



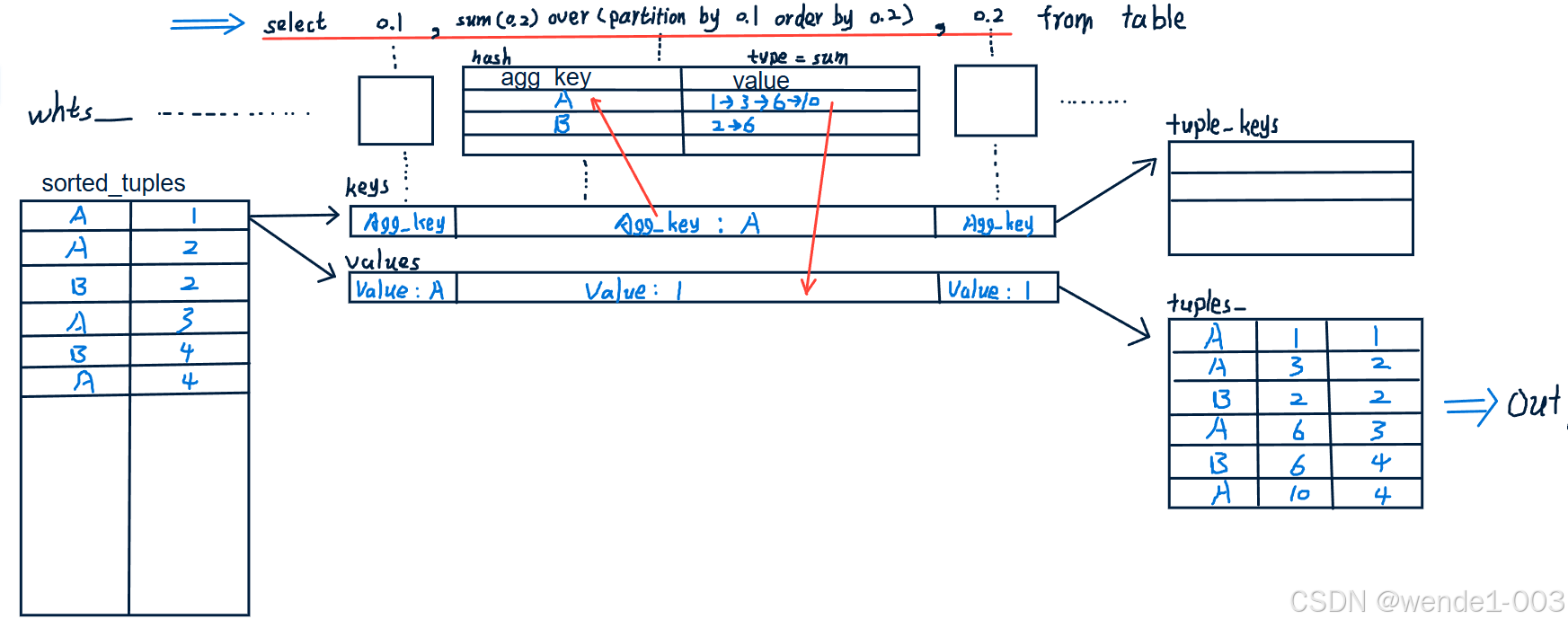
!!!与普通哈希聚合最大的不同是,窗口函数遍历每个元组产生每属性列的哈希表时,同时根据每次遍历的聚合结果,产生结果元组——》实现每个元组都能输出聚合值
内核代码实现逻辑图(原创):
Window Functions 窗口函数
In general, window functions have three parts: partition by, order by, and window frames. All three are optional, so multiple combinations of these features make the window function daunting at first. However, the conceptual model for a window function helps make it easier to understand. The conceptual model is the following: * Split the data based on the conditions in the partition by clause. * Then, in each partition, sort by the order by clause. * Then, in each partition (now sorted), iterate over each tuple. For each tuple, we compute the boundary condition for the frame for that tuple. Each frame has a start and end (specified by the window frame clause). The window function is computed on the tuples in each frame, and we output what we have computed in each frame.
