






许苑园 一一 寻找共同兴趣的伙伴项目笔记
需求分析
-
用户去添加标签,标签的分类(要有哪些标签、怎么把标签进行分类)学习方向 java / c++,工作 / 大学
-
主动搜索:允许用户根据标签去搜索其他用户
-
- Redis 缓存
-
组队
-
- 创建队伍
- 加入队伍
- 根据标签查询队伍
- 队伍聊天
-
允许用户去修改标签
-
允许个人与个人进行聊天
-
公共聊天室
- Websocket会话技术
-
chagpt问答
-
博文发布
-
心动匹配
- 相似度计算算法 + 本地分布式计算
技术栈
前端
- Vue 3 开发框架(提高页面开发的效率)
- Vant UI(基于 Vue 的移动端组件库)(React 版 Zent)
- Vite 2(打包工具,快!)
- Nginx 来单机部署
后端
- Java 编程语言 + SpringBoot 框架
- SpringMVC + MyBatis + MyBatis Plus(提高开发效率)
- MySQL 数据库
- Redis 缓存
- Websocket会话技术
- Chatgpt问答技术
- Swagger + Knife4j 接口文档
数据库表设计
标签的分类(要有哪些标签、怎么把标签进行分类)
新增标签表(分类表)
建议用标签,不要用分类,更灵活。
性别:男、女
方向:Java、C++、Go、前端
正在学:Spring
目标:考研、春招、秋招、社招、考公、竞赛(蓝桥杯)、转行、跳槽
段位:初级、中级、高级、王者
身份:小学、初中、高中、大一、大二、大三、大四、学生、待业、已就业、研一、研二、研三
状态:乐观、有点丧、一般、单身、已婚、有对象
字段:
id int 主键
标签名 varchar 非空(必须唯一,唯一索引)
上传标签的用户 userId int(如果要根据 userId 查已上传标签的话,最好加上,普通索引)
父标签 id ,parentId,int(分类)
是否为父标签 isParent, tinyint(0 不是父标签、1 - 父标签)
创建时间 createTime,datetime
更新时间 updateTime,datetime
是否删除 isDelete, tinyint(0、1)
怎么查询所有标签,并且把标签分好组?按父标签 id 分组,能实现 √
根据父标签查询子标签?根据 id 查询,能实现 √
SQL 语言分类:
DDL define 建表、操作表
DML manage 更新删除数据,影响实际表里的内容
DCL control 控制,权限
DQL query 查询,select
修改用户表
用户有哪些标签?
根据自己的实际需求来!!! 此处选择第一种
- 直接在用户表补充 tags 字段,[‘Java’, ‘男’] 存 json 字符串 优点:查询方便、不用新建关联表,标签是用户的固有属性(除了该系统、其他系统可能要用到,标签是用户的固有属性)节省开发成本**查询用户列表,查关系表拿到这 100 个用户有的所有标签 id,再根据标签 id 去查标签表。**哪怕性能低,可以用缓存。缺点:用户表多一列,会有点
- 加一个关联表,记录用户和标签的关系关联表的应用场景:查询灵活,可以正查反查缺点:要多建一个表、多维护一个表重点:企业大项目开发中尽量减少关联查询,很影响扩展性,而且会影响查询性能.
开发后端接口时间
搜索标签
\1. 允许用户传入多个标签,多个标签都存在才搜索出来 and。like ‘%Java%’ and like ‘%C++%’。
\2. 允许用户传入多个标签,有任何一个标签存在就能搜索出来 or。like ‘%Java%’ or like ‘%C++%’
两种方式:
\1. SQL 查询(实现简单,可以通过拆分查询进一步优化)
\2. 内存查询(灵活,可以通过并发进一步优化)
- 如果参数可以分析,根据用户的参数去选择查询方式,比如标签数
- 如果参数不可分析,并且数据库连接足够、内存空间足够,可以并发同时查询,谁先返回用谁。
- 还可以 SQL 查询与内存计算相结合,比如先用 SQL 过滤掉部分 tag
建议通过实际测试来分析哪种查询比较快,数据量大的时候验证效果更明显!
