




 本文档介绍了如何使用scrapy框架爬取阿里巴巴的招聘信息。首先创建scrapy项目,然后设置爬虫伪装,定制爬取策略,包括分析总页数和记录数。接着通过提交请求获取数据,由于限制每次最多500条,需循环爬取26次。最后,通过定义item和设置pipelines来存储爬取的数据。
本文档介绍了如何使用scrapy框架爬取阿里巴巴的招聘信息。首先创建scrapy项目,然后设置爬虫伪装,定制爬取策略,包括分析总页数和记录数。接着通过提交请求获取数据,由于限制每次最多500条,需循环爬取26次。最后,通过定义item和设置pipelines来存储爬取的数据。
scrapy爬取——阿里招聘信息
爬取网站地址:
https://job.alibaba.com/zhaopin/positionList.htm
1.创建项目
进入项目目录

输入cmd进入都是窗口创建项目,默认普通爬虫框架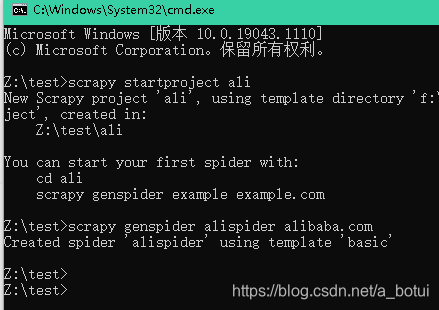
