



目录
引言
随着自然语言处理(NLP)技术的发展,聊天机器人已经成为了人机交互的重要组成部分。本教程将指导你如何使用Python部署预模型,然后使用Flask框架搭建一个Web服务器,并结合Hugging Face的
transformers库来创建一个功能强大的聊天机器人API。我们将详细解释代码逻辑,并分享开发思路。
实际效果

这里我是用cpu来推理的,推理速度有点慢,有条件的可以使用GPU,然后还想提升速度的话可以用c++中的libtorch。ui是用python的streamlit库简单做了一下,有需要可以直接复制下面的代码:
import streamlit as st
import requests
st.title("智能客服系统")
# 初始化聊天历史
if "messages" not in st.session_state:
st.session_state.messages = []
# 显示聊天历史
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
# 用户输入
if prompt := st.chat_input("请输入您的问题"):
# 显示用户消息
with st.chat_message("user"):
st.markdown(prompt)
st.session_state.messages.append({"role": "user", "content": prompt})
# 获取AI响应
with st.chat_message("assistant"):
response = requests.post(
"http://localhost:8000/chat",
json={"message": prompt}
)
if response.status_code == 200:
ai_response = response.json()["response"]
st.markdown(ai_response)
st.session_state.messages.append({"role": "assistant", "content": ai_response})
else:
st.error(f"Error: {response.status_code}") 项目背景与目标
实现一个简单的RESTful API服务,允许客户端发送文本消息给服务器,服务器则利用预训练的语言模型生成回复并返回给客户端。通过这种方式,用户可以通过HTTP请求与我们的聊天机器人进行交流。
技术栈
- Flask:轻量级的Python Web框架,用于快速构建Web应用程序。
- Hugging Face Transformers:提供了一系列先进的NLP模型及其接口,简化了模型加载、推理等操作。
- PyTorch:一个流行的深度学习库,支持动态计算图,是许多NLP模型的基础框架之一。
代码解析
导入必要的库:
from flask import Flask, request, jsonify
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch这里我们导入了Flask来创建Web应用,以及transformers库中用于加载和使用预训练模型的相关模块。torch则是PyTorch的核心包,提供了张量运算和其他深度学习特性。
创建Flask应用实例
app = Flask(__name__)这行代码创建了一个新的Flask应用实例,__name__参数指定了当前模块的名字,以便Flask可以定位到静态文件和模板的位置。
定义ChatBot类
class ChatBot:
def __init__(self):
model_path = "./models/chatglm3-6b" # 模型路径
self.tokenizer = AutoTokenizer.from_pretrained(
model_path,
trust_remote_code=True # 允许执行自定义代码
)
self.model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float32,
device_map='cpu',
trust_remote_code=True # 允许执行自定义代码
)
self.model = self.model.eval()
def chat(self, user_input):
inputs = self.tokenizer(user_input, return_tensors="pt", padding=True, truncation=True, max_length=512)
inputs = {k: v.to(self.model.device) for k, v in inputs.items()}
outputs = self.model.generate(
inputs['input_ids'],
attention_mask=inputs['attention_mask'],
max_length=100,
num_return_sequences=1,
temperature=0.7,
top_p=0.9,
pad_token_id=self.tokenizer.eos_token_id,
do_sample=True
)
response = self.tokenizer.decode(outputs[0], skip_special_tokens=True)
return responseChatBot类解释
初始化函数__init__
加载模型路径
和c++中的构造函数有点相似,在这个类被实例化的时候自动调用(不懂的就理解成它会自动调用就行),然后里面定义了一个模型的路径,
model_path = "./models/chatglm3-6b"就是我们的预模型的路径。这里大家要先下载好!可以自己通过国内镜像源下,我这里也给大家在网盘里面分享了,可以自取,解压后放在和文件的同一路径下,模型链接:https://pan.quark.cn/s/179f1b616366
加载分词器
self.tokenizer = AutoTokenizer.from_pretrained(
model_path,
trust_remote_code=True # 允许执行自定义代码
)这个是加载模型相应的预训练分词器。什么意思呢?就是我们一句话过去直接给模型,它是看不懂的,这时候就需要我们的分词器把文字(比如句子)分解成模型能够理解和处理的小块,这些小块我们称之为“token”或者“标记”,然后给到模型。所以这里要加载这个分词器,当然光分解句子不够,我们还需要模型能生成东西是吧。所以下面。
加载因果语言模型
