






面试题总结
Java基础
1、反射的原理?作用?怎么使用的?
2、Java object类是否可以创建
3、匿名内部类如何访问到外部类的方法和属性?
4、error是否可以捕获到?
5、final关键字
Final用于修饰类、成员变量和成员方法。
final修饰的类,不能被继承(String、StringBuilder、StringBuffer、Math,不可变类),其中所有的方法都不能被重写(这里需要注意的是不能被重写,但是可以被重载,这里很多人会弄混),所以不能同时用abstract和final修饰类(abstract修饰的类是抽象类,抽象类是用于被子类继承的,和final起相反的作用);Final修饰的方法不能被重写,但是子类可以用父类中final修饰的方法;
Final修饰的成员变量是不可变的,如果成员变量是基本数据类型,初始化之后成员变量的值不能被改变,如果成员变量是引用类型,那么它只能指向初始化时指向的那个对象,不能再指向别的对象,但是对象当中的内容是允许改变的。
6、浮点类型(如float和double)和BigDecimal在计算机中的表示都会有精度丢失的问题请阐述?
对于float和double,它们是用二进制系统来表示的。大部分十进制小数无法在二进制中精确表示,因此会产生精度丢失的问题。举个例子,0.1在二进制中是一个无限循环小数,因此在用float或double表示时,只能存储其近似值,从而导致了精度丢失。
而对于BigDecimal,它是用十进制系统表示的,因此大部分十进制小数可以精确表示,不会有精度丢失的问题。但是,BigDecimal在进行除法运算时,如果除不尽,也会产生精度丢失的问题。这是因为BigDecimal的除法运算需要指定小数点后的精度,如果除不尽,就会根据指定的精度进行舍入,从而导致精度丢失。
因此,在进行浮点数运算时,我们需要注意这些问题,尤其是涉及到金融等需要精确计算的场景,我们通常会使用BigDecimal来进行运算,并且需要正确地设置精度和舍入模式,以避免精度丢失的问题。
7、一个中文占几个字符
不同的编码格式占字节数是不同的,UTF-8编码下一个中文所占字节也是不确定的,可能是2个、3个、4个字节
在Java中,一个汉字占用的字节数取决于所使用的字符编码。不同的编码方式对于字符(包括汉字)的字节表示有不同的规定。
GB2312和GBK编码: 这两种编码是专门用于中文字符的编码方式。它们通常使用两个字节来表示一个汉字。
Unicode编码: Unicode是一个国际标准的字符编码,它统一了全球各种语言的字符。在Java中,char类型使用16位的Unicode字符集,因此无论是汉字还是其他字符,都使用两个字节(16位)来表示。然而,Unicode有多种实现方式,如UTF-8、UTF-16和UTF-32。
UTF-8编码: 这是一种变长的编码方式。在UTF-8中,英文字母和数字通常占用一个字节,而汉字则通常需要三个字节来表示,但也可能需要更多字节,具体取决于汉字的具体编码。
UTF-16编码: 在UTF-16编码中,无论是汉字还是英文字母,通常都占用两个字节(在Java的char类型中就是这样表示的)。但是,对于某些不常用的字符,UTF-16也可能使用四个字节来表示一个字符。
UTF-32编码: UTF-32使用固定的四个字节来表示任何Unicode字符,无论它是汉字还是其他字符。