解析 JSON 字符串:
序列化:java对象转成 json
反序列化:把 json 转为 java 对象
java json 序列化库有很多:
\1. gson(google 的)
\2. fastjson alibaba(ali 出品,快,但是漏洞太多)
\3. jackson
\4. kryo
Swagger和Knife4j的区别和联系
Swagger
Swagger 是一个非常流行的 API 开发框架,它包括了一系列工具和服务,旨在帮助开发者设计、构建、文档化和使用 RESTful API。Swagger 提供了一个规范(OpenAPI Specification,OAS)来定义 RESTful API,使得开发者可以通过 YAML 或 JSON 文件来描述他们的 API,从而自动生成文档。Swagger 生态系统包含了许多工具,如 Swagger UI(用于展示 API 文档)、Swagger Codegen(用于生成客户端 SDK、服务器 stubs 和 API 文档)等。
特点:
- 广泛支持:Swagger 支持多种语言和技术栈。
- 标准化:遵循 OpenAPI 规范。
- 丰富的生态系统:有许多工具可以集成,比如编辑器插件、IDE 插件等。
Knife4j
Knife4j 是一个基于 Swagger2 的增强版解决方案,专门为使用 Spring Boot 和 Spring Cloud 的项目而设计。它提供了比原生 Swagger 更多的功能和更友好的界面体验。Knife4j 在国内开发者社区中有较好的口碑,特别是在中文社区中,因为它提供了很好的本地化支持,并且有一些针对国内开发者习惯的优化。
特点:
- 针对 Spring Boot/Spring Cloud:更加贴近 Spring 生态系统。
- 中文友好:对于中文开发者来说有更好的文档和支持。
- 额外功能:例如 API 分组、自定义页面样式等。
- 增强的 UI:提供了更加美观和易用的 UI 界面。
区别
- 适用范围:
- Swagger 可以应用于任何遵循 OpenAPI 规范的项目。
- Knife4j 主要面向的是使用 Spring Boot 和 Spring Cloud 的 Java 开发者。
- 社区支持:
- Swagger 有着广泛的国际社区支持。
- Knife4j 在国内有着更好的支持,特别是中文社区。
- 功能特性:
- Swagger 提供基本的 API 文档生成功能。
- Knife4j 在此基础上增加了一些实用的特性,比如 API 分组、自定义 UI 等。
Knife4j使用
- 引入配置依赖
<dependency>
<groupId>com.github.xiaoymin</groupId>
<artifactId>knife4j-openapi2-spring-boot-starter</artifactId>
<version>4.4.0</version>
</dependency>
- 配置文件配置
knife4j:
enable: true
openapi:
title: Knife4j官方文档
description: 我是许苑向上
# aaa"
email: 2517115657@qq.com
concat: 一心向上
url: https://docs.xiaominfo.com
version: v4.0
license: Apache 2.0
license-url: https://stackoverflow.com/
terms-of-service-url: https://stackoverflow.com/
group:
test1:
group-name: 分组名称
api-rule: package
api-rule-resources:
- xu.yuan.controller
- 注解信息的标注

分布式 session
种 session 的时候注意范围,cookie.domain
比如两个域名:
aaa.yupi.com
bbb.yupi.com
如果要共享 cookie,可以种一个更高层的公共域名,比如 yupi.com
为什么服务器 A 登录后,请求发到服务器 B,不认识该用户?