self.model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float32,
device_map='cpu',
# torch_dtype=torch.float16,
# device_map="auto"
trust_remote_code=True # 允许执行自定义代码
)从预训练模型路径加载因果语言模型,这里的“因果”意味着模型根据之前看到的文本(即上下文)来生成或预测下一个最有可能出现的词,torch_dtype=torch.float32指定了模型权重的数据类型为32位浮点数。device_map指定了模型应该加载到CPU上运行,而不是GPU。最后,再次设置了trust_remote_code=True以允许执行可能存在的自定义代码。如果你像在gpu上运行推理,看到我代码中的注释了吗?替换掉就行。(gpu的显存可能要8g以上才能跑的动)
设置eval模式
self.model = self.model.eval()这是是告诉模型,现在不是训练阶段了,不需要去更新参数,如果是训练阶段可以使用这个模式:
self.model.train()这样当你有内容输入的时候它会更新参数。
小结:
我们这个ChatBot类被实例化时,类中会自动加载分词器和因果模型,并让模型不再更新参数。(到这里大家有问题可以下方留言)
chat函数
函数参数
def chat(self, user_input):该函数接收一个参数userI_input,这就是我们输入的文本内容。
使用分词器
inputs = self.tokenizer(user_input, return_tensors="pt", padding=True, truncation=True, max_length=512)这是我们上面定义的分词器,我上面也解释过它的作用了,这里就是把我们的输入文本给这个分词器来做标记。
参数解释:
return_tensors="pt":指定返回的数据类型为PyTorch张量。padding=True:如果输入的序列长度不一致,则用填充(padding)使所有序列具有相同的长度。truncation=True:如果输入序列超过最大长度,则截断它们以适应最大长度。max_length=512:指定了每个输入序列的最大长度,这里是512个token。如果输入文本更长,则会被截断;如果更短,则会填充到这个长度
更多的参数解释大家可以自己点进源码去看。
确保位置
{k: v.to(self.model.device) for k, v in inputs.items()}这里是把我们经过生成器生成的每一个张量,都移动到对应的推理设备上去(我们这里是cpu,取决与上面定义的self.model.device)
举例:
这可能是我们一开始的张量长这样
inputs = {
'input_ids': tensor([[ 101, 2023, 3045, ..., 102]]), # 假设这是一个CPU上的张量
'attention_mask': tensor([[1, 1, 1, ..., 1]]) # 同样是CPU上的张量
}经过上面的代码后:
inputs = {
'input_ids': tensor([[ 101, 2023, 3045, ..., 102]], device='cpu'), # 现在是在cpu上的张量
'attention_mask': tensor([[1, 1, 1, ..., 1]], device='cpu') # 同样是在cpu上的张量
}如果你在gpu上:
inputs = {
'input_ids': tensor([[ 101, 2023, 3045, ..., 102]], device='cuda:0'), # 现在是在GPU上的张量
'attention_mask': tensor([[1, 1, 1, ..., 1]], device='cuda:0') # 同样是在GPU上的张量
}使用模型生成回答
# 使用模型生成回答
outputs = self.model.generate(
inputs['input_ids'],
attention_mask=inputs['attention_mask'], # 显式传递 attention_mask
max_length=100,
num_return_sequences=1,
temperature=0.7,
top_p=0.9,
pad_token_id=self.tokenizer.eos_token_id,
do_sample=True
)把我们上面经过分词器的结果,使用预训练的语言模型生成响应。generate方法接受多种参数来控制生成过程:
- inputs['input_ids']:提供给模型的输入ID序列。
- attention_mask:告诉模型哪些部分是实际内容,哪些是填充的部分。
- max_length=100:设置生成输出的最大长度。
- num_return_sequences=1:指定生成一条序列作为回复。
- temperature=0.7:影响生成文本的随机性,较低的温度会导致更可预测的结果,而较高的温度则会产生更多样化但可能不太连贯的输出。
- top_p=0.9:使用核采样(nucleus sampling),只从最有可能的词中选择,覆盖概率总和达到0.9的词汇。
- pad_token_id=self.tokenizer.eos_token_id:指定用于填充的特殊标记ID,通常也是句子结束标记。
- do_sample=True:启用采样模式,而不是使用贪心搜索(即总是选择最高概率的下一个词)
解码生成的回答
response = self.tokenizer.decode(outputs[0], skip_special_tokens=True)
return response还记得我们之前提过吗。分词器把因果模型看不懂的文本做标记,给到文本。就是做了一层转码,同样的道理模型生成的东西我们也看不懂,也需要分词器来做一个解码。然后返回解码后也就是我们能看懂的结果。
到这里,我们一个完整的对话流程就完成了,有问题的同志可以下方留言。
实例化类
chatbot = ChatBot()定义路由
@app.route('/chat', methods=['POST'])
def chat():
try:
user_input = request.json.get('message', '')
if not user_input:
return jsonify({'error': 'No message provided'}), 400
response = chatbot.chat(user_input)
return jsonify({'response': response})
