






巧用影刀 RPA 魔法指令:将文件夹中的发票文本转为 Excel 数据表格
**
摘要
本文介绍利用影刀 RPA 魔法指令,以自然语言交互方式,将发票文本转为 Excel 数据表格的方法,帮助财务及数据处理人员高效完成任务,提升数据处理效率与准确性。
目录
一、问题引入
企业处理发票数据时,手动将杂乱的发票文本录入 Excel 表格效率低、易出错。影刀 RPA 魔法指令可提供高效解决方案,快速将发票文本转为规整的 Excel 数据表格。
二、影刀 RPA 魔法指令简介
影刀 RPA 魔法指令基于自然语言处理技术,无需编程,用日常语言描述需求就能生成自动化指令。其核心功能包括:
- 文本处理:精准提取发票关键信息,如发票号码、日期、金额等,还能完成文本替换、格式化。
- Excel 操作:支持数据读写、筛选、排序、汇总等,能合并多个 Excel 表格。
- 数据转换整合:将不同格式发票数据转为 Excel 并清洗合并。
- 智能修复:自动检测修复指令错误,也可通过对话反馈优化指令。
三、实践操作
3.1 前期准备
- 把发票文本文件整理到同一文件夹(文件命名需要根据自己实际需要来定义),记好路径。
3.2 创建魔法指令
打开影刀 RPA 软件,新建 PC 应用,点击 “魔法指令” 按钮,在对话框输入需求,如 “处理 [发票文本文件夹路径] 内文件,提取文件名、相对路径、完整路径、发票号码、结算单号、结算金额、品牌、店铺区别,输出 [ Excel 文件名]” 。不确定时用 “优化提问” 完善需求。
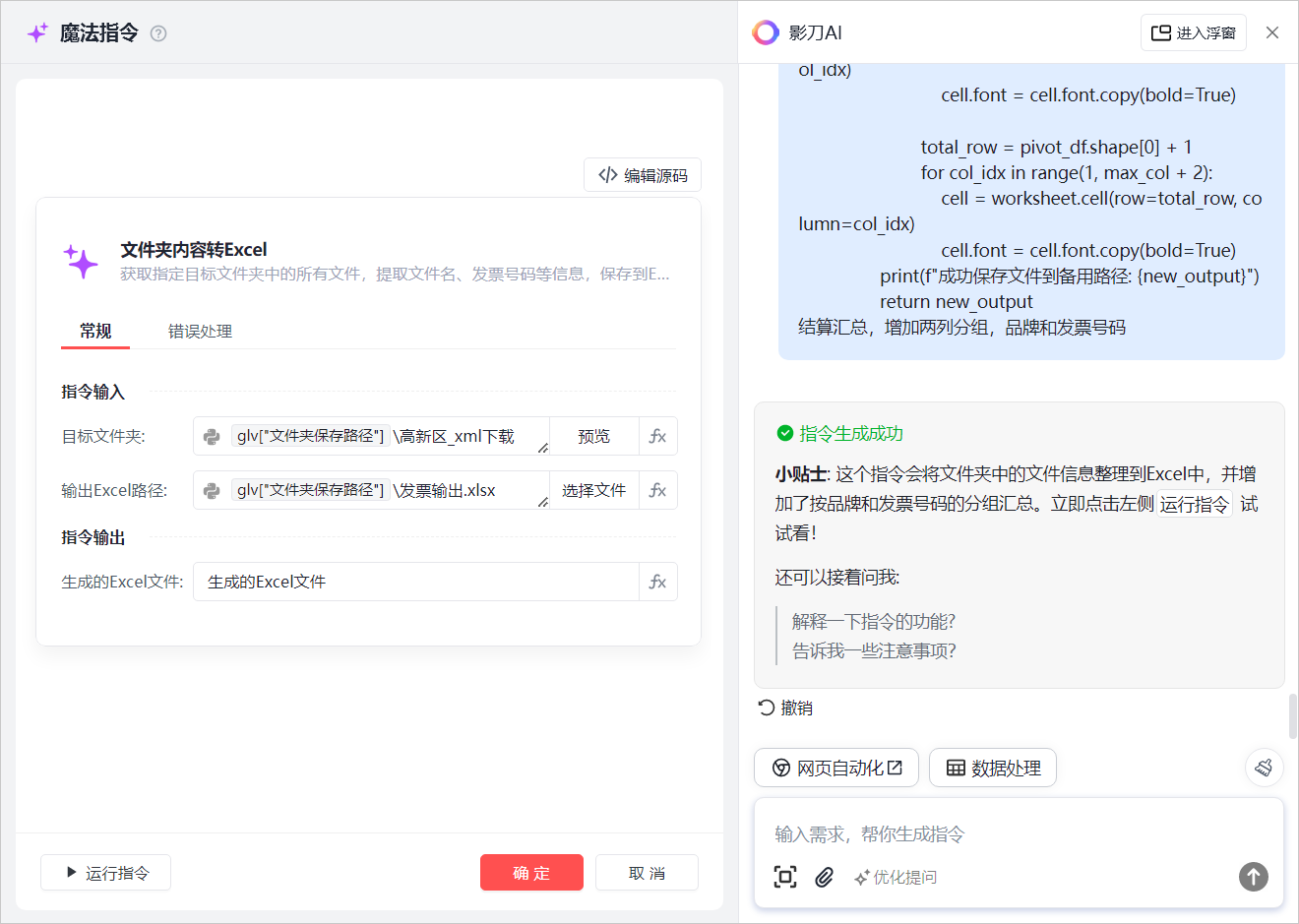
3.3 测试指令
点击 “运行指令”,影刀 AI 模拟运行,查看指令状态和数据结果。
3.4 运行结果及代码
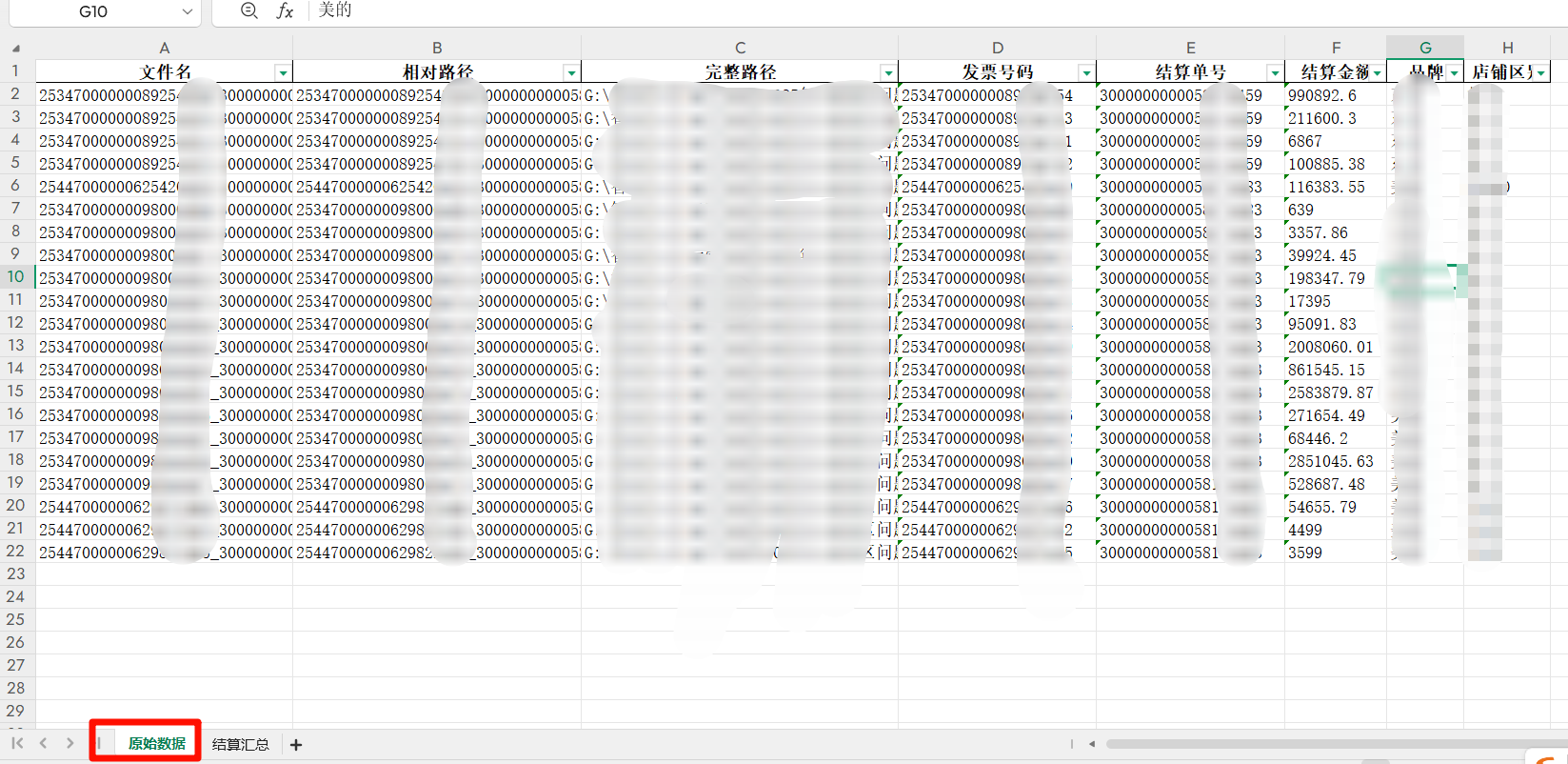
第一部分输出结果为:文件的基本信息和开票金额
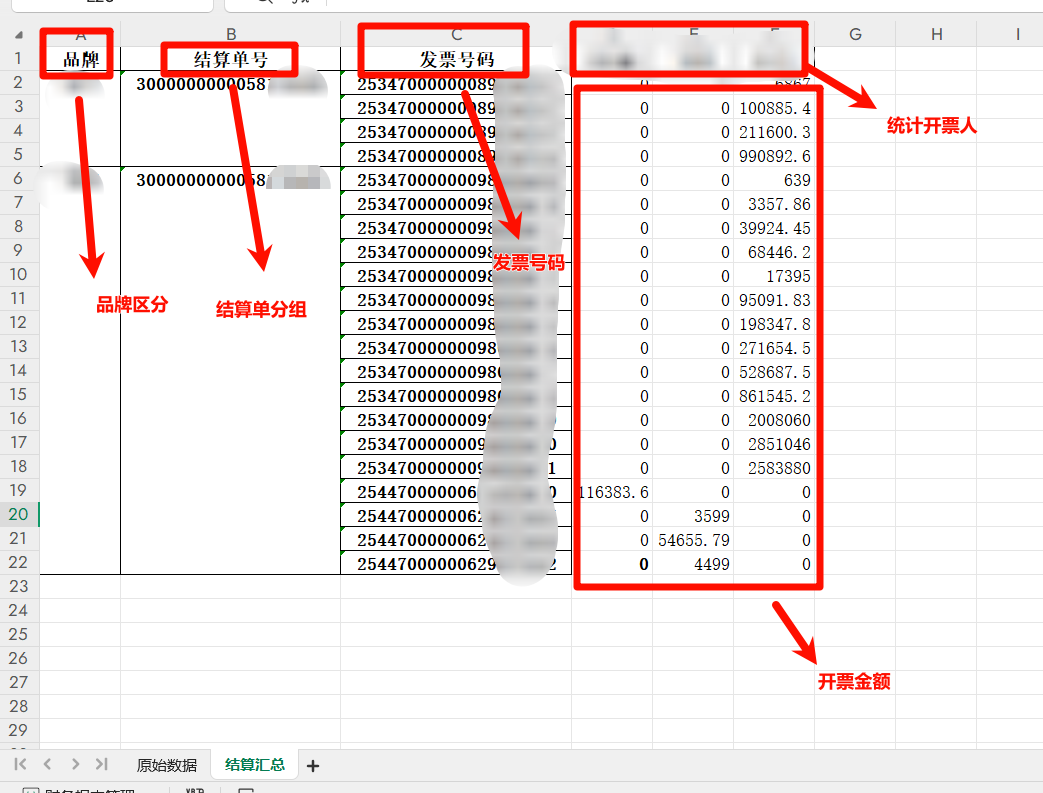
第二部分输出结果为:对发票号码进行统计展示
代码展示
import os
import pandas as pd
import time
from typing import *
try:
from xbot.app.logging import trace as print
except:
pass
try:
from xbot.app.logging import trace as print
except:
from xbot import print
def folder_to_excel(folder_path, output_excel):