8、位运算总结
按位异或运算 ^
0异或任何数 = 任何数
1异或任何数 = 取反
任何数异或本身 = 0
Ex:举例:输入两个整数m和n,计算需要改变m的二进制表示中的多少位才能得到n。
解决方法:第一步,求这两个数的异或;第二步,统计异或结果中1的位数。
知识点整合
n&(n-1) 可以消去最右边的1,如果计算二进制里有几个1可以这么计算
while(n!=0){count++;n & (n-1);}
举一反三:用一条语句判断一个整数是不是2的整数次方。
!( m &(m-1))//如果是2的整数次方则应只包含一个1
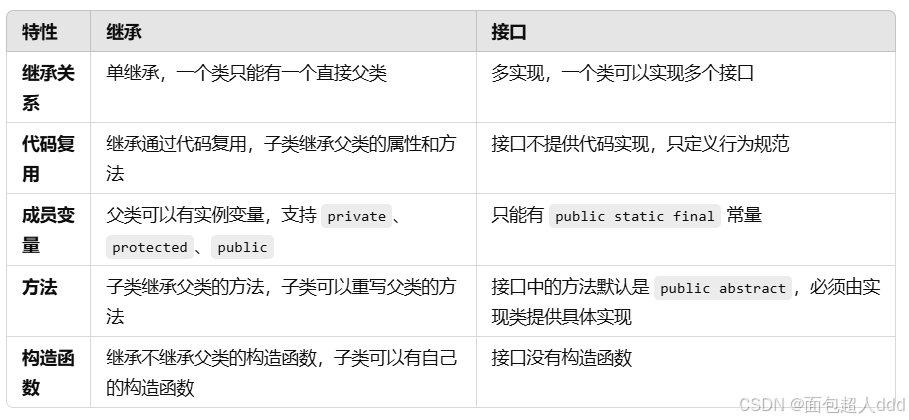
9、继承和接口的区别
多线程
LongAdder的原理
LongAdder 是 java.util.concurrent.atomic包下的一个类,用于高效地执行计数操作。它的设计基于 分段思想,通过将计数值分散到多个变量(称为 Cell),以减少线程竞争。
工作机制
分散热点(分段累加):
LongAdder 内部维护一个基于数组的结构(Cell[ ]),每个 Cell 是一个计数单元。
在每次更新操作时,线程会选择更新不同的 Cell,从而降低多个线程竞争同一个变量的概率。
如果竞争较少,所有线程可能会更新同一个变量(即默认值 base)。
如果竞争较多,LongAdder 会动态分配或扩展 Cell 数组,分散线程压力。
CAS 更新机制:
如果线程访问到的 Cell 未被占用,它会尝试用 CAS 操作初始化该 Cell。
如果线程访问到的 Cell 已存在,它会尝试通过 CAS 更新 Cell 的值。
如果 CAS 操作失败,说明存在竞争,线程会通过自旋或退避策略重新尝试,最终可能会尝试更新其他的 Cell。
最终结果合并:
LongAdder 的 sum() 方法会遍历所有的 Cell 并累加它们的值,同时加上 base 的值。
这种设计在读取时可能会稍微增加开销,但在高并发情况下,写操作的性能提升远大于读操作的额外成本。
简述syncronize锁的升级过程
**偏向锁保持:**在没有竞争的情况下,偏向锁会一直保持,提升单线程访问的性能,尤其对 重入性能 有显著提升。
**偏向锁到轻量级锁的升级:**当有线程竞争时,偏向锁被撤销,升级为轻量级锁,竞争通过 CAS 操作进行。
轻量级锁到重量级锁的升级:如果 CAS 操作失败频繁,或者自旋超过阈值,轻量级锁会升级为 重量级锁,此时性能下降,因为重量级锁涉及操作系统层面的同步。
补充:
轻量级锁与重量级锁之间的升级通常会在 竞争较为激烈 或 竞争时间较长 时发生。JVM 会根据系统的负载、锁的竞争情况以及线程的行为来决定是否进行升级。
重量级锁是操作系统级的互斥锁,它的开销较大,因此只有在极端情况下才会发生。
线程池——新建线程处理阻塞队列溢出任务还是最早任务?
线程池中核心线程都被占用,且阻塞队列已满时,再有新任务会新建一个线程并直接执行该新进来的任务。当该任务执行完毕,这个新建的线程会不断从阻塞队列池取出任务来执行,直至阻塞队列持续为空达到keepAliveTime的时间且当前线程数大于核心线程数时,该线程被销毁。
参照这篇:[https://blog.youkuaiyun.com/Yunwushenyanying/article/details/137886037
双亲委派
1、什么是双亲委派?
