







 超级会员免费看
超级会员免费看
 本文介绍了大数据的概念、主要解决的问题和4V特征,并详细阐述了大数据技术体系,包括数据采集(如Sqoop、Flume、Kafka)、数据存储(如Hdfs、HBase、Redis、Kafka)、资源管理(如YARN)、通用计算(如MapReduce、Spark Core)、数据分析(如Hive、Spark、Storm、Spark Streaming、Flink)、任务调度(如Azkaban)、数据可视化(如Superset)和分布式资源协调(如Zookeeper)。
本文介绍了大数据的概念、主要解决的问题和4V特征,并详细阐述了大数据技术体系,包括数据采集(如Sqoop、Flume、Kafka)、数据存储(如Hdfs、HBase、Redis、Kafka)、资源管理(如YARN)、通用计算(如MapReduce、Spark Core)、数据分析(如Hive、Spark、Storm、Spark Streaming、Flink)、任务调度(如Azkaban)、数据可视化(如Superset)和分布式资源协调(如Zookeeper)。
目录
一、概念
传统数据处理应用软件不足以处理(存储和计算)它们的大而复杂的数据集。
二、主要解决
海量数据的存储和运算问题。
三、特征(4V)
容量大、种类多、速度快、价值高
1.容量(volume):数据的大小决定所考虑的数据的价值和潜在的信息
2.种类(variety):数据类型的多样性,包括:文本、图片、视频、音频
结构化数据:可以用二维数据库表来抽象,抽取数据规律;
半结构化数据:介于结构化和非结构化之前,主要指XML、HTML等;
非结构化数据:不可用二维表抽象,如:图片、图像、音频、视频等
3.速度(velocity):指获取数据的速度以及处理数据的速度
数据的生产呈指数式爆炸式增长;
处理数据要求的延时越来越低
4.价值(value):合理运用大数据,一低成本创造高价值
综合价值大,隐含价值大;
单条数据记录无价值,无用数据多
四、应用场景
待补充
五、技术体系
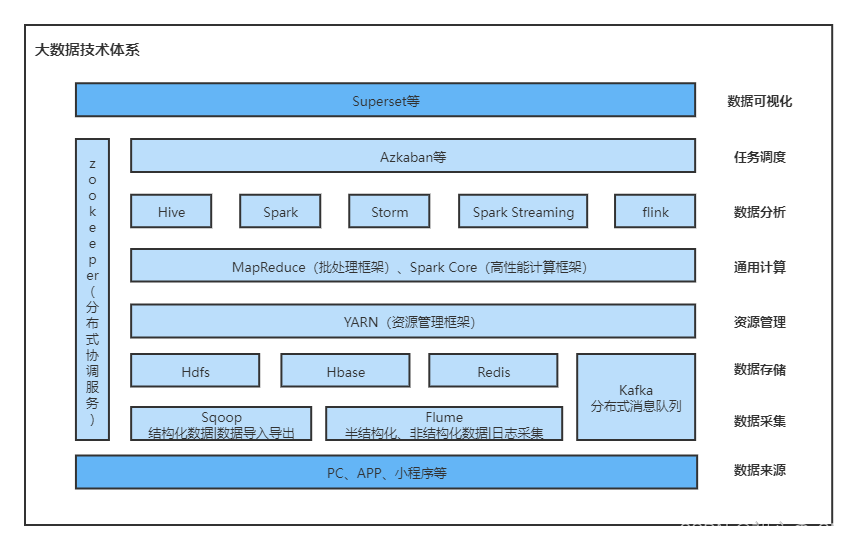
Tips:内容变更实时更新
1.数据采集
Sqoop
Flume
Kafka
2.数据存储