"""
title: 文件夹内容转Excel
description: 获取指定%folder_path%中的所有文件,提取文件名、发票号码等信息,保存到Excel的两个Sheet中。
inputs:
- folder_path (folder): 目标文件夹,eg: "D:/Documents"
- output_excel (file): 输出Excel路径,eg: "D:/files_list.xlsx"
outputs:
- output_excel (file): 生成的Excel文件,eg: "D:/files_list.xlsx"
"""
# 检查输入文件夹是否存在
if not os.path.exists(folder_path):
raise ValueError(f"文件夹 '{folder_path}' 不存在")
# 存储文件信息的列表
files_info = []
# 定义辅助函数处理文件名
def _process_filename(filename):
base_name = os.path.splitext(filename)[0]
parts = base_name.split("_")
# 提取发票号码、结算单号、结算金额等
invoice_number = parts[0] if len(parts) >= 1 else None
settlement_number = parts[1] if len(parts) >= 2 else None
settlement_amount = parts[2] if len(parts) >= 3 else None
brand = parts[3] if len(parts) >= 4 else None
store = parts[4] if len(parts) >= 5 else None
return invoice_number, settlement_number, settlement_amount, brand, store
# 遍历文件夹中的所有文件
for root, _, files in os.walk(folder_path):
for file in files:
# 获取完整路径
full_path = os.path.join(root, file)
# 获取相对路径
relative_path = os.path.relpath(root, folder_path)
if relative_path == '.':
relative_path = ''
relative_path = os.path.join(relative_path, file)
