







小伙们大家好,本篇是并发编程的第三篇,上一节跟大家讲了synchronized,这一节我们来聊聊他的好兄弟volatile,volatile的功能稍微差一点,他只有可见性和有序性,那么他的底层是如何保障可见性和有序性,以及什么是Java内存模型,本篇文章将给出通俗易懂的解释。。
可见性
什么是可见性
先来看一段代码
/**
* @author jack xu
*/
public class VolatileDemo {
public static boolean stop = false;
public static void main(String[] args) throws InterruptedException {
new Thread(() -> {
while (true) {
if (stop) {
System.out.println("--------stop变为true了,停止----------");
break;
}
//这里不能有语句,有语句循环之间就有间隙
//System.out.println("stop还是false");
}
}).start();
Thread.sleep(1000);
stop = true;
}
}
首先定义一个变量 stop = false,然后启动一个线程,这个线程里面只干一件事,就是不断的循环判断 stop 的值,当为 true 时跳出循环,然后在主线程中是睡了一秒,把 stop 变为 true,我们来看下运行效果。
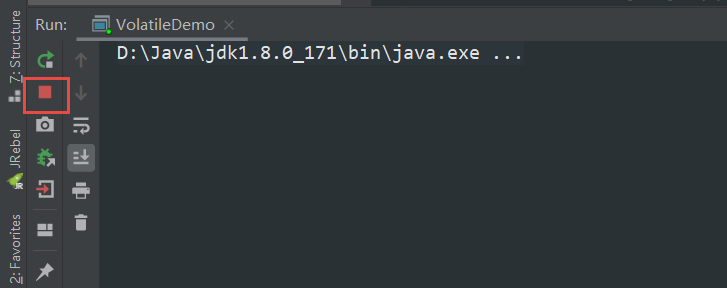
惊奇的是红灯亮起,程序没有停止,而是一直在循环,这与我们预期的结果不符,我们希望看到的是,子线程在运行一秒钟后,主线程将 stop变为了 false,子线程就应该跳出循环结束程序。这里就要引出今天的可见性问题了。。
可见性指的是,某个线程对共享变量进行了修改,其它线程能够及时看到修改后的最新值。在单线程中,做了一个变量的修改,程序是能够立即看到的。然而在本例中是发生在多线程环境下的,可能会出现读线程不能及时读取到其他线程写入的最新的值。
注意我标出来的几个关键字,第一个是可见性问题出现在多线程中,第二个是可能,为什么说是可能呢,大家注意我上面源代码中有一行注释掉的代码System.out.println(“stop还是false”),小伙伴可以试下把这句话放开,在执行下程序,发现程序还是会停止的,这是因为语句循环之间有了间隙,这是在给CPU一个喘气的时间,让CPU有时间有间隙去拿最新的stop的值,所以可见性问题看你代码的写法,有时候会出现,有时候不会出现。最后就是及时,及时的意思就是立刻、立即、马上,你把变量的值变掉以后,我要立刻能够读到最新的值,而不是过一段时间才能读到,或者是一直读不到。
volatile如何保障可见性
那么怎么来保障可见性问题呢,答案很简单,今天的主角就登场了,我们只需要在变量前面加一个volatile关键字即可完美解决,大家看下面的图,加上以后程序在执行一秒钟以后就结束了,如我们所愿。
我们可以使用hsdis这个工具,来查看前面演示的这段代码的汇编指令
mov 0x20(%rsp),%rsi
mov %rax,%r10
shr $0x3,%r10
