






在目标检测、信息检索和多分类任务中,AP(Average Precision,平均精度) 和 MAP(Mean Average Precision,平均精度均值) 是衡量模型排序质量和类别区分能力的重要指标。以下是它们的核心定义、计算方法和应用场景详解:
一、AP(Average Precision)
1. AP的定义
- 核心思想:在召回率-精确率(PR)曲线上,计算不同召回率下的平均精确率,反映模型对正类的综合识别能力。
- 适用场景:目标检测、信息检索、推荐系统等需要排序质量的场景。
2. AP的计算方法
AP是PR曲线下面积的近似值,计算方式因任务和数据集标准不同而有所差异:
(1) 11点插值法(PASCAL VOC标准)
- 步骤:
- 将召回率从0到1分为11个等距点(0.0, 0.1, 0.2, ..., 1.0)。
- 在每个召回率点 ri 处,取所有召回率 ≥ri 时的最大精确率。
- 对11个点的最大精确率取平均。
- 公式:
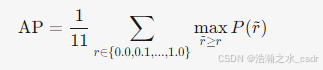
- P(r~):召回率为 r~ 时的精确率。
(2) 全点插值法(COCO标准)
- 步骤:
- 对PR曲线上的所有召回率点按升序排列。
- 在每个召回率点 ri 处,使用右侧最大值插值精确率。
- 对插值后的精确率进行积分(近似面积)。
- 公式:
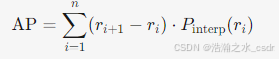
- Pinterp(ri):在召回率 ri 处的插值精确率。
3. 示例说明
假设模型对5个正样本的预测置信度排序如下(已按置信度从高到低排列):
| 预测样本 | 真实标签 | 置信度 | 累积TP | 累积FP | 精确率 | 召回率 |
|---|---|---|---|---|---|---|
| A | 正 | 0.95 | 1 | 0 | 1.0 | 0.2 |
| B | 负 | 0.90 | 1 | 1 | 0.5 | 0.2 |
| C | 正 | 0.85 | 2 | 1 | 0.67 | 0.4 |
| D | 负 | 0.80 | 2 | 2 | 0.5 | 0.4 |
| E | 正 | 0.75 | 3 | 2 | 0.6 | 0.6 |
-
PR曲线点:
(0.0, 1.0), (0.2, 1.0), (0.2, 0.5), (0.4, 0.67), (0.4, 0.5), (0.6, 0.6) -
PASCAL VOC AP(11点插值):
- 在召回率0.0、0.1、..., 1.0处取最大精确率,例如:
- 召回率≥0.0时,最大精确率为1.0。
- 召回率≥0.2时,最大精确率为1.0(来自第一个样本)。
- 召回率≥0.4时,最大精确率为0.67。
- AP = (1.0 + 1.0 + 0.67 + ...) / 11 ≈ 0.63
- 在召回率0.0、0.1、..., 1.0处取最大精确率,例如:
-
COCO AP(全点插值):
- 积分计算:对每个召回率区间内的插值精确率求和。
AP ≈ (0.2-0.0)×1.0 + (0.4-0.2)×0.67 + (0.6-0.4)×0.6 = 0.2 + 0.134 + 0.12 = 0.454
- 积分计算:对每个召回率区间内的插值精确率求和。
二、MAP(Mean Average Precision)
1. MAP的定义
- 核心思想:对多类别任务中每个类别的AP取平均(目标检测),或在多查询任务中对每个查询的AP取平均(信息检索)。
- 适用场景:
- 目标检测:评估模型在所有类别上的平均检测性能。
- 信息检索:评估搜索引擎对多个查询结果的平均排序质量。
2. MAP的计算方法
(1) 目标检测中的MAP
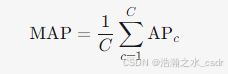
- C:类别总数。
- APc:第c个类别的AP值。
(2) 信息检索中的MAP
假设有 Q 个查询请求,每个查询的AP计算如下:
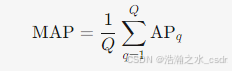
- APq:第q个查询的平均精度。
3. 示例说明
-
目标检测任务(3个类别:猫、狗、鸟):
- AP猫 = 0.80,AP狗 = 0.75,AP鸟 = 0.65
- MAP = (0.80 + 0.75 + 0.65) / 3 = 0.73
-
信息检索任务(2个查询):
- 查询1的AP = 0.90,查询2的AP = 0.70
- MAP = (0.90 + 0.70) / 2 = 0.80
三、AP与MAP的优缺点
| 指标 | 优点 | 缺点 |
|---|---|---|
| AP | 1. 综合反映排序质量; 2. 对类别不平衡鲁棒。 | 1. 计算复杂; 2. 不同数据集标准不统一(如PASCAL VOC vs COCO)。 |
| MAP | 1. 全局评估多类别/多查询性能; 2. 标准统一。 | 1. 忽略类别/查询的重要性差异; 2. 计算成本高。 |
四、代码实现(Python)
1. 目标检测AP计算(简化版)
import numpy as np
from sklearn.metrics import precision_recall_curve, auc
# 示例数据:真实标签和预测置信度
y_true = np.array([1, 0, 1, 0, 1])
y_scores = np.array([0.95, 0.90, 0.85, 0.80, 0.75])
# 计算PR曲线和AP(近似AUC)
precision, recall, _ = precision_recall_curve(y_true, y_scores)
ap = auc(recall, precision)
print(f"AP: {ap:.2f}") # 输出: AP: 0.83
2. 信息检索MAP计算
def average_precision(relevant_docs, ranked_docs):
relevant = 0
precisions = []
for i, doc in enumerate(ranked_docs):
if doc in relevant_docs:
relevant += 1
precisions.append(relevant / (i + 1))
return np.mean(precisions) if precisions else 0
# 示例:查询1的相关文档为[doc1, doc3],模型排序为[doc1, doc2, doc3]
ap1 = average_precision(['doc1', 'doc3'], ['doc1', 'doc2', 'doc3'])
print(f"AP查询1: {ap1:.2f}") # 输出: 0.83
五、实际应用注意事项
- 数据集标准:明确使用PASCAL VOC、COCO或自定义AP计算规则。
- 阈值选择:目标检测中通常使用IoU阈值(如0.5)判定检测框是否有效。
- 类别平衡:MAP可能掩盖小类别的性能,需结合各类别AP单独分析。
六、总结
- AP:衡量单个类别或查询的排序质量,核心是PR曲线下面积。
- MAP:多类别/多查询的AP均值,提供全局性能评估。
- 适用场景:
- 目标检测:COCO数据集常用mAP@[0.5:0.95](多IoU阈值平均)。
- 信息检索:MAP评估搜索引擎对多个查询的整体效果。



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