# 处理文件名获取基本信息
invoice_number, settlement_number, settlement_amount, brand, store = _process_filename(file)
# 添加到列表
files_info.append({
'文件名': file,
'相对路径': relative_path,
'完整路径': full_path,
'发票号码': invoice_number,
'结算单号': settlement_number,
'结算金额': settlement_amount,
'品牌': brand,
'店铺区别': store
})
# 创建DataFrame
df = pd.DataFrame(files_info)
# 确保输出目录存在
output_dir = os.path.dirname(output_excel)
if output_dir and not os.path.exists(output_dir):
os.makedirs(output_dir)
# 尝试保存Excel文件,如果失败则使用备用方案
max_attempts = 3
for attempt in range(max_attempts):
try:
# 创建ExcelWriter对象
with pd.ExcelWriter(output_excel, engine='openpyxl') as writer:
# 写入第一个Sheet:原始数据
df.to_excel(writer, sheet_name='原始数据', index=False)
# 处理第二个Sheet:按店铺和结算单号分组汇总
# 确保结算金额是数值类型
df['结算金额'] = pd.to_numeric(df['结算金额'], errors='coerce')
# 检查是否存在店铺区别列且有有效数据
if '店铺区别' in df.columns and not df['店铺区别'].isna().all():
# 按店铺区别和结算单号分组,对结算金额求和
summary_df = df.groupby(['店铺区别', '结算单号','发票号码','品牌'])['结算金额'].sum().reset_index()
# 透视表格,将店铺区别作为列,结算单号作为行
pivot_df = summary_df.pivot(index=['品牌','结算单号','发票号码'], columns='店铺区别', values='结算金额').fillna(0)
