




目录
背景
对于爬虫新手来说,大家可以这样去理解,爬虫的过程就是”你自己使用浏览器得到一个网站内容的过程“
接下来我用代码来验证上面这句话。
你自己
这个部分大家可以想象自己玩游戏创建角色,这个角色就相当于你自己,同样的道理,在python中找到对应的能使用浏览器获取一个网站内容的角色。
import requests # 你自己,可以用来使用浏览器访问网站网站
有了自己这个角色之后,就是你现在要用浏览器获取哪个网站内容,可以是百度,谷歌,麻豆...等等。这里用作者的一篇关于机器学习实战的文章为列子(大家有兴趣可以看一下,文章后面有全部源码):
url = "https://blog.youkuaiyun.com/a_Loki/article/details/123733775"浏览器
接下来选择一个角色要使用的浏览器,如下:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36"
}这里大家可以自己去网上找一个"User-Agent",也可以直接用我的,(看不懂没关系,直接抄)。当然,如果你是老手,肯定知道f12里面有。这个意思大概就是你让你的角色使用了win10系统中的谷歌浏览器,这个不是重点。
请求过程
”你自己使用浏览器得到一个网站内容的过程“ 现在这句话,我们已经有了 自己,浏览器和我的网站,只差过程了,我们用代码完成这个过程:
resp = requests.get(url, headers=headers)get
小白怎么理解这段?我们会发现,这里五个单词,三个我们都认识,直接成功了一半。至于这里get,什么意思?直接翻译:
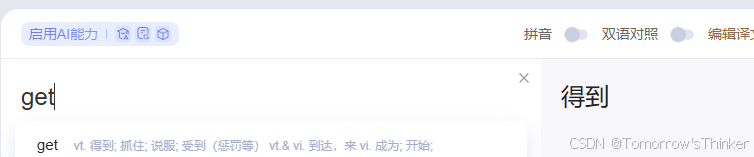
没错,这正好印证了我们的主旋律,”你自己使用浏览器得到一个网站内容的过程“。我们直接把这句:requests.get(url, headers=headers)理解成,我自己(requests)得到(get)一个网站(url)的信息使用谷歌浏览器(headers)。当然,懂的朋友肯定知道(get只是请求方式的一种),但是,作为小白,直接不懂,get就是得到。
resp
第二个你可能看不懂的地方,resp= 是什么?这里我们根据上面的内容,我们是不是完成了”你自己使用浏览器得到一个网站内容的过程“,那么这里的网站内容在哪里呢?没错,就在这个resp里面,我们把内容赋值给了resp。这个过程好比,上学时候你问老妈要钱,然后把钱放入钱包,而resp,就是哪个钱包。
查看内容
上面我们已经知道了,内容都装到了resp里面是把,那这里我们直接打印resp出来:
print(resp)然后,你会看到:
![]()
不要慌出现200,说明成功了。但为什么看不到内容?因为这个,只是一个确认信息,相当于你点外卖,外卖员给你点了确认送达,你会收到信息而没有拿到外卖,这时,你得开门拿外卖。所以,改一下代码,
print(resp.text)text不懂?直接翻译:

之前就提到,我们获取的内容是 我的文章,所以我们要打开文本的内容,使用了text。然后你就会看到:
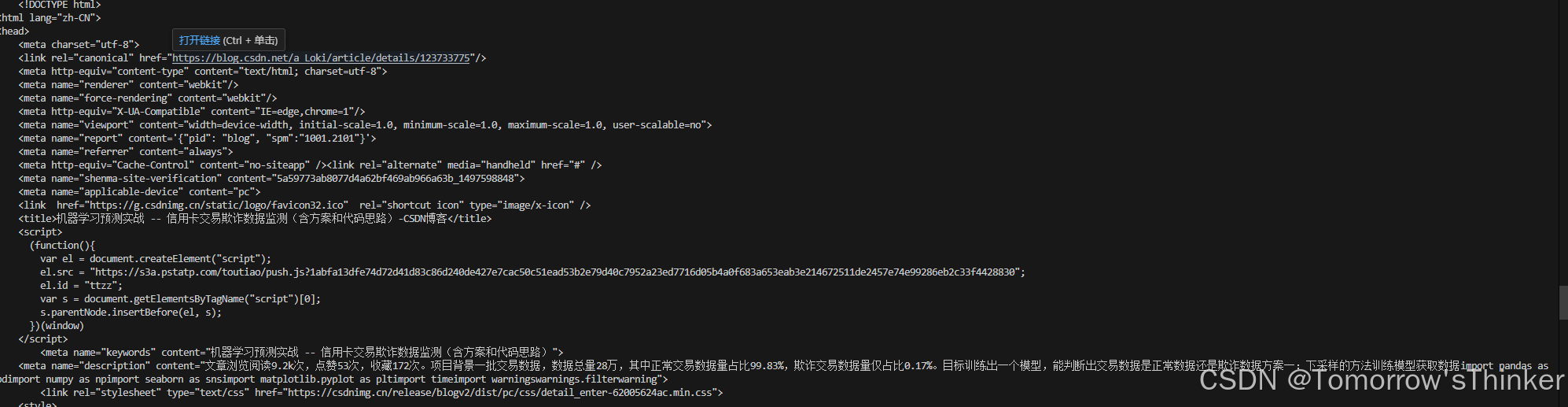
如果是这样,恭喜你,第一个爬虫完成了。
疑问
当然你可能觉得奇怪,为什么别人爬虫程序出来的数据是这样的:

井然有序,而我的一团乱麻?那是因为它可能像下面这样清洗了数据:
if performance_data_match:
view_count = performance_data_match.group(1)
like_count = performance_data_match.group(2)
collect_count = performance_data_match.group(3)
print(f"文章浏览阅读: {view_count}")
print(f"点赞: {like_count} 次")
print(f"收藏: {collect_count} 次") 但这不重要,我建议大家先把前几步弄明白,先让第一个爬虫跑起来再说。如果,你需要这个加了数据清洗的完整爬虫代码(下方链接自行保存):
链接:https://pan.quark.cn/s/3f648066bfdc
提取码:47BX
最后
如果你还是不能把这个爬虫搞出来,请下面直接评论喷我,或者,提出你的问题,我可以帮你解答。如果大家需要文章讲解一下完整的带数据清洗的代码,下面评论数据清洗,人多我会更


















 65万+
65万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