Hdfs Hadoop介绍_初心の GP的博客-优快云博客Apache Hadoop项目是一个提供高可靠,可扩展(横向)的分布式计算的开源软件平台。允许使用简单的编程模型跨计算机集群分布式处理大型数据集。它旨在从单个服务器扩展到数千台计算机,每台计算机都提供本地计算和存储。Hadoop本身不是依靠硬件来提供高可用性,而是设计用于检测和处理应用程序层的故障,从而在计算机集群之上提供高可用性服务,每个计算机都可能容易出现故障。产生背景1.Hadoop最早起源于Nutch。Nutch的目的是构建一个大型的全网搜索引擎(网页抓取、... https://blog.youkuaiyun.com/a318199328/article/details/121611085
https://blog.youkuaiyun.com/a318199328/article/details/121611085
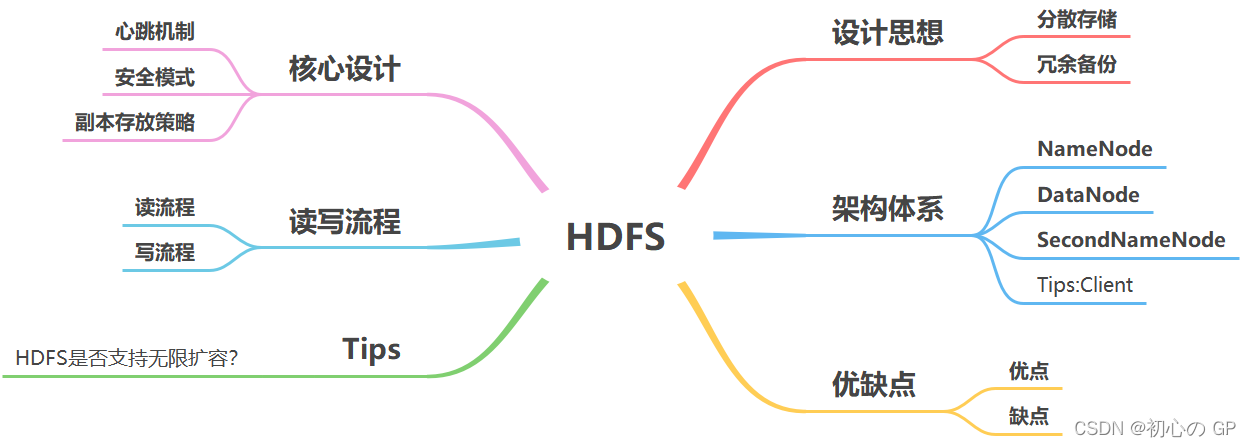 Hdfs总结
Hdfs总结 https://blog.youkuaiyun.com/a318199328/article/details/121809545
https://blog.youkuaiyun.com/a318199328/article/details/121809545
HBase
Redis
Kafka
3.资源管理
YARN
4.通用计算
MapReduce
Spark Core
5.数据分析
Hive
Spark
Storm
Spark Streaming
Flink
6.任务调度
Azkaban
7.数据可视化
Superset
8.分布式资源协调
Zookeeper
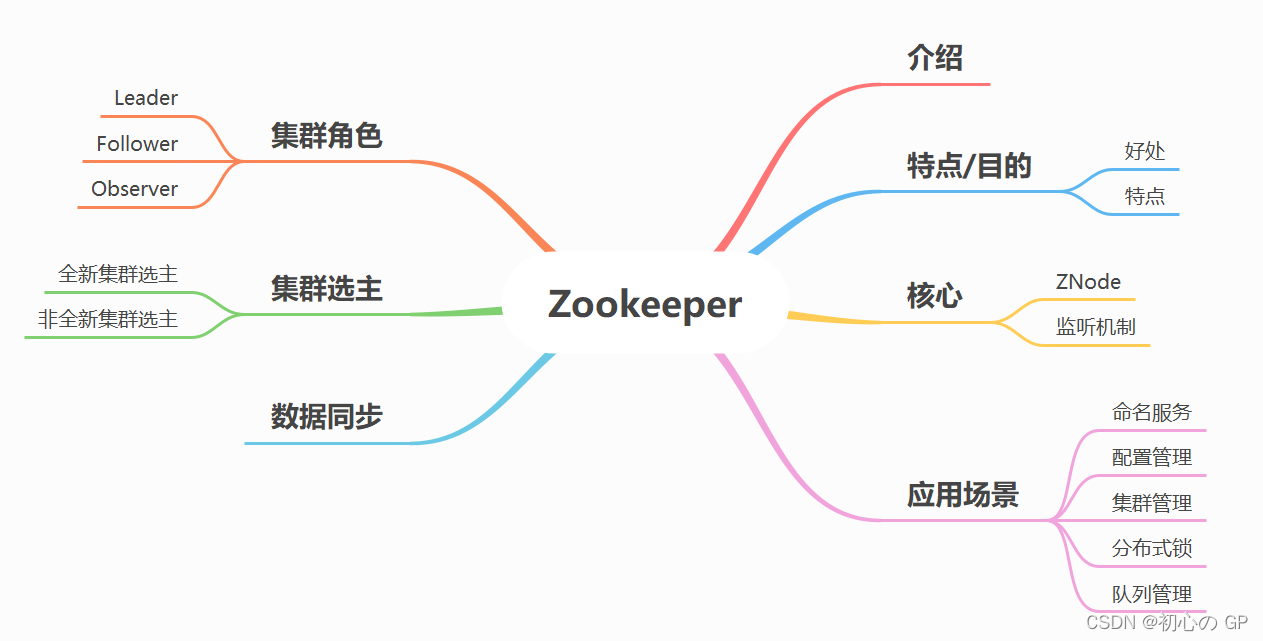 Zookeeper介绍_初心の GP的博客-优快云博客https://blog.youkuaiyun.com/a318199328/article/details/121973475
Zookeeper介绍_初心の GP的博客-优快云博客https://blog.youkuaiyun.com/a318199328/article/details/121973475

















 2857
2857

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









