







在湖仓一体(Lakehouse)出现之前,数据仓库和数据湖堪称数据领域的两大“顶流”。打个比方,要是把数据仓库比作一座大型图书馆,那其中的数据就如同馆内藏书,需要按照规范放好,借阅者只需依照类别索引,便能精准找到想要的信息。反观数据湖,更像是一个大型仓库,海纳百川,可以存储任何形式和任何格式的原始数据。 然而,这两大传统模式各有掣肘。数据湖擅长存储大规模、非结构化数据,但缺乏数据治理和查询优化能力,导致数据“沼泽”现象频发;数据仓库可以提供强大的分析能力,但其扩展性和灵活性较差,尤其在处理非结构化数据时,表现不如数据湖。这些局限性导致了企业数据孤岛林立、重复管理耗时费力等问题,愈发难以契合现代企业在海量、多元数据浪潮冲击下的数智需求。 市场和行业都在呼唤着新一代数据架构模式的破局与革新,从传统数仓到结合数据湖和数据仓库两层架构,再到构建高性能计算引擎,直接在数据湖上进行数据探查以及分析。 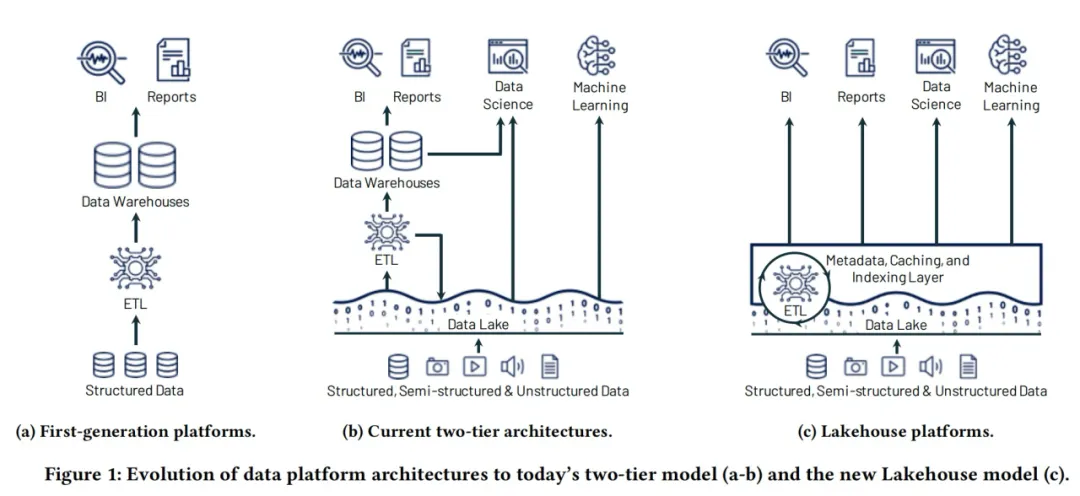 无外乎都在表明新的数据架构被期望具备以下功能: 能够提供ACID支持,支持插入/更新操作 具有高度的可扩展性,经济高效且灵活 优秀的BI性能以及数据仓库的访问控制机制 能够处理所有数据格式并支持多种用例的统一平台 而满足这些功能点的便是新的数据架构——湖仓一体Lakehouse