mov %r10d,0xc(%rsi)
shr $0x9,%rsi
movabs $0x7f55dd1cb000,%rdi
movb $0x0,(%rsi,%rdi,1)
lock addl $0x0,(%rsp)
我们不需要理解以上指令,只需要关注最后一行。可以看到最后一行使用了 lock 关键字。lock
是一种控制指令,在多处理器环境下,lock 汇编指令可以基于总线锁或者缓存锁的机制来达到可见性的一个效果。
硬件层面
产生可见性问题的根源其实是计算机底层硬件引起的,现在让我们来看下他究竟是怎么一回事。
CPU高速缓存
大家一定都知道摩尔定律。根据定律,CPU 每18个月速度将会翻一番。CPU 的计算速度提升了,但是内存的访问速度却没有什么大幅度的提升。瓶颈出现在对内存的访问上,没关系,我们可以使用缓存啊,这已经是路人皆知的手段了。CPU 更狠一点,用了 L1、L2、L3,一共三级缓存。其中 L1 缓存根据用途不同,还分为 L1i 和 L1d 两种缓存。如下图:

有了高速缓存的存在以后,每个 CPU 的处理过程是:先将计算需要用到的数据缓存在 CPU 高速缓存中,在 CPU进行计算时,直接从高速缓存中读取数据并且在计算完成之后写入到缓存中,再把缓存中的数据同步到主内存。由于在多核CPU中,每个线程可能会运行在不同的 CPU 内,并且每个线程拥有自己的高速缓存。同一份数据可能会被缓存到多个 CPU 中,如果在不同 CPU 中运行的不同线程看到同一份内存的缓存值不一样就会存在缓存不一致的问题。
解决缓存一致性问题
为了解决缓存不一致的问题,在 CPU 层面做了很多事情,主要提供了两种解决办法。
1、总线锁
总线锁,简单来说就是,在多 CPU 下,当其中一个处理器要对共享内存进行操作的时候,在总线上发出一个 LOCK#信号,这个信号使得其他处理器无法通过总线来访问到共享内存中的数据,总线锁定把 CPU 和内存之间的通信锁住了,这使得锁定期间,其他处理器不能操作其他内存地址的数据,所以总线锁定的开销比较大,这种机制显然是不合适的。
2、缓存锁
最好的方法就是控制锁的保护粒度,我们只需要保证对于被多个 CPU 缓存的同一份数据是一致的就行,所以引入了缓存锁,它核心机制是基于缓存一致性协议来实现的。
常见的协议有MSI,MESI,MOSI 等。
我们这里介绍 MESI 协议,MESI简单来说就是 M(Modify) 、E(Exclusive) 、S(Shared) 、I(Invalid) 四种状态的首字母缩写。当一个 CPU 修改了 Cache中 的数据,会通知其他缓存了这个数据的 CPU,其他 CPU 会把Cache中这份数据置为I状态,要读取数据的话,直接去内存中获取,不会再从Cache中获取了。
然而,看到这里一切看上去都很完美,MESI 解决了缓存一直性问题,故事到这里就可以结束了。其实不然,MESI 不是万能的,还是可能会产生可见性问题,不然怎么还需要加 volatile 关键字呢?其实MESI有 store buffer 机制,还是会存在一些问题,各位看官你继续往下看。
内存屏障
小伙们看下图,CPU0 要对一个在缓存中共享的变量进行写入,首先需要发送一个失效的消息给到其他缓存了该数据的 CPU1,并且要等到CPU1的 ack 回执,但是 CPU0 在这段时间内都会处于阻塞状态,为了避免阻塞带来的资源浪费,CPU底层又引入了 Store Bufferes。