通常,窗口函数有三个部分:partition by、order by 和 window frames。这三个都是可选的,因此这些功能的多种组合使窗口功能起初令人生畏。但是,窗函数的概念模型有助于使其更易于理解。概念模型如下:* 根据 partition by 子句中的条件拆分数据。* 然后,在每个分区中,按 order by 子句排序。* 然后,在每个分区(现在已排序)中,迭代每个元组。对于每个元组,我们计算该元组的帧的边界条件。每个帧都有一个 start 和 end (由 window frame 子句指定)。窗口函数是在每个帧的元组上计算的,我们输出我们在每个帧中计算的内容。
The diagram below shows the general execution model of the window function.
下图显示了窗口函数的一般执行模型。

Let's dive deeper with a few examples using the following table:
让我们使用下表通过几个示例进行更深入的研究:
<span style="background-color:#e6e7e8 !important"><span style="color:#0d0d0d">CREATE TABLE t (user_name VARCHAR(1), dept_name VARCHAR(16), salary INT);
INSERT INTO t VALUES ('a', 'dept1', 100);
INSERT INTO t VALUES ('b', 'dept1', 200);
INSERT INTO t VALUES ('c', 'dept1', 300);
INSERT INTO t VALUES ('e', 'dept2', 100);
INSERT INTO t VALUES ('d', 'dept2', 50);
INSERT INTO t VALUES ('f', 'dept2', 60);
</span></span>Example #1 The below example calculates a moving average of the salary for each department. You can consider it as first sort the rows for each partition by name and then calculate the average of the row before the current row, current row and the row after current row.
示例 #1 下面的示例计算每个部门的薪金的移动平均值。您可以将其视为首先按名称对每个分区的行进行排序,然后计算当前行、当前行和当前行之后的行的平均值。
<span style="background-color:#e6e7e8 !important"><span style="color:#0d0d0d">bustub> SELECT user_name, dept_name, AVG(salary) OVER \
(PARTITION BY dept_name ORDER BY user_name ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) \
FROM t;
+-----------+-----------+-----------------------------+
| user_name | dept_name | salary |
+-----------+-----------+-----------------------------+
| a | dept1 | 150 |
| b | dept1 | 200 |
| c | dept1 | 250 |
| d | dept2 | 75 |
| e | dept2 | 70 |
| f | dept2 | 80 |
+-----------+-----------+-----------------------------+
</span></span>Example #2 The query below calculates a moving average of the salary for each department. Different from previous example, when window frames are omitted and order by clauses not omitted, it calculates from the first row to the current row for each partition.
示例 #2 下面的查询计算每个部门的薪金的移动平均值。与前面的示例不同,当省略窗口框架且未省略 order by 子句时,它会从每个分区的第一行计算到当前行。
<span style="background-color:#e6e7e8 !important"><span style="color:#0d0d0d">bustub> SELECT user_name, dept_name, AVG(salary) OVER (PARTITION BY dept_name ORDER BY user_name) FROM t;
+-----------+-----------+-----------------------------+
| user_name | dept_name | salary |
+-----------+-----------+-----------------------------+
| a | dept1 | 100 |
| b | dept1 | 150 |
| c | dept1 | 200 |
| d | dept2 | 50 |
| e | dept2 | 75 |
| f | dept2 | 70 |
+-----------+-----------+-----------------------------+
</span></span>Example #3 This query show that when order by and window frames are both omitted, it calculates from the first row to the last row for each partition, which means the results within the partition should be the same.
