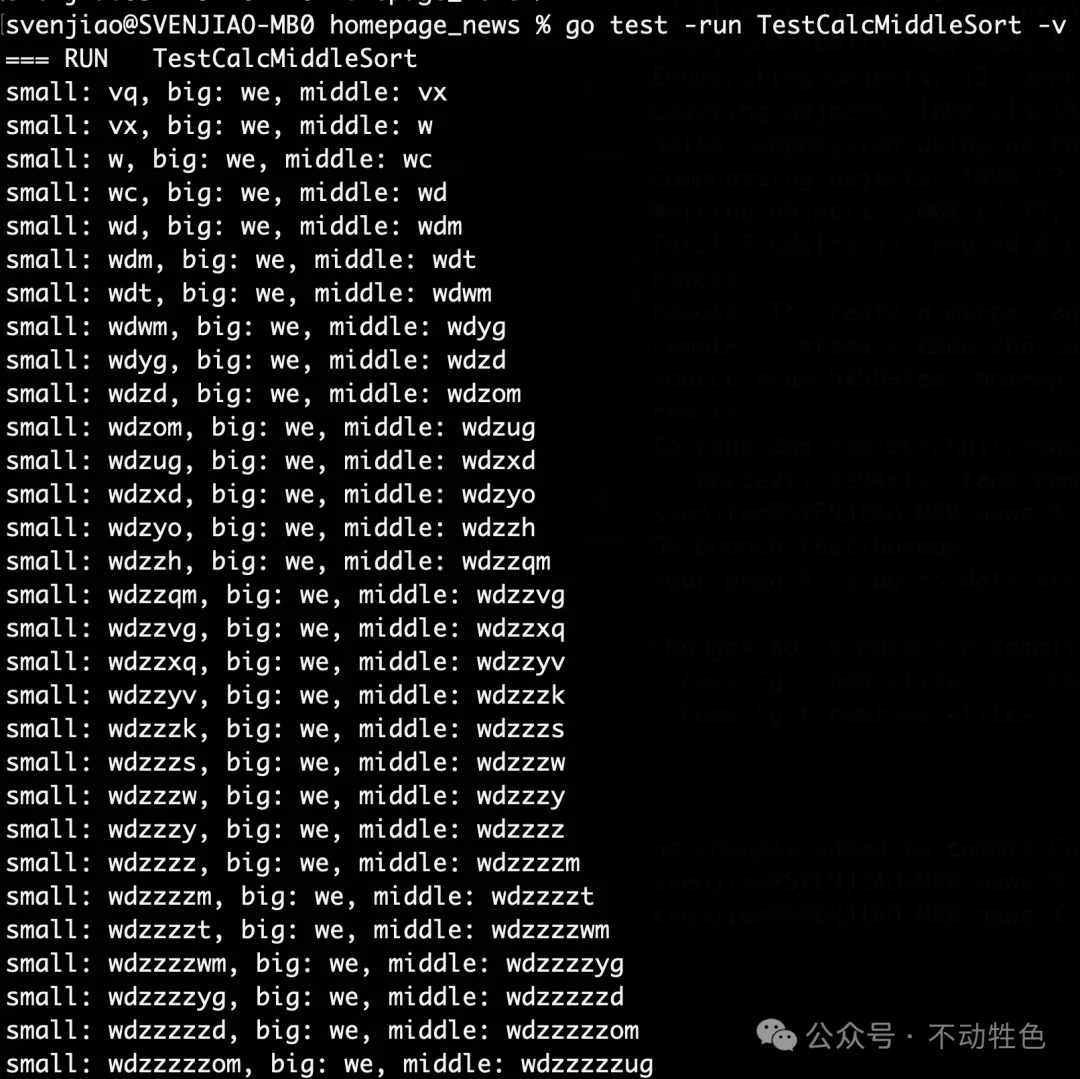
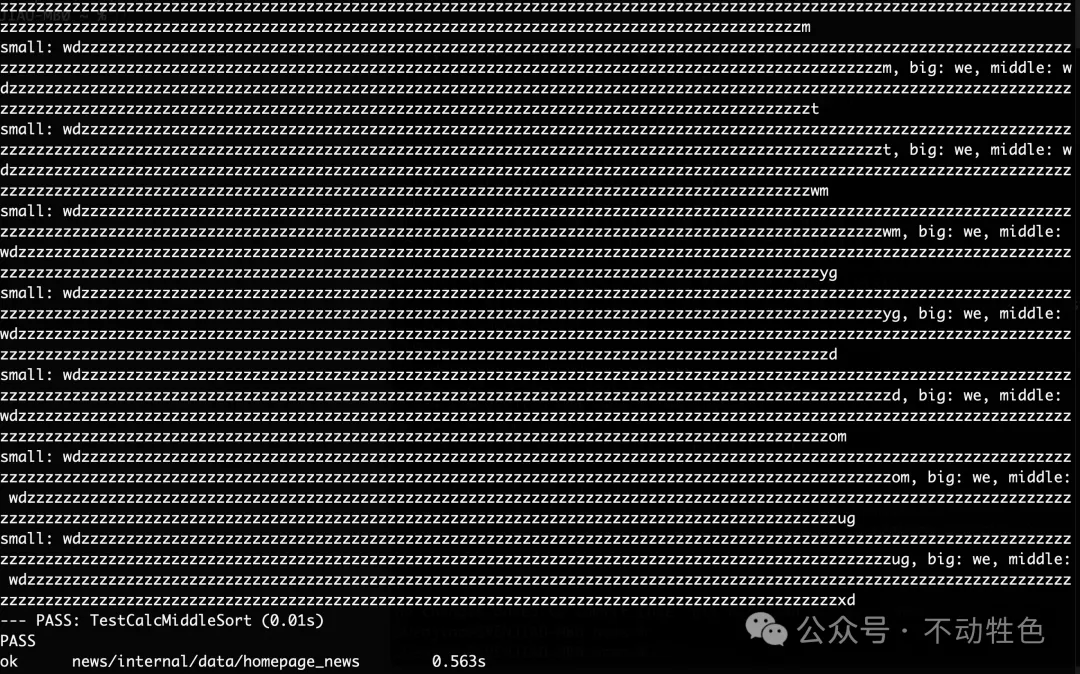
func TestCalcMiddleSort(t *testing.T) {
small, big := "vq", "we"
//small, big = "aaaaaaaa", "aaaaaaab"
//small, big = "aaaaaaaa", "baaaaaab"
//small, big = "baaaaaab", "werfdfdjdfdfs"
for i := 0; i < 1000; i++ {
middle := calcMiddleSort(small, big)
fmt.Printf("small: %s, big: %s, middle: %s\n", small, big, middle)
if !(small < middle && middle < big) {
t.Fatalf("small: %s, big: %s, middle: %s", small, big, middle)
}
small = middle
}
}
本文来源:公众号 不动牲色

















 243
243

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