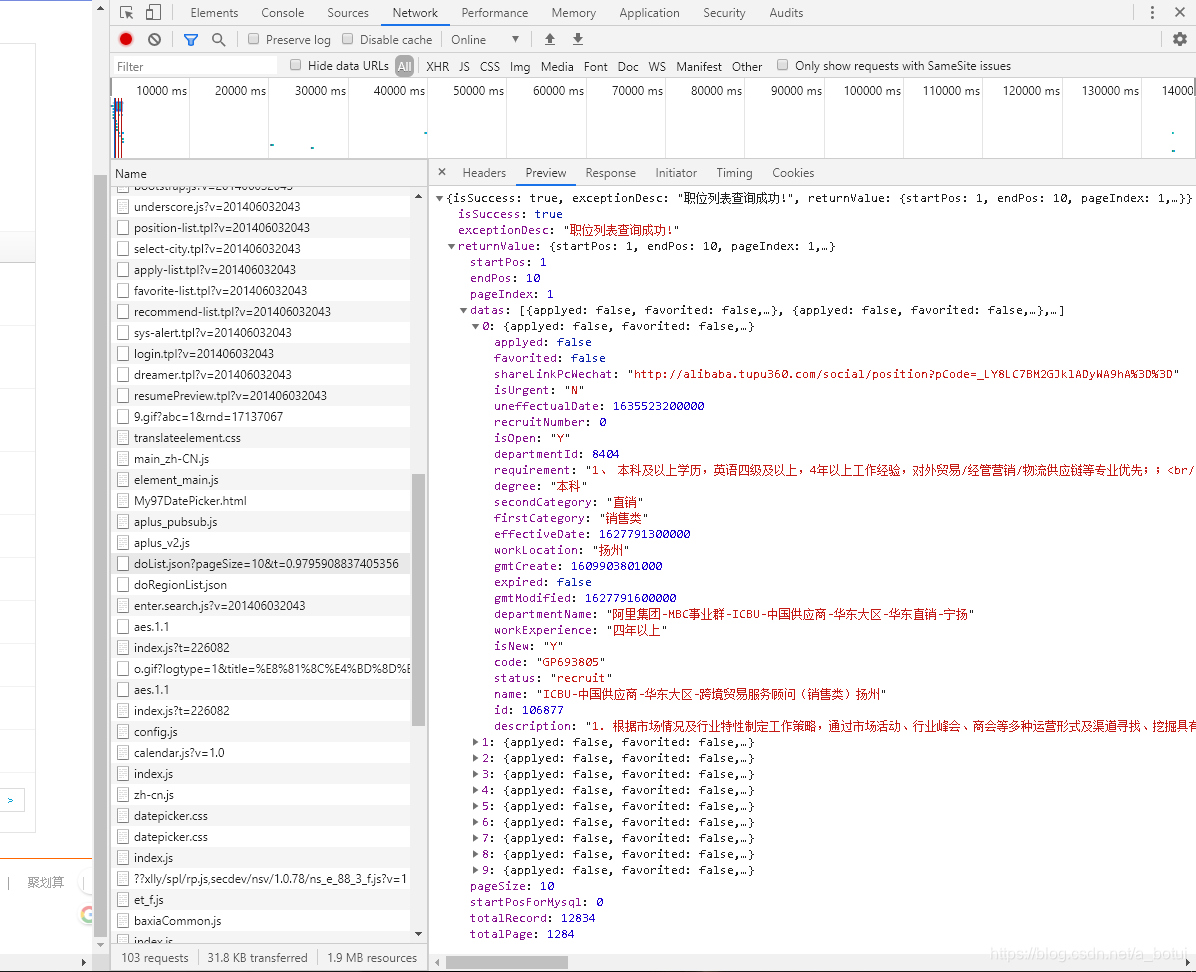
分析页面找到network中的数据出口
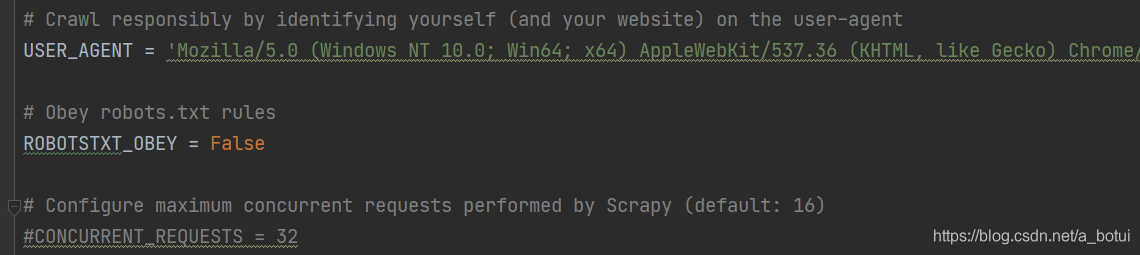
2.爬虫伪装
爬虫规则(concurrent)改为False,将network中的user_agent(浏览器伪装)填写网页中的user_agent
3.定制爬取策略
从信息页面可以看出总页数和总记录条数,在提取信息的的页面可直接查询全部记录数。