# 添加总计行
# pivot_df.loc['总计'] = pivot_df.sum()
# 写入第二个Sheet
pivot_df.to_excel(writer, sheet_name='结算汇总')
# 获取工作表和最大列索引
worksheet = writer.sheets['结算汇总']
max_col = pivot_df.shape[1]
# 设置表头样式(粗体)
for col_idx in range(1, max_col + 2): # +2 是因为Excel列从1开始,且包含索引列
cell = worksheet.cell(row=1, column=col_idx)
cell.font = cell.font.copy(bold=True)
# 设置总计行样式(粗体)
total_row = pivot_df.shape[0] + 1 # +1 是因为Excel行从1开始
for col_idx in range(1, max_col + 2):
cell = worksheet.cell(row=total_row, column=col_idx)
cell.font = cell.font.copy(bold=True)
print(f"成功保存文件到: {output_excel}")
return output_excel
except PermissionError:
if attempt < max_attempts - 1:
# 如果文件可能被占用,等待一会再试
print(f"文件可能被占用,等待后重试... (尝试 {attempt+1}/{max_attempts})")
time.sleep(2)
else:
# 如果依然失败,尝试使用不同的文件名
file_name, ext = os.path.splitext(output_excel)
new_output = f"{file_name}_{int(time.time())}{ext}"
print(f"无法写入到 {output_excel},尝试保存到 {new_output}")
with pd.ExcelWriter(new_output, engine='openpyxl') as writer:
df.to_excel(writer, sheet_name='原始数据', index=False)
df['结算金额'] = pd.to_numeric(df['结算金额'], errors='coerce')
if '店铺区别' in df.columns and not df['店铺区别'].isna().all():