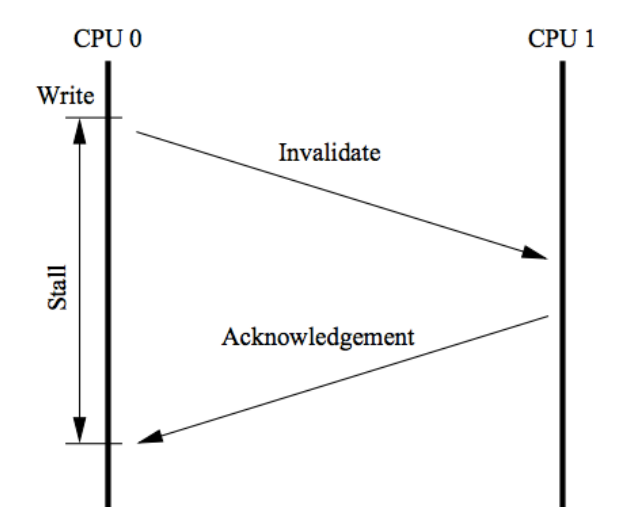
大家看下图,CPU0 只需要在写入共享数据时,直接把数据写入到 store
bufferes 中,同时发送 invalidate 消息,然后继续去处理其他指令。
当收到 CPU1 发送了invalidate acknowledge 消息
时,再将 store bufferes 中的数据数据存储至 cache line
中,最后再从缓存行同步到主内存。
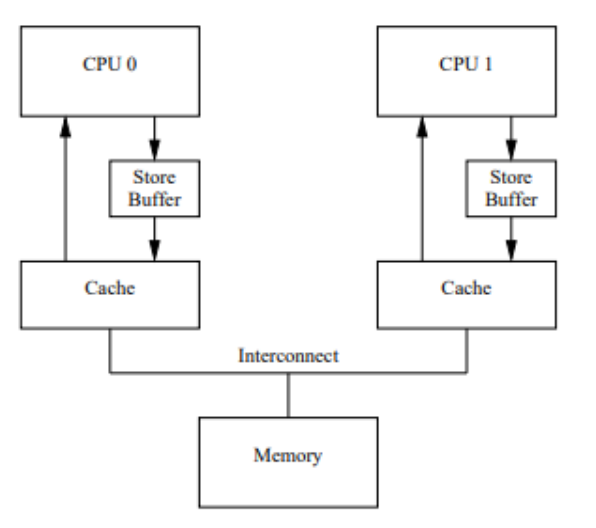
这么做其实会产生一个问题,那就是异步,数据什么时候提交是不确定的,因为需要等待其他 CPU
给回复才会进行数据同步。其次硬件底层 CPU 为了提高效率,或者说在空闲的时候,有时候还会进行乱序执行,而这样的行为还是可能会带来可见性问题。这时硬件工程师就抓狂了,硬件一直在做优化,在做升级,在为提高效率想办法,可这样却是好心办坏事了,这样会导致我们程序员写的代码,运行出来并不是我们想要的结果,既然这样,硬件工程师就说了,我也不知道怎么优化了,我给你提供给指令,你自己去控制吧,这个指令就是memory barrier(内存屏障),x86的 memory barrier 指令包括 lfence(读屏障)、sfence(写屏障)、mfence(全屏障)三种。
- 写屏障:告诉处理器在写屏障之前的所有已经存储在存储缓存 (store bufferes) 中的数据同步
到主内存。 - 读屏障:处理器在读屏障之后的读操作,都在读屏障之后执行。配合写屏障,使得写屏障之前
的内存更新对于读屏障之后的读操作是可见的。 - 全屏障:确保屏障前的内存读写操作的结果提交到内存之后,再执行屏障后的读写操作。
内存屏障的作用可以通过防止 CPU 对内存的乱序访问来保证共享数据在多线程并行执行下的可见性,这个屏障怎么来加呢?回到最开始我们讲 volatile 关键字的代码,这个关键字会生成一个 lock 的汇编指令,这个指令其实就相当于实现了一种内存屏障。
Java内存模型
上面讲的都是硬件的知识,内存屏障、重排序这些东西都是和平台以及硬件架构有关系的。而 Java 有一次编写,多处运行的特点,我们作为程序员,也不应该关心平台相关的问题,更不用关心这些所谓的内存屏障。
JAVA内存模型即JMM(Java Memory Model),有些人会和 Java 内存结构混淆。虽然两者名字很接近,但是指的是不同的东西,Java 内存结构描述的是 JVM 对内存的逻辑划分。
JMM 属于语言级别的抽象内存模型,可以简单理解为对硬件模型的抽象,它定义了共享内存中多线程程序读写操作的行为规范。它可以让程序员不用关心硬件底层,它最核心的价值在于解决可见性和有序性。
工作方式
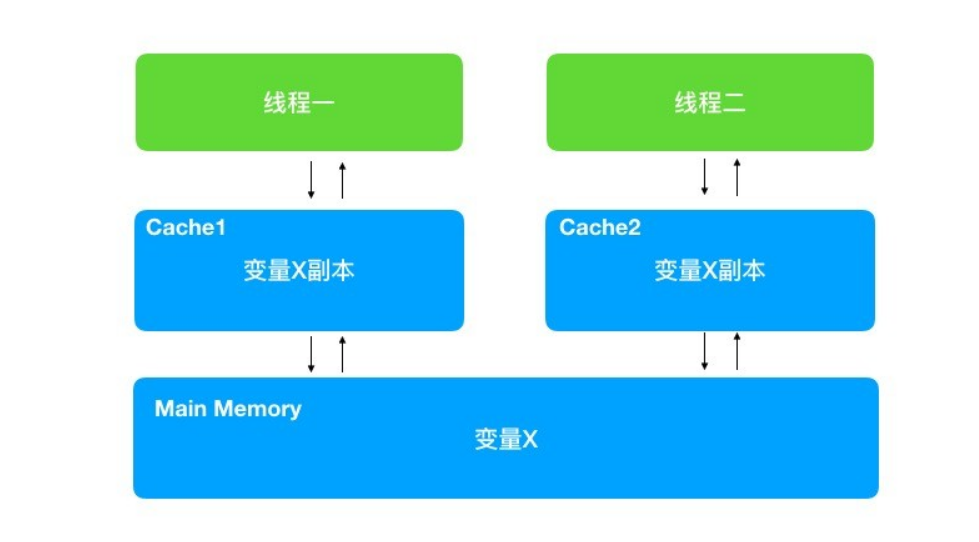
JMM 抽象模型分为主内存、工作内存。工作内存是每个线程独占的,线程对共享变量的所有操作都必须在工作内存中进行,不能直接读写主内存中的变量,当要修改的时候,需要先从主内存中拿到数据,复制到工作内存,然后在工作内存中对数据进行修改,再刷新回主内存。读的时候,将主内存中最新的共享变量的值更新到工作内存中。
