






首先创建scrapy
准备工作
pipev install scrapy
scrapy startproject ZhihuLove
cd进入项目的spider目录
scrapy genspider ZhihuLove 'www.zhihu.com'
然后用 vscode 或者 pycharm打开项目
创建完成后会自动创建好项目
接下来可以开心的写需要的数据了
爬数据主要是处理网站的节点
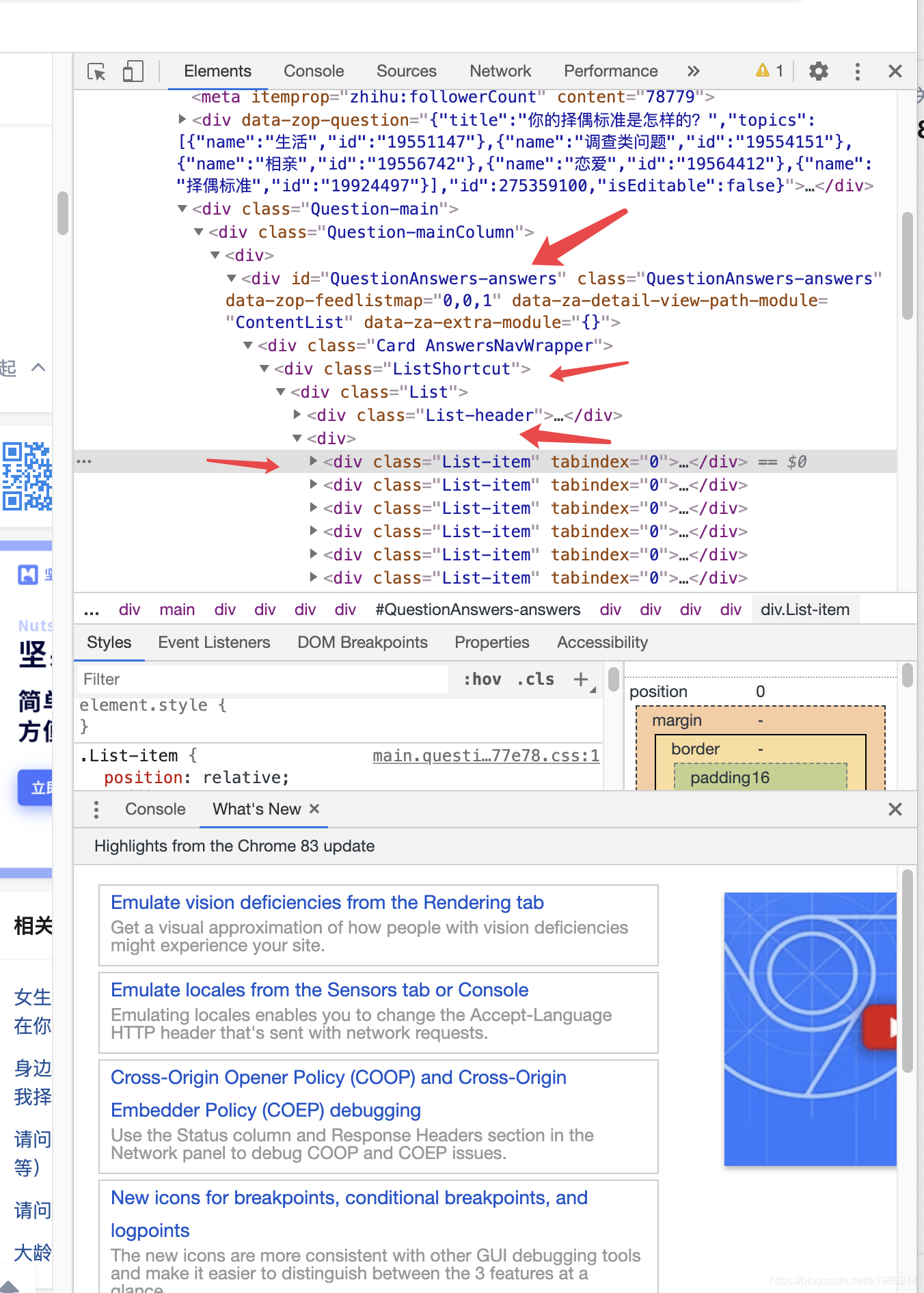
首先找到大节点 question = response.xpath('//div[@class="Question-main"]') 因为是一个div层结构
然后列表为 infos = question.xpath('./div//div[@class="List-item"]') 列表的节点为List-item结构
要获取对应的字段继续去找相对应地子节点即可
然后再把数据存储到对应的数据库中
注意:需要引入伪装代码:
# -*- coding: utf-8 -*-
# Scrapy settings for ZhihuLove project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'ZhihuLove'
SPIDER_MODULES = ['ZhihuLove.spiders']
NEWSPIDER_MODULE = 'ZhihuLove.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'ZhihuLove (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# 配置默认的请求头
DEFAULT_REQUEST_HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:61.0) Gecko/20100101 Firefox/61.0",
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8'
}
# 配置使用Pipeline
ITEM_PIPELINES = {
'ZhihuLove.pipelines.ZhihulovePipeline': 300,
}项目链接在 https://github.com/ArdWang/ZhihuLove 喜欢就点个star吧


















 4403
4403

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