首先,我们知道,虚拟机在加载类的过程中需要使用类加载器进行加载,而在Java中,类加载器有很多,那么当JVM想要加载一个.class文件的时候,到底应该由哪个类加载器加载呢?
这就不得不提到"双亲委派机制"。
首先,我们需要知道的是,Java语言系统中支持以下4种类加载器:
Bootstrap ClassLoader 启动类加载器
Extention ClassLoader 标准扩展类加载器
Application ClassLoader 应用类加载器
User ClassLoader 用户自定义类加载器
这四种类加载器之间,是存在着一种层次关系的,如下图
一般认为上一层加载器是下一层加载器的父加载器,那么,除了BootstrapClassLoader之外,所有的加载器都是有父加载器的。
那么,所谓的双亲委派机制,指的就是:当一个类加载器收到了类加载的请求的时候,他不会直接去加载指定的类,而是把这个请求委托给自己的父加载器去加载。只有父加载器无法加载这个类的时候,才会由当前这个加载器来负责类的加载。
那么,什么情况下父加载器会无法加载某一个类呢?
其实,Java中提供的这四种类型的加载器,是有各自的职责的:
Bootstrap ClassLoader ,主要负责加载Java核心类库,%JRE_HOME%\lib下的rt.jar、resources.jar、charsets.jar和class等。
Extention ClassLoader,主要负责加载目录%JRE_HOME%\lib\ext目录下的jar包和class文件。
Application ClassLoader ,主要负责加载当前应用的classpath下的所有类
User ClassLoader , 用户自定义的类加载器,可加载指定路径的class文件
那么也就是说,一个用户自定义的类,如com.hollis.ClassHollis 是无论如何也不会被Bootstrap和Extention加载器加载的。
2、为什么需要双亲委派,不委派有什么问题?
如上面我们提到的,因为类加载器之间有严格的层次关系,那么也就使得Java类也随之具备了层次关系。
或者说这种层次关系是优先级。
比如一个定义在java.lang包下的类,因为它被存放在rt.jar之中,所以在被加载过程汇总,会被一直委托到Bootstrap ClassLoader,最终由Bootstrap ClassLoader所加载。
而一个用户自定义的com.hollis.ClassHollis类,他也会被一直委托到Bootstrap ClassLoader,但是因为Bootstrap ClassLoader不负责加载该类,那么会在由Extention ClassLoader尝试加载,而Extention ClassLoader也不负责这个类的加载,最终才会被Application ClassLoader加载。
这种机制有几个好处。
首先,通过委派的方式,可以避免类的重复加载,当父加载器已经加载过某一个类时,子加载器就不会再重新加载这个类。
另外,通过双亲委派的方式,还保证了安全性。因为Bootstrap ClassLoader在加载的时候,只会加载JAVA_HOME中的jar包里面的类,如java.lang.Integer,那么这个类是不会被随意替换的,除非有人跑到你的机器上, 破坏你的JDK。
那么,就可以避免有人自定义一个有破坏功能的java.lang.Integer被加载。这样可以有效的防止核心Java API被篡改。
3、"父加载器"和"子加载器"之间的关系是继承的吗?
4、双亲委派是怎么实现的?
双亲委派模型对于保证Java程序的稳定运作很重要,但它的实现并不复杂。
实现双亲委派的代码都集中在java.lang.ClassLoader的loadClass()方法之中:
代码不难理解,主要就是以下几个步骤:
1、先检查类是否已经被加载过
2、若没有加载则调用父加载器的loadClass()方法进行加载
3、若父加载器为空则默认使用启动类加载器作为父加载器。
4、如果父类加载失败,抛出ClassNotFoundException异常后,再调用自己的findClass()方法进行加载。
5、我能不能主动破坏这种双亲委派机制?怎么破坏?
知道了双亲委派模型的实现,那么想要破坏双亲委派机制就很简单了。
因为他的双亲委派过程都是在loadClass方法中实现的,那么想要破坏这种机制,那么就自定义一个类加载器,重写其中的loadClass方法,使其不进行双亲委派即可。
6、为什么重写loadClass方法可以破坏双亲委派,这个方法和findClass()、defineClass()区别是什么?