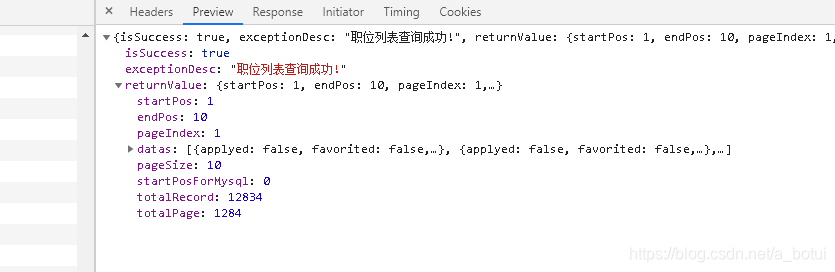
查看需要提交的表单
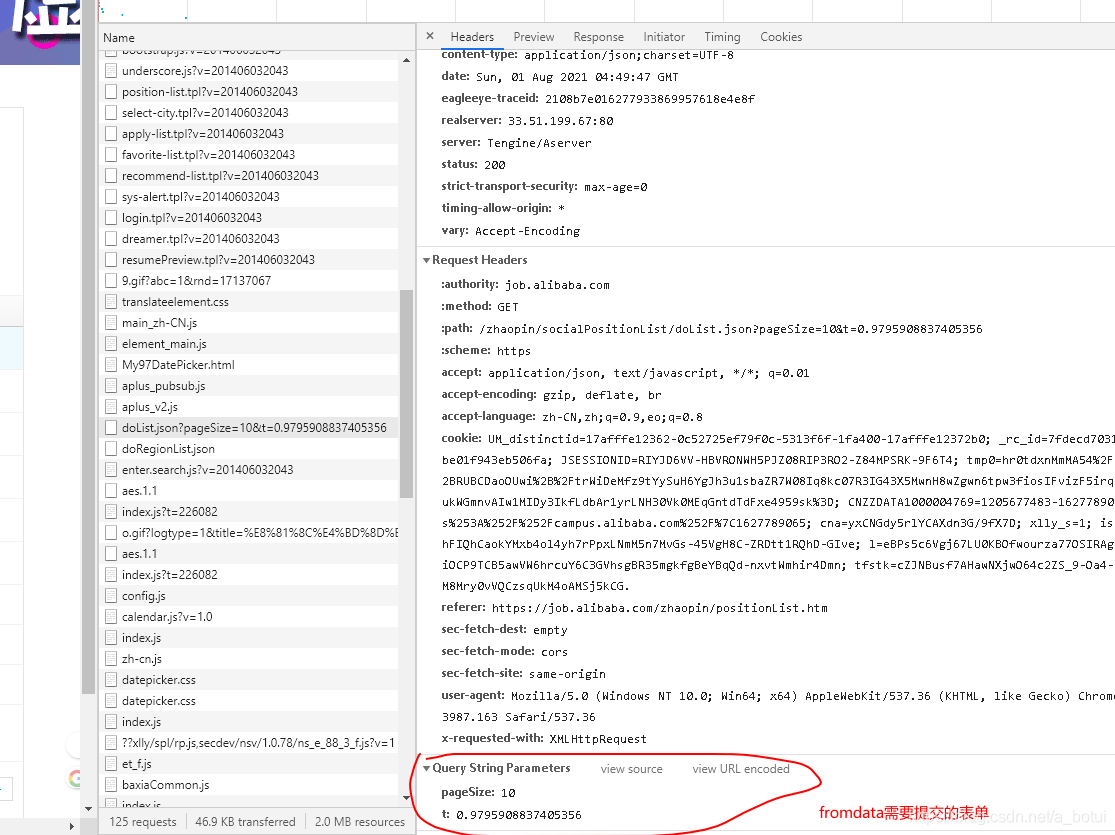
查询全部记录
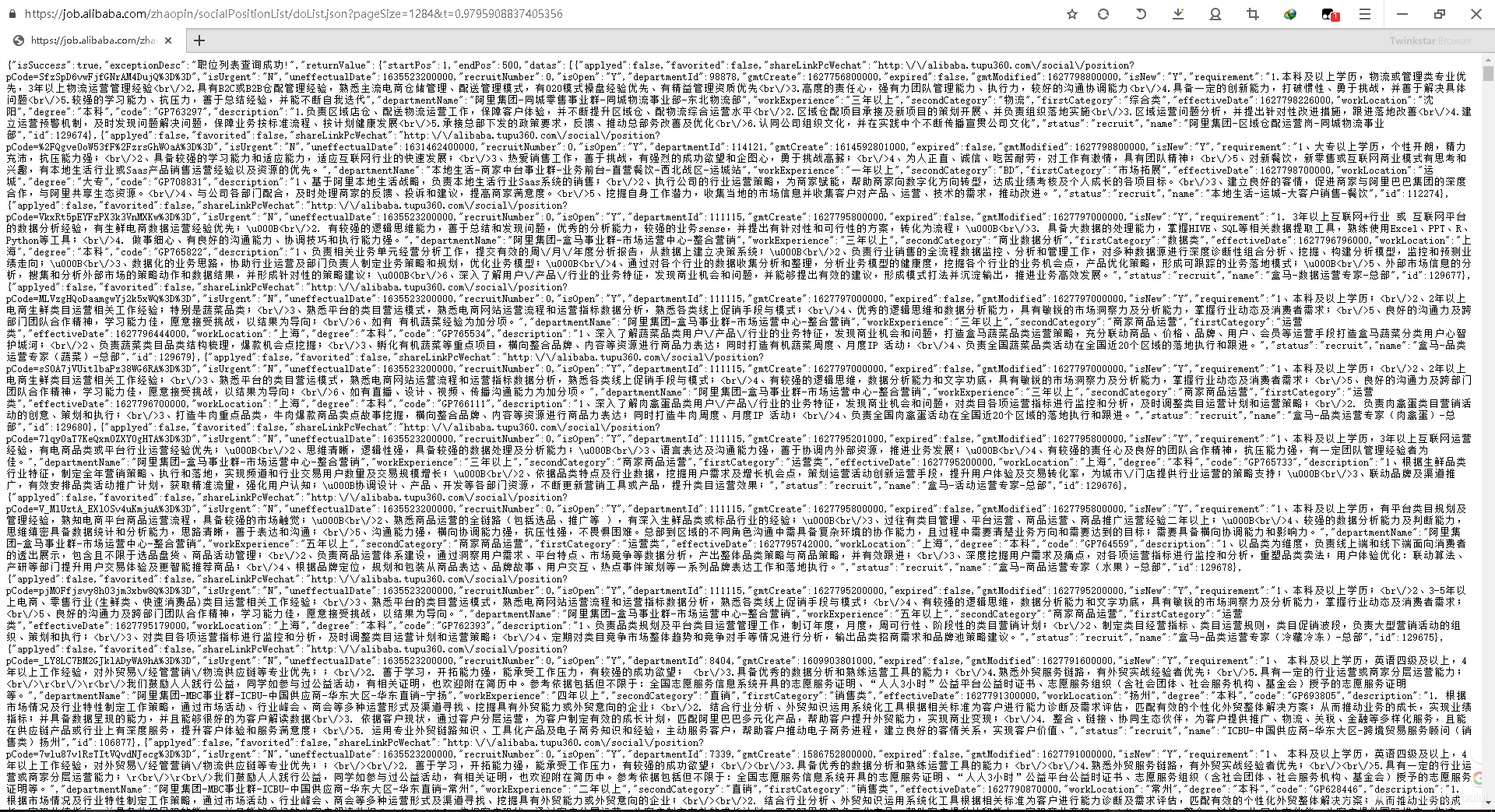
4.提交请求并获取数据。
查询最高限制仅有500条,总页面为26,做个简单循环爬取信息。
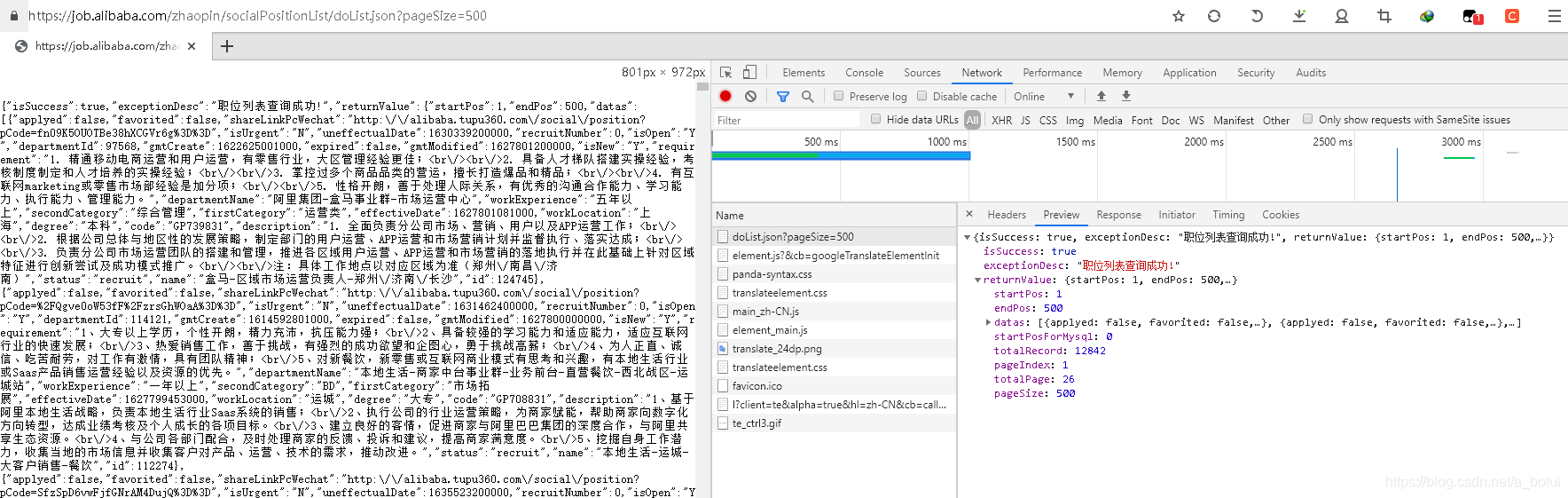