summary_df = df.groupby(['店铺区别', '结算单号',"品牌","发票号码"])['结算金额'].sum().reset_index()
pivot_df = summary_df.pivot(index=["品牌",'结算单号',"发票号码"], columns='店铺区别', values='结算金额').fillna(0)
# pivot_df.loc['总计'] = pivot_df.sum()
pivot_df.to_excel(writer, sheet_name='结算汇总')
worksheet = writer.sheets['结算汇总']
max_col = pivot_df.shape[1]
for col_idx in range(1, max_col + 2):
cell = worksheet.cell(row=1, column=col_idx)
cell.font = cell.font.copy(bold=True)
total_row = pivot_df.shape[0] + 1
for col_idx in range(1, max_col + 2):
cell = worksheet.cell(row=total_row, column=col_idx)
cell.font = cell.font.copy(bold=True)
print(f"成功保存文件到备用路径: {new_output}")
return new_output
3.5 修改指令
- 智能修复:指令出错或结果不符,点击 “智能修复” 自动优化。
- 对话修改:自动修复无效时,对话框补充需求,如修正日期格式。
- 撤销操作:修改失误可点击 “撤销” 恢复上一版本。
- 源码修改:有编程基础者可编辑源码或粘贴 Python 代码定制指令。
3.6 稳定运行
反复测试修改无误后,魔法指令可稳定运行,在指定路径获取生成的 Excel 文件。
四、问题解决与避坑指南
- 指令生成不准:检查需求描述,补充发票文本格式等信息,参考示例库优化提问。
- 智能修复不佳:分析错误提示,用对话修改明确问题和修改方向,复杂问题借助源码修改并重新测试。
- 数据提取问题:发票格式不一时,针对不同格式编写提取规则,生成表格后抽查校验数据。
五、总结
本文介绍了用影刀 RPA 魔法指令转换发票文本为 Excel 表格的方法,操作简便,大幅提升效率、降低错误率。实际应用中可按需灵活调整指令,优化数据处理流程。

















 817
817

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