ClassLoader中和类加载有关的方法有很多,前面提到了loadClass,除此之外,还有findClass和defineClass等,那么这几个方法有什么区别呢?
loadClass() 就是主要进行类加载的方法,默认的双亲委派机制就实现在这个方法中。
findClass() 根据名称或位置加载.class字节码
definclass() 把字节码转化为Class
这里面需要展开讲一下loadClass和findClass,我们前面说过,当我们想要自定义一个类加载器的时候,并且想破坏双亲委派原则时,我们会重写loadClass方法。
那么,如果我们想定义一个类加载器,但是不想破坏双亲委派模型的时候呢?
这时候,就可以继承ClassLoader,并且重写findClass方法。findClass()方法是JDK1.2之后的ClassLoader新添加的一个方法。
这个方法只抛出了一个异常,没有默认实现。
JDK1.2之后已不再提倡用户直接覆盖loadClass()方法,而是建议把自己的类加载逻辑实现到findClass()方法中。
因为在loadClass()方法的逻辑里,如果父类加载器加载失败,则会调用自己的findClass()方法来完成加载。
所以,如果你想定义一个自己的类加载器,并且要遵守双亲委派模型,那么可以继承ClassLoader,并且在findClass中实现你自己的加载逻辑
7、说一说你知道的双亲委派被破坏的例子吧
双亲委派机制的破坏不是什么稀奇的事情,很多框架、容器等都会破坏这种机制来实现某些功能。
第一种被破坏的情况是在双亲委派出现之前。
由于双亲委派模型是在JDK1.2之后才被引入的,而在这之前已经有用户自定义类加载器在用了。所以,这些是没有遵守双亲委派原则的。
第二种,是JNDI、JDBC等需要加载SPI接口实现类的情况。
第三种是为了实现热插拔热部署工具。为了让代码动态生效而无需重启,实现方式时把模块连同类加载器一起换掉就实现了代码的热替换。
第四种时tomcat等web容器的出现。
第五种时OSGI、Jigsaw等模块化技术的应用。
8、为什么JNDI、JDBC等需要破坏双亲委派?
我们日常开发中,大多数时候会通过API的方式调用Java提供的那些基础类,这些基础类时被Bootstrap加载的。
但是,调用方式除了API之外,还有一种SPI的方式。
如典型的JDBC服务,我们通常通过以下方式创建数据库连接:
Connection conn = DriverManager.getConnection(“jdbc:mysql://localhost:3306/mysql”, “root”, “1234”);
在以上代码执行之前,DriverManager会先被类加载器加载,因为java.sql.DriverManager类是位于rt.jar下面的 ,所以他会被根加载器加载。
类加载时,会执行该类的静态方法。其中有一段关键的代码是:
ServiceLoader loadedDrivers = ServiceLoader.load(Driver.class);
这段代码,会尝试加载classpath下面的所有实现了Driver接口的实现类。
那么,问题就来了。
DriverManager是被根加载器加载的,那么在加载时遇到以上代码,会尝试加载所有Driver的实现类,但是这些实现类基本都是第三方提供的,根据双亲委派原则,第三方的类不能被根加载器加载。
那么,怎么解决这个问题呢?
于是,就在JDBC中通过引入ThreadContextClassLoader(线程上下文加载器,默认情况下是AppClassLoader)的方式破坏了双亲委派原则。
我们深入到ServiceLoader.load方法就可以看到:
第一行,获取当前线程的线程上下类加载器 AppClassLoader,用于加载 classpath 中的具体实现类。
9、为什么TOMCAT要破坏双亲委派?