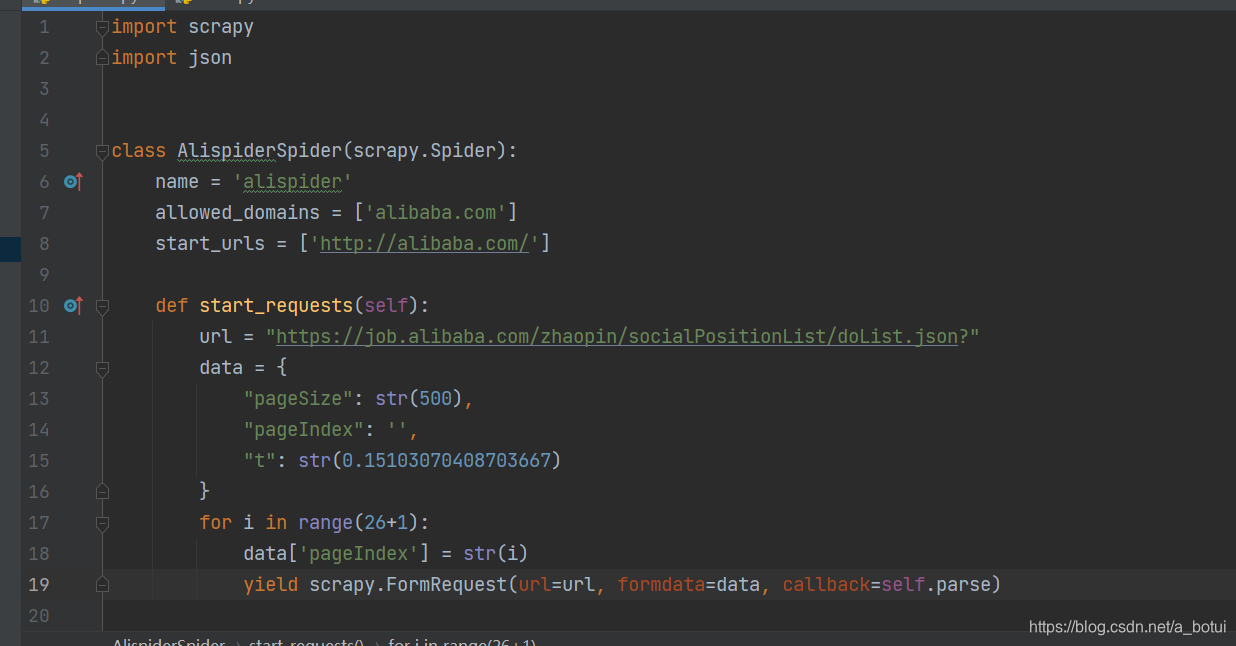
导入json库,将网页的json数据转换。(转换完成后可用字典形式提取指定数据)
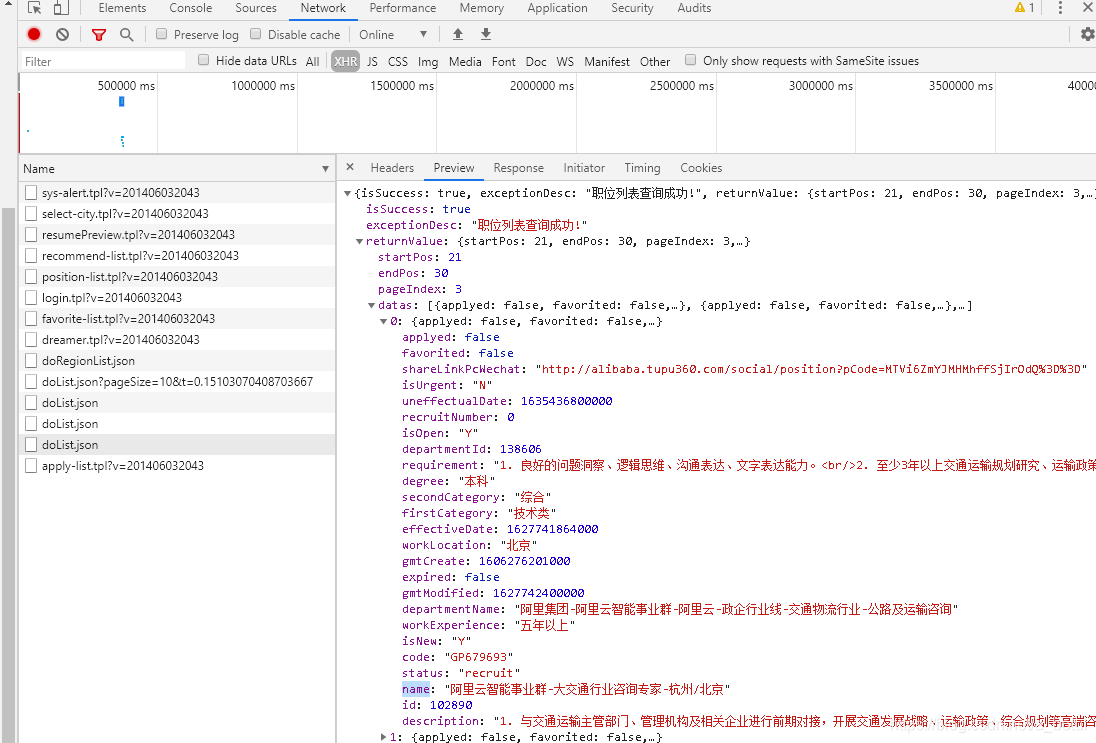

简单提取几个指定数据也可以提取全部数据。(一次获取500数据,迭代数据)
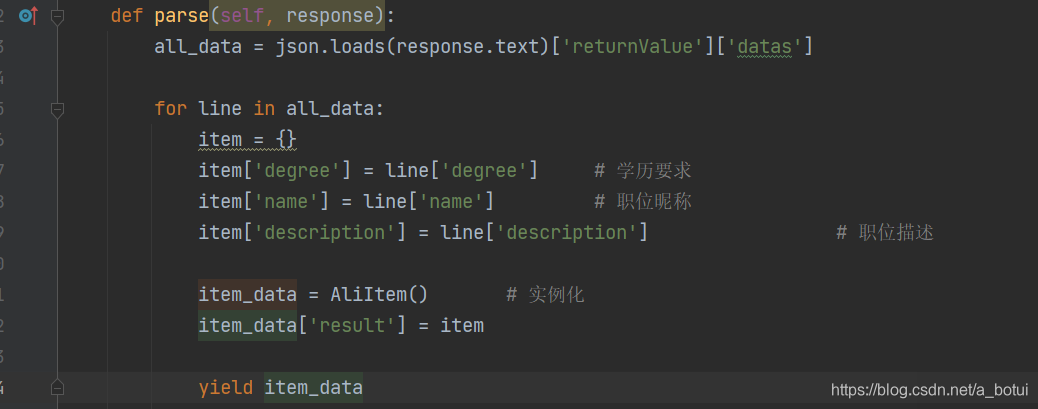
5.数据存储+完整代码
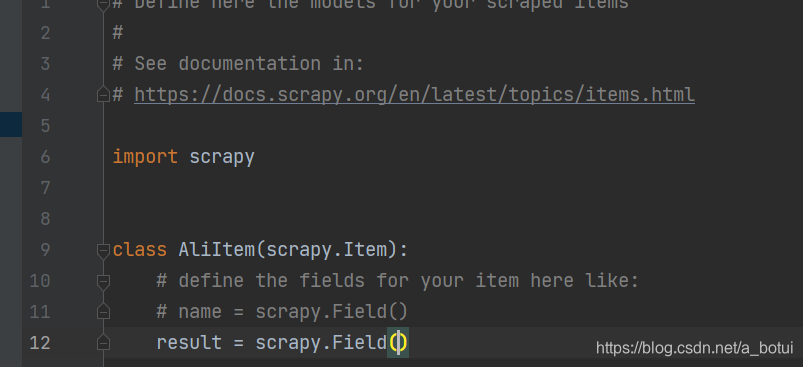
item定义容器存储(定义一个,数据边写边存速度较慢)
item需要导入from items import AliItem
开启存储通道
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1150
1150

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