无外乎都在表明新的数据架构被期望具备以下功能: 能够提供ACID支持,支持插入/更新操作 具有高度的可扩展性,经济高效且灵活 优秀的BI性能以及数据仓库的访问控制机制 能够处理所有数据格式并支持多种用例的统一平台 而满足这些功能点的便是新的数据架构——湖仓一体Lakehouse
01什么是Lakehouse
Lakehouse本质上是一个带有附加事物层和高性能计算引擎的数据湖,从结构上来说可以拆成两个层面: 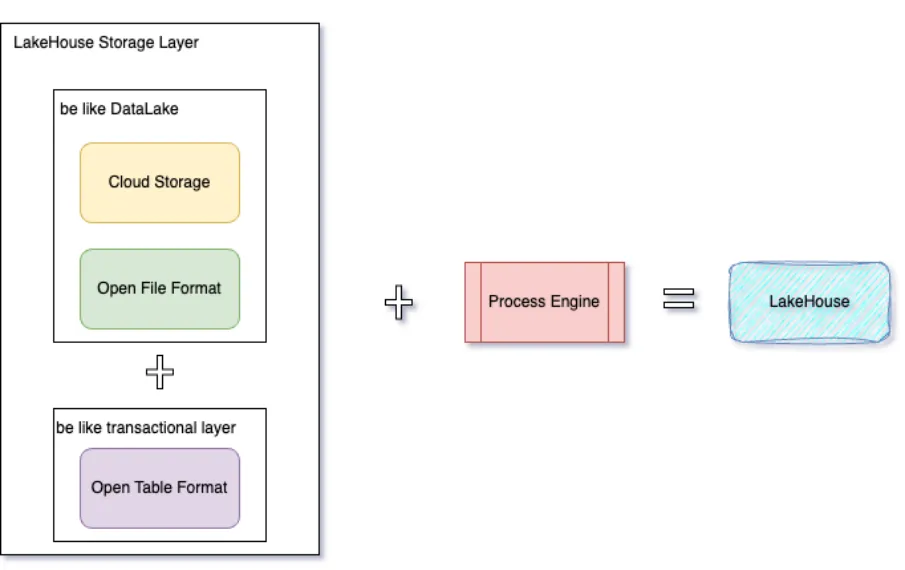 1、带有附加事物特性的存储层 这一层主要由三个组件组成:开放的表格式、开发的文件格式和云存储。
1、带有附加事物特性的存储层 这一层主要由三个组件组成:开放的表格式、开发的文件格式和云存储。 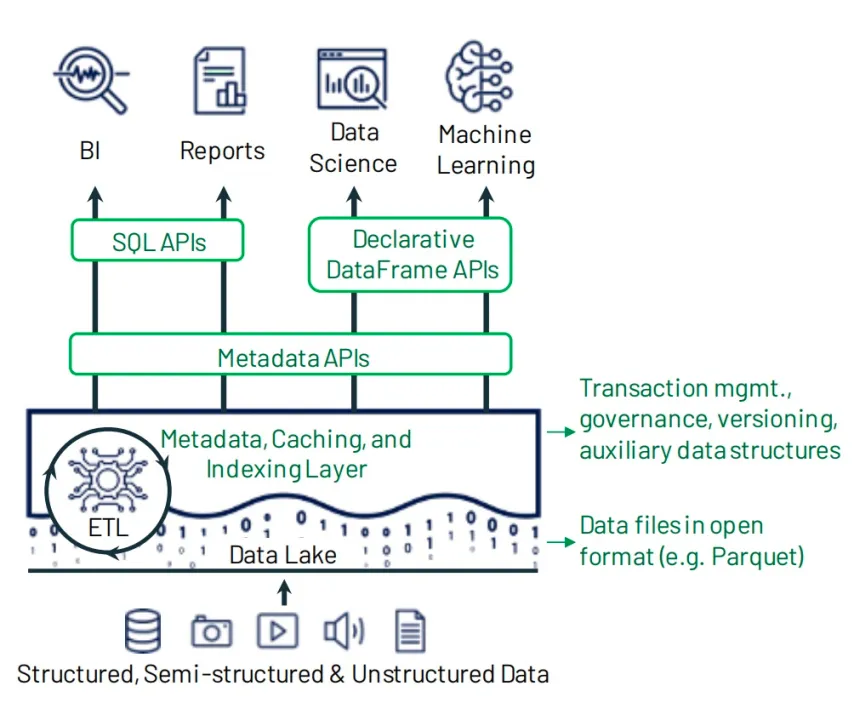
- 开放的表格式 可以理解为是提供类似数据仓库ACID数据和其他特性的元数据层(Metadata APIs),为了保持一致性,它提供了与事务相关
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