我们知道,Tomcat是web容器,那么一个web容器可能需要部署多个应用程序。
不同的应用程序可能会依赖同一个第三方类库的不同版本,但是不同版本的类库中某一个类的全路径名可能是一样的。
如多个应用都要依赖hollis.jar,但是A应用需要依赖1.0.0版本,但是B应用需要依赖1.0.1版本。这两个版本中都有一个类是com.hollis.Test.class。
如果采用默认的双亲委派类加载机制,那么是无法加载多个相同的类。
所以,Tomcat破坏双亲委派原则,提供隔离的机制,为每个web容器单独提供一个WebAppClassLoader加载器。
Tomcat的类加载机制:为了实现隔离性,优先加载 Web 应用自己定义的类,所以没有遵照双亲委派的约定,每一个应用自己的类加载器——WebAppClassLoader负责加载本身的目录下的class文件,加载不到时再交给CommonClassLoader加载,这和双亲委派刚好相反。
10、谈谈你对模块化技术的理解吧!
操作系统
1、说说IO多路复用,select和epoll的区别和时间复杂度。
Mysql
1、隔离级别和对应的并发问题。
2、不可重复读的解决方法。
3、MVCC及其原理
MVCC是通过事务read_view的字段和记录里的两个隐藏列(trx_id 和roll pointer)进行比对,如果不满足可见行,会顺着undo log版本链找到满足其可见性的记录,从而控制并发事务访问同一个记录时的行为。
JVM
字符串常量池的相关知识
在Java中,即使两个不同的String对象都引用了字符串常量池中的同一个字符串值,这两个对象本身在堆内存中的地址仍然是不同的。这是因为每个通过new关键字创建的对象都会在堆内存中分配一个唯一的内存地址,无论它们的内容是否相同。
这里的关键点是区分两个概念:
字符串常量池中的字符串值:字符串常量池是JVM用来存储字符串字面量的一种机制。当相同的字符串字面量出现时,它们会指向常量池中的同一个字符串实例,以节省内存和提高效率。
堆内存中的String对象:即使两个String对象的内容相同,它们仍然是独立的对象实例,每个实例都有自己的内存地址。
以下是为什么两个对象地址不同的原因:
对象独立性:每个String对象都是独立的实例,即使它们包含相同的字符序列。每个实例都有自己的状态和行为(例如,它们可能有不同的哈希码,尽管它们的值相同)。
内存分配:当使用new关键字创建对象时,JVM会在堆内存中为该对象分配一个唯一的内存地址。每次调用new时,都会发生新的内存分配。
引用的概念:在Java中,引用就像是对象的指针。即使两个引用指向同一个值,这些引用本身也是不同的变量,持有不同的内存地址。
JVM调优
https://www.cnblogs.com/jimoliunian/p/12975201.html
解释一下TLAB
FullGC触发的时机
1、老年代空间满了(创建大对象,超过阈值会直接在老年代分配,如果老年代空间不足会触发Full GC)
2、方法区(指永久代)分配空间没有足够空间的话。
3、空间担保机制触发失败的时候:在进行minorGC前,如果老年代的剩余空间<新生代对象总和,且HandlePromotionFailure=false(该配置在jdk7中不再支持了),会直接触发full GC。如果HandlePromotionFailure=true,则继续比较历代老年代晋升对象的平均大小和老年代连续剩余空间大小,如果前者>后者,则FullGC,否则的话执行minorGC ,但还是有风险的。
java里堆和栈的区别,从内存空间连续性等角度考虑
存储内容
栈中存放局部变量(基本数据类型变量和对象的引用变量)、方法调用的上下文。每个线程运行时都有一个栈空间用于存储该线程的执行栈帧;
堆是所有线程共享的内存区域,用于存储java对象实例和数组。几乎所有的对象实例都在这里分配内存。
内存分配方式
栈是由jvm虚拟机自动分配和释放。当进入一个方法时,JVM会在栈上为该方法创建一个栈帧,并在方法结束时销毁该栈帧。
堆是GC管理,对象实例的分配通常使用new关键字。垃圾回收器会负责回收不在被引用的对象所用的内存。
内存分配连续性
栈的内存空间是连续的,且栈帧的分配和释放时顺序的,保证了内存的连续性。
堆的内存空间不保证是连续的,由于堆是动态分配内存的区域,随着对象的创建和销毁,可能会出现内存碎片。
生长方向
栈:由高到低 堆:由低向高
内核态和用户态是什么?怎么实现切换?