示例 #3 此查询显示,当 order by 和 window frames 都省略时,它会从每个分区的第一行到最后一行进行计算,这意味着分区内的结果应该相同。
<span style="background-color:#e6e7e8 !important"><span style="color:#0d0d0d">bustub> SELECT user_name, dept_name,AVG(salary) OVER (PARTITION BY dept_name) FROM t;
+-----------+-----------+-----------------------------+
| user_name | dept_name | salary |
+-----------+-----------+-----------------------------+
| a | dept1 | 200 |
| b | dept1 | 200 |
| c | dept1 | 200 |
| e | dept2 | 70 |
| d | dept2 | 70 |
| f | dept2 | 70 |
+-----------+-----------+-----------------------------+
</span></span><span style="background-color:#e6e7e8 !important"><span style="color:#0d0d0d">bustub> SELECT user_name, dept_name, AVG(salary) OVER () FROM t;
+-----------+-----------+-----------------------------+
| user_name | dept_name | salary |
+-----------+-----------+-----------------------------+
| a | dept1 | 135 |
| b | dept1 | 135 |
| c | dept1 | 135 |
| e | dept2 | 135 |
| d | dept2 | 135 |
| f | dept2 | 135 |
+-----------+-----------+-----------------------------+
</span></span>For this task, you do not need to handle window frames. As in the above examples, you only need to implement PARTITION BY and ORDER BY clauses. You may notice that the ORDER BY clauses also change the order of non-window function columns. This is not necessary as the output order is not guaranteed and depends on the implementation. For simplicity, BusTub ensures that all window functions within a query have the same ORDER BY clauses. This means the following queries are not supported in BusTub and your implementation does not need to handle them:
对于此任务,您无需处理窗口框架。如上面的示例所示,您只需实现 PARTITION BY 和 ORDER BY 子句。您可能会注意到,ORDER BY 子句还会更改非窗口函数列的顺序。这不是必需的,因为 output order 无法保证并且取决于 implementation 。为简单起见,BusTub 确保查询中的所有窗口函数都具有相同的 ORDER BY 子句。这意味着 BusTub 不支持以下查询,您的实现不需要处理它们:
<span style="background-color:#e6e7e8 !important"><span style="color:#0d0d0d">SELECT SUM(v1) OVER (ORDER BY v1), SUM(v1) OVER (ORDER BY v2) FROM t1;
SELECT SUM(v1) OVER (ORDER BY v1), SUM(v2) OVER () FROM t1;
</span></span>The test case will not check the order of output rows as long as columns within each row are matched. Therefore, you can sort the tuples first before doing the calculations when there are ORDER BY clauses, and do not change the order of tuples coming from the child executor when there are no order by clauses.
只要每行中的列匹配,测试用例就不会检查输出行的顺序。因此,当有 ORDER BY 子句时,您可以在进行计算之前先对 Tuples 进行排序,并且当没有 order BY 子句时,不要更改来自子执行程序的 Tuples 的顺序。
You can implement the executor in the following steps:
您可以通过以下步骤实现 executor:
- Sort the tuples as indicated in
ORDER BY.
按照ORDER BY中的指示对 Tuples 进行排序。 - Generate the initial value for each partition
为每个分区生成初始值 - Combine values for each partition and record the value for each row.
合并每个分区的值并记录每行的值。
You may reuse the code from sort executors to complete step 1 and the code from aggregation executor to complete step 2 and step 3.
您可以重复使用排序执行程序中的代码来完成步骤 1,重复使用聚合执行程序中的代码来完成步骤 2 和步骤 3。
Apart from aggregation functions implemented in previous tasks, you will need to implement RANK as well. The BusTub planner ensures that ORDER BY clause is not empty if RANK window function is present. Be aware that there might be ties and please refer to test cases for the expected behavior.
除了在前面的任务中实现的聚合函数外,您还需要实现 RANK。BusTub 计划程序确保如果存在 RANK 窗口函数,则 ORDER BY 子句不为空。请注意,可能存在关联,请参阅测试用例以了解预期行为。
引用资料:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