except Exception as e:
return jsonify({'error': str(e)}), 500这里就是定义路由和相关的函数。加人相应的异常处理
user_input = request.json.get('message', '')这里得到客户端,就是我一开始那个代码发来的消息
if not user_input:
return jsonify({'error': 'No message provided'}), 400没有得到消息就会返回一个错误码和对应的消息,得到的话:
response = chatbot.chat(user_input)调用chatbot类中的chat函数,并把得到的内容作为参数给过去。然后再把响应的结果返回给客户端,这样客户端就会把内容(也就是模型生成的文字),展示出来了:
如图:
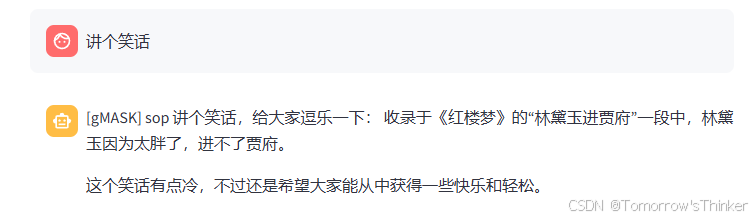
总结
总的流程并不复杂,但是这里大家也会发现,预模型的实际效果是不太理想的,所以一般我们还会对它进行一定的训练才能真正上线使用。训练代码如下:
from transformers import AutoTokenizer, AutoModel
from peft import get_peft_model, LoraConfig, TaskType
import torch
from torch.utils.data import Dataset, DataLoader
from torch.cuda.amp import autocast, GradScaler
# 自定义数据集
class CustomDataset(Dataset):
def __init__(self, data, tokenizer, max_length=512):
self.data = data
self.tokenizer = tokenizer
self.max_length = max_length
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
item = self.data[idx]
# 假设数据格式为 {"instruction": "...", "input": "...", "output": "..."}
prompt = f"Instruction: {item['instruction']}\nInput: {item['input']}\nOutput: "
response = item['output']
# 编码输入
encoded = self.tokenizer(
prompt + response,
truncation=True,
max_length=self.max_length,
padding="max_length",
return_tensors="pt"
)
return {
"input_ids": encoded["input_ids"].squeeze(),
"attention_mask": encoded["attention_mask"].squeeze(),
}
def train():
# 1. 加载模型和分词器
tokenizer = AutoTokenizer.from_pretrained("./models/chatglm3-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("./models/chatglm3-6b", trust_remote_code=True)
# 2. 配置 LoRA
peft_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
inference_mode=False,
r=8, # LoRA 秩
lora_alpha=32,
lora_dropout=0.1,
target_modules=["query_key_value"] # 需要根据具体模型结构调整
)
# 3. 获取 PEFT 模型
model = get_peft_model(model, peft_config)
# 4. 准备训练数据
train_data = [
{
"instruction": "分析以下问题",
"input": "示例输入",
"output": "示例输出"
}
# 添加更多训练数据...
]
train_dataset = CustomDataset(train_data, tokenizer)
train_loader = DataLoader(train_dataset, batch_size=4, shuffle=True)
# 5. 训练配置
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-4)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# 6. 训练循环
model.train()
scaler = GradScaler()
for epoch in range(3): # 训练轮数
for batch in train_loader:
input_ids = batch["input_ids"].to(device)
attention_mask = batch["attention_mask"].to(device)
with autocast():
outputs = model(
input_ids=input_ids,
attention_mask=attention_mask,
labels=input_ids
)
loss = outputs.loss
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
print(f"Loss: {loss.item()}")
# 7. 保存模型
model.save_pretrained("./fine_tuned_model")
if __name__ == "__main__":
train() train_data = [
{
"instruction": "分析以下问题",
"input": "示例输入",
"output": "示例输出" #这里要根据自己需要什么模型来写
}
# 添加更多训练数据...
]这里去添加我们要训练的数据做针对训练。然后老规矩,整个项目代码打包在网盘:
:https://pan.quark.cn/s/c6eaa0ea3dfb 大家要记得先把模型下载好。




















 2042
2042







 到【灌水乐园】发言
到【灌水乐园】发言