1、创建一个native方法
2、用JNI调用native方法
3、编译并加载包含native方法的本地库
4、运行包含调用native方法的代码
spring框架
springboot自动配置的原理简述
@springbootApllication注解可以视作三部分,其中自动配置的关键是@Enableautoconfiguration,它通过引入一个configurationImportSelector,扫描spring.factories下所有的自动配置类,并使用@import导入配置类,@conditional进行条件检查,确保只有符合条件的自动配置类生效。
一旦自动配置类生效,springboot会根据配置类注册所需的bean,同时用户可以通过显式声明覆盖自动配置的默认行为。
https://www.cnblogs.com/lgx211/p/18508668参见这个连接
三级缓存原理和其数据结构
https://blog.youkuaiyun.com/u010499733/article/details/105455081
三级缓存:
三级缓存都是map结构,一级缓存内是初始化完全的对象、二级缓存是早期对象、三级缓存是对象工厂。核心是通过对象工厂提供对象的早期引用到二级缓存内,从二级缓存内取得需要注入的对象或其代理对象的早期引用,完成初始化。
bean的生命周期
1)实例化:Spring根据配置或注解方式,创建Bean实例并将其存储在容器中。
2)属性赋值,Spring自动将Bean的属性值从配置或者注解的方式注入到bean实例中
3)回调Aware方法,如BeanNameAware,BeanFactoryAware。
4)调用BeanPostProcessor的初始化前的方法
5)调用初始化方法
6)调用BeanPostProcessor初始化后的方法。在这里实现AOP。*注意:BeanPostProcessor#postProcessBeforeInitialization() 是适用于所有Bean的方法,而@PostConstruct则是适用于指定有这个方法的bean。

7)如果创建的Bean是单例的,则会把Bean放入单例池内。
8)使用bean
9)Spring容器关闭时调用DisposableBean中的destroy()方法。
spring容器是怎么管理bean的
RocketMQ
如何保证消息队列消费的一致性
1、本地事务和生产者发送消息的双写一致性
通过维护消息的两个状态 prepared 和 commit,①生产者先发送消息到队列,队列将该消息标记为half;②生产者执行本地事务,成功则返回COMMIT→消息队列将该条消息标记为可消费;失败则返回ROLLBACK,消息队列将该条消息删除。③如果队列没有收到half消息的后续状态,则调用一个回调接口查询数据库的情况确认事务是否执行成功,根据回调的状态执行②。
2、如果保证消息不被重复消费
通过查询每一条消息的唯一ID在数据库中是否存在确保消息只被消费一次
3、消息队列如何保证消费者成功消费消息?
等待消费者返回ack,返回后修改offset,如果没有返回,根据设置的超时重发的次数重发消息。超过设置的值则把消息放入死信队列。
4、Broker配置同步刷盘 + 同步复制
新的改变
我们对Markdown编辑器进行了一些功能拓展与语法支持,除了标准的Markdown编辑器功能,我们增加了如下几点新功能,帮助你用它写博客:
- 全新的界面设计 ,将会带来全新的写作体验;
- 在创作中心设置你喜爱的代码高亮样式,Markdown 将代码片显示选择的高亮样式 进行展示;
- 增加了 图片拖拽 功能,你可以将本地的图片直接拖拽到编辑区域直接展示;
- 全新的 KaTeX数学公式 语法;
- 增加了支持甘特图的mermaid语法1 功能;
- 增加了 多屏幕编辑 Markdown文章功能;
- 增加了 焦点写作模式、预览模式、简洁写作模式、左右区域同步滚轮设置 等功能,功能按钮位于编辑区域与预览区域中间;
- 增加了 检查列表 功能。
功能快捷键
撤销:Ctrl/Command + Z
重做:Ctrl/Command + Y
加粗:Ctrl/Command + B
斜体:Ctrl/Command + I
标题:Ctrl/Command + Shift + H
无序列表:Ctrl/Command + Shift + U
有序列表:Ctrl/Command + Shift + O
检查列表:Ctrl/Command + Shift + C
插入代码:Ctrl/Command + Shift + K
插入链接:Ctrl/Command + Shift + L
插入图片:Ctrl/Command + Shift + G
查找:Ctrl/Command + F
替换:Ctrl/Command + G
合理的创建标题,有助于目录的生成
直接输入1次#,并按下space后,将生成1级标题。
输入2次#,并按下space后,将生成2级标题。
以此类推,我们支持6级标题。有助于使用TOC语法后生成一个完美的目录。
如何改变文本的样式
强调文本 强调文本
加粗文本 加粗文本
标记文本
删除文本
引用文本
H2O is是液体。
210 运算结果是 1024.
