






 本文介绍PaddlePaddle中样本级Reader的使用,通过一个例子展示如何处理数据,使得训练数据每批包含多个样本。内容包括产生训练数据、开始训练的步骤,以及完整程序和运行结果。
本文介绍PaddlePaddle中样本级Reader的使用,通过一个例子展示如何处理数据,使得训练数据每批包含多个样本。内容包括产生训练数据、开始训练的步骤,以及完整程序和运行结果。
题外话:春节假期延长了。向战斗在疫情防控一线的人们致敬。
样本级Reader举例
PaddlePaddle根据Reader返回的数据形式的不同,可分为Batch级的Reader和样本级的Reader。
本文通过一个例子讲述样本级Reader的使用方法。
还是以《paddlepaddle中的数据读入方式1–直接输入数据》中的例子为基础,跳过为改动的程序部分。
产生训练数据–给网络准备食物
此处考虑准备较多食物的情景,比如一餐10道“菜”,每道“菜”有4个“盘子”,每个“盘子”里只有1个“食物”。如果这样写:
train_data=numpy.array([
[[1],[2],[3],[4]],#第1道菜
[[2],[4],[6],[8]],#第2道菜
[[3],[6],[9],[12]],#第3道菜
[[4],[8],[12],[16]],#第4道菜
[[5],[10],[15],[20]],#第5道菜
[[6],[12],[18],[24]],#第6道菜
[[7],[14],[21],[28]],#第7道菜
[[8],[16],[24],[32]],#第8道菜
[[9],[18],[27],[36]],#第9道菜
[[10],[20],[30],[40]]]).astype('float32') #第10道菜
由于train_data的shape=(10,4,1),与嘴巴形状不符
x = fluid.data(name="x",shape=[None,1],dtype='float32')
系统提示:
 其中一种解决办法就是用Reader把每道“菜”间隔开喂进嘴里。将train_data的赋值语句用下列程序段取代:
其中一种解决办法就是用Reader把每道“菜”间隔开喂进嘴里。将train_data的赋值语句用下列程序段取代:
def reader():
for i in range(1,11):
train_data = numpy.array([i,i*2,i*3,i*4]).reshape(4, 1).astype("float32")
yield train_data # 使用yield来返回单条数据
开始训练–喂食
这部分程序也需要相应改动。
for i in range(3): # 连吃三顿
print(i)
m=0
for data in reader(): #从题库里每次抽出一道题
if(i==2):
print(m,data) #显示最后一次喂入的食物()
m+=1
outs = exe.run( # 加载主程序运行执行器
feed={'x':data}, # 从名为x的嘴巴喂入train_data食物
fetch_list=[y_predict])
# 最后的训练结果
print(outs) # 输出列表仅有一个内容,就是out[0]=y_predict
完整的程序
import paddle.fluid as fluid
import numpy
def reader():
for i in range(1,11):
train_data = numpy.array([i,i*2,i*3,i*4]).reshape(4, 1).astype("float32")
yield train_data # 使用yield来返回单条数据
x = fluid.data(name="x",shape=[None,1],dtype='float32') # 嘴巴的shape容纳了食物的shape。
y_predict = fluid.layers.fc(input=x,size=1,act=None)
cpu = fluid.core.CPUPlace() # 在cpu上操作
exe = fluid.Executor(cpu)
exe.run(fluid.default_startup_program()) # 运行执行器初始化网络参数(采用默认的初始化程序)
for i in range(3): # 连吃三顿
print(i) # i表示第几顿
m=0 # m表示第几道
for data in reader(): #每顿吃10道“菜”,每口只喂1道“菜”
if(i==2):
print(m,data) #显示最后一顿的菜谱
m+=1
outs = exe.run( # 加载主程序运行执行器
feed={'x':data}, # 从名为x的嘴巴喂入reader端上的食物
fetch_list=[y_predict])
# 最后的训练结果
print(outs) # 输出列表仅有一个内容,就是out[0]=y_predict
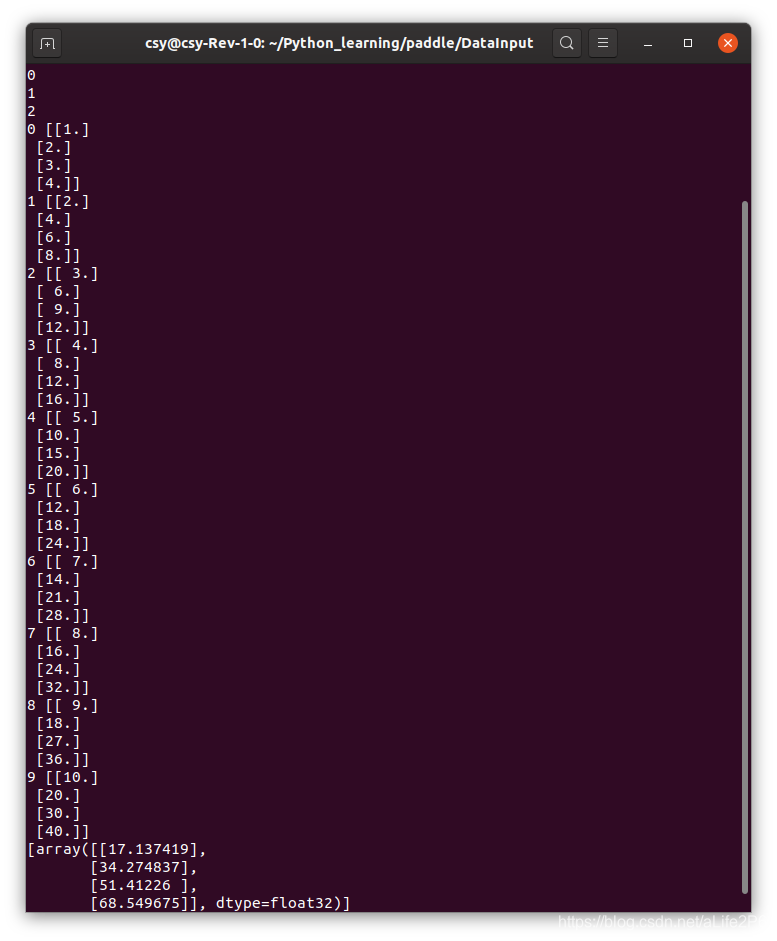
运行结果

















 2448
2448

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









