



一、下载地址
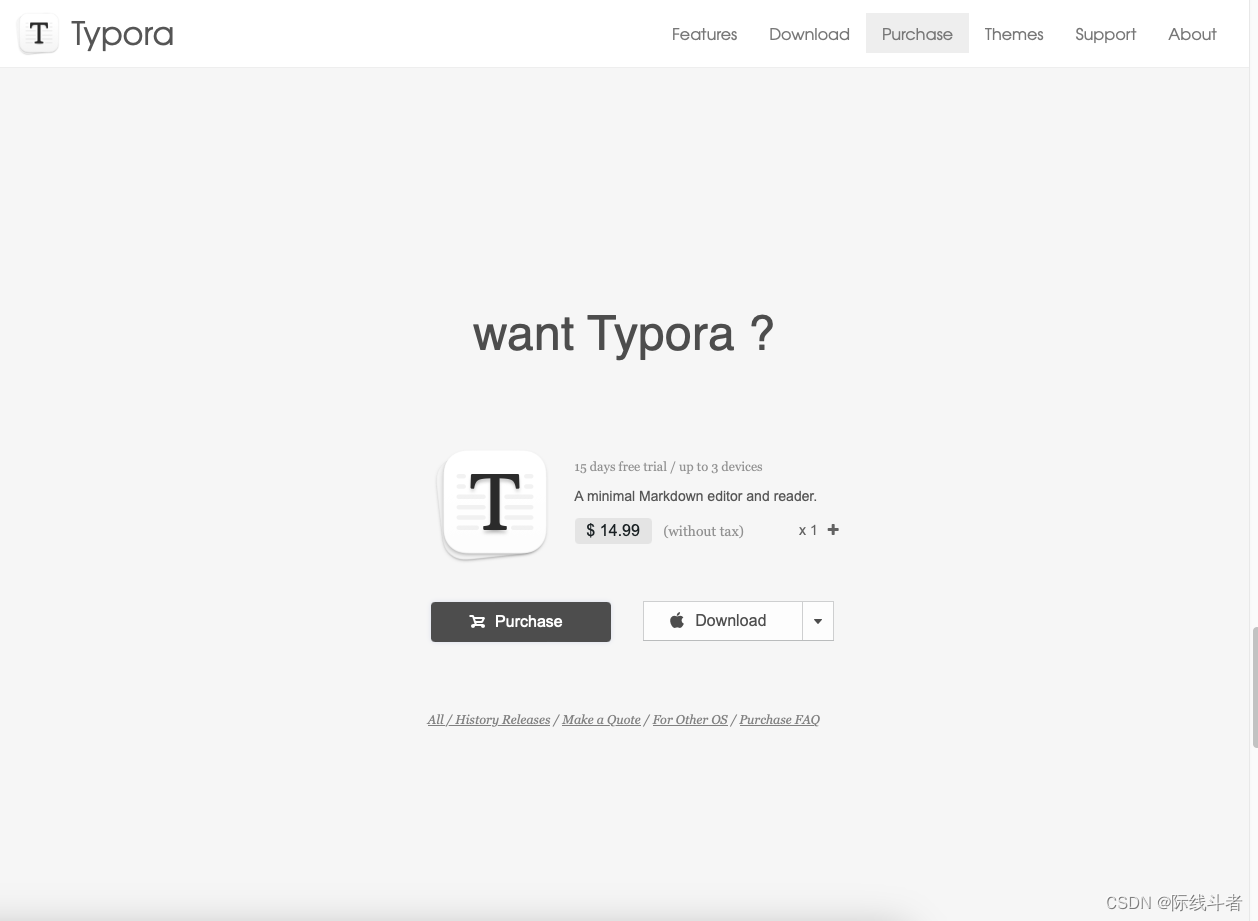
注意:正确且唯一的激活方式是点击“Purchase”购买许可进行软件的使用
二、安装软件
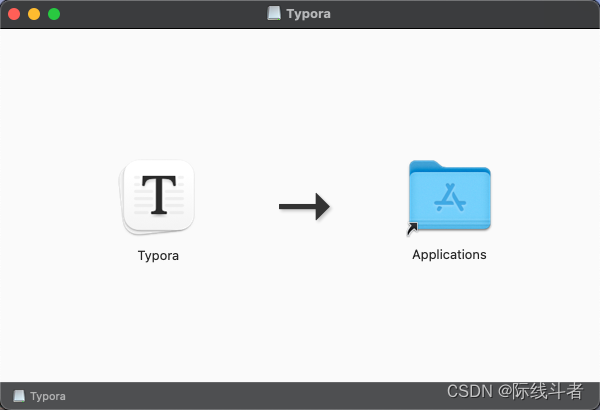
1. 点击下载的dmg文件,用鼠标拖动Typora图标到Applications中
三、跳过激活
1. 打开访达,点击应用程序,在Typora右击打开应用根目录

2. 用记事本打开下面目录下的LicenseIndex.xxxxxxxxxxx.chunk.js文件
![]()
3. cmd+f 搜索 e.hasActivated
//将
e.hasActivated=“true”=e.hasActivated
//改为
e.hasActivated = "true" == "true"
4. cmd+s保存,然后重启软件
四、自动关闭欢迎弹窗
就是关闭应用第一个打开的窗口
1. 用记事本打开下面目录下的LicenseIndex.xxxxxxxxxxx.chunk.js文件![]()
2. cmd+f 搜索 e.exports=n.p+"static/media/
//e.exports=n.p+"static/media/完整语句
e.exports=n.p+"static/media/icon.06a6aa23.png"}
//在png" 和 }间添加下面内容
window.onload = function () {setTimeout(() => {window.Setting.invoke("close");}, 1);};3. cmd+s保存,然后重启软件
五、修改"未激活"标签
1. 用记事本打开下面目录下的Panel.strings文件![]()
2. cmd+f 搜索 UNREGISTERED
//将
"UNREGISTERED" = "未激活";
//改为
"UNREGISTERED" = " ";3. cmd+s保存,然后重启软件

















 9263
9263

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