插入链接与图片
链接: link.
图片:
带尺寸的图片:
居中的图片:
居中并且带尺寸的图片:
当然,我们为了让用户更加便捷,我们增加了图片拖拽功能。
如何插入一段漂亮的代码片
去博客设置页面,选择一款你喜欢的代码片高亮样式,下面展示同样高亮的 代码片.
// An highlighted block
var foo = 'bar';
生成一个适合你的列表
- 项目
- 项目
- 项目
- 项目
- 项目1
- 项目2
- 项目3
- 计划任务
- 完成任务
创建一个表格
一个简单的表格是这么创建的:
| 项目 | Value |
|---|---|
| 电脑 | $1600 |
| 手机 | $12 |
| 导管 | $1 |
设定内容居中、居左、居右
使用:---------:居中
使用:----------居左
使用----------:居右
| 第一列 | 第二列 | 第三列 |
|---|---|---|
| 第一列文本居中 | 第二列文本居右 | 第三列文本居左 |
SmartyPants
SmartyPants将ASCII标点字符转换为“智能”印刷标点HTML实体。例如:
| TYPE | ASCII | HTML |
|---|---|---|
| Single backticks | 'Isn't this fun?' | ‘Isn’t this fun?’ |
| Quotes | "Isn't this fun?" | “Isn’t this fun?” |
| Dashes | -- is en-dash, --- is em-dash | – is en-dash, — is em-dash |
创建一个自定义列表
-
Markdown
- Text-to- HTML conversion tool Authors
- John
- Luke
如何创建一个注脚
一个具有注脚的文本。2
注释也是必不可少的
Markdown将文本转换为 HTML。
KaTeX数学公式
您可以使用渲染LaTeX数学表达式 KaTeX:
Gamma公式展示 Γ ( n ) = ( n − 1 ) ! ∀ n ∈ N \Gamma(n) = (n-1)!\quad\forall n\in\mathbb N Γ(n)=(n−1)!∀n∈N 是通过欧拉积分
Γ ( z ) = ∫ 0 ∞ t z − 1 e − t d t . \Gamma(z) = \int_0^\infty t^{z-1}e^{-t}dt\,. Γ(z)=∫0∞tz−1e−tdt.
你可以找到更多关于的信息 LaTeX 数学表达式here.
新的甘特图功能,丰富你的文章
- 关于 甘特图 语法,参考 这儿,
UML 图表
可以使用UML图表进行渲染。 Mermaid. 例如下面产生的一个序列图:
这将产生一个流程图。:
- 关于 Mermaid 语法,参考 这儿,
FLowchart流程图
我们依旧会支持flowchart的流程图:
- 关于 Flowchart流程图 语法,参考 这儿.
导出与导入
导出
如果你想尝试使用此编辑器, 你可以在此篇文章任意编辑。当你完成了一篇文章的写作, 在上方工具栏找到 文章导出 ,生成一个.md文件或者.html文件进行本地保存。
导入
如果你想加载一篇你写过的.md文件,在上方工具栏可以选择导入功能进行对应扩展名的文件导入,
继续你的创作。
注脚的解释 ↩︎



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