大家发现上图的 Java 内存模型和 CPU 缓存模型图长的差不多,JMM其实是参考的 CPU 缓存模型,但不是一一对等的,因为 Java 内存模型是一种抽象的东西,所以 JMM 中的数据最终是存储在 CPU 的缓存、寄存器和内存上的。
重排序问题
在之前写的一篇文章 简单的单例模式其实不简单 中,介绍了一种DCL写法,这里面就需要给变量加上 volatile 关键字,目的就是为了防止指令重排。往往我们编写的程序,为了提高程序的执行性能,编译器和处理器都会对指令做重排序,从源代码到最终执行的指令,可能会经过三种重排序。

可想而知,如果任由处理器优化和编译器对指令重排的话,就可能导致各种各样的问题。所以在 JMM 层面又提供了内存屏障,分为四种。
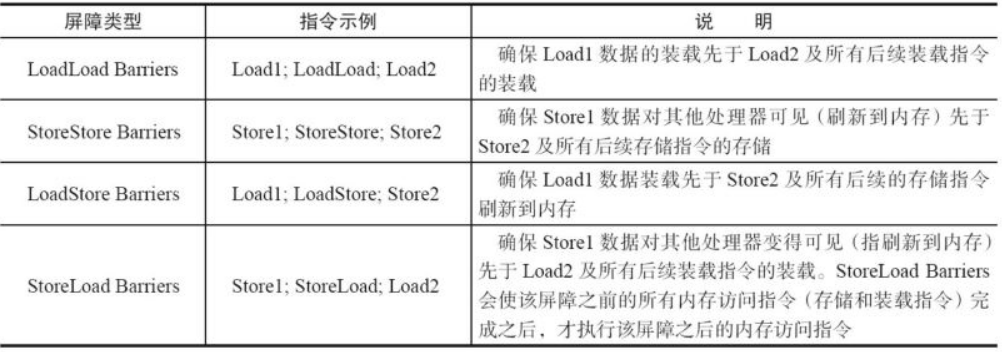
上面四种小伙伴如果不理解没事,所谓的内存屏障就是在屏障前的所有指令可以重排序的,屏障之后的指令也可以重排序,但是重排序的时候不能越过内存屏障。 这样就能防止重排,达到有序性了。
实现方式
JMM 提供了一些禁用缓存以及进制重排序的方法,来解决可见性和有序性问题。这些方法大家都很熟悉:volatile、synchronized、final、concurren包等;
最后我们来讲一讲 JMM 到底制定了哪些规范。。
Happens-Before规则
1、程序顺序规则。一个线程中的每个操作,happens-before 于该线程中的任意后续操作, 可以简单认为是 as-if-serial 。在单线程中的代码顺序不管怎么变,对于结果来说是不变的。
2、volatile 变量规则。上文已经提到过了,volatile变量的写操作会早于对其的读操作。
3、传递规则。如果A早于B执行,B早于C执行,那么A一定早于C执行。
4、线程启动原则。A线程中调用threadB.start()方法,那么threadB.start()方法会早于B线程中中的任何动作执行。
5、线程终结规则。如果线程A终结了,并且导致另外一个线程B中的 ThreadA.join() 方法取得返回,那么线程A中所有的操作都早于线程B在 ThreadA.join() 之后的动作发生。
6、上锁原则。不同线程对同一个锁的 lock 操作一定在 unclock 前。
我这里列出了常见的六个,网上可能说的是八大原则,如果需要深入了解的,小伙们也可以自行查阅。我们只有充分理解了 happens-before 原则,才能在编写多线程程序的时候,尽量避免数据的不一致性,让多线程程序在必要的时候按照我们设计的顺序执行,防止整个程序陷入混乱。
总结
小伙们,本篇文章是我在众多博客中准备最久,翻阅资料最多的一篇,因为 volatile 和 JMM 十分的抽象,不像别的东西做下实验就能看的到摸得着,而这个需要我们一点点去摸索,去吃透他。大家在看文章的时候静下心,耐下心,一遍看不懂就多看几遍。作者水平有限,每一个知识点我都会力求正确,如有疑问欢迎留言交流,如果你觉得写的不错,也请点赞支持。。

















 1251
1251

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