用户在 A 登录,所以 session(用户登录信息)存在了 A 上
结果请求 B 时,B 没有用户信息,所以不认识。
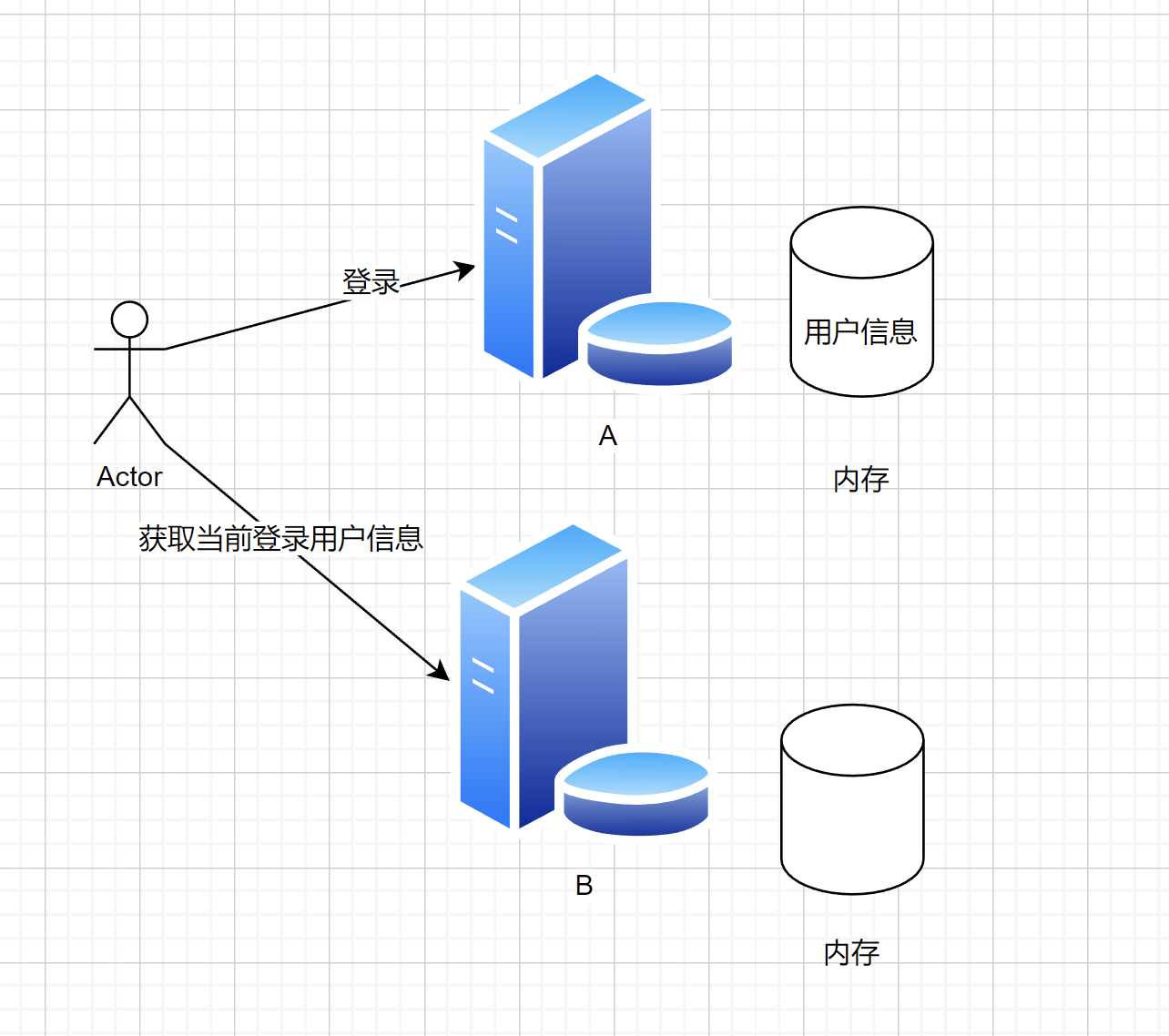
解决方案:共享存储 ,而不是把数据放到单台服务器的内存中
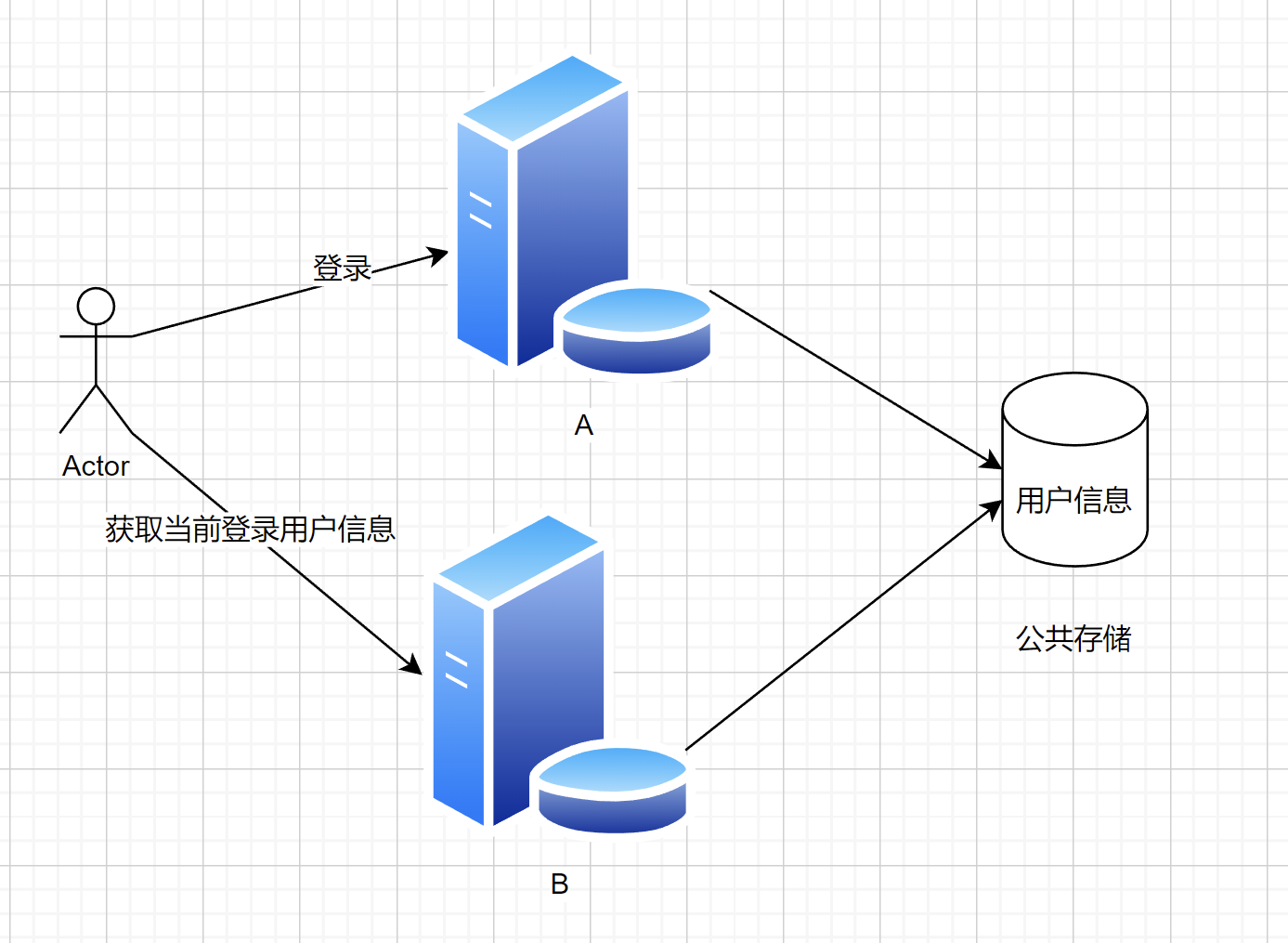
Session 共享实现Redis
如何共享存储?
- Redis(基于内存的 K / V 数据库)此处选择 Redis,因为用户信息读取 / 是否登录的判断极其频繁 ,Redis 基于内存,读写性能很高,简单的数据单机 qps 5w - 10w
- MySQL
- 文件服务器 ceph
官网:https://redis.io/
windows 下载:
Redis 5.0.14 下载:
链接:https://pan.baidu.com/s/1XcsAIrdeesQAyQU2lE3cOg
提取码:vkoi
redis 管理工具 quick redis:https://quick123.net/
- 引入 redis,能够操作 redis:
<!-- redis -->
<!-- https://mvnrepository.com/artifact/org.springframework.boot/spring-boot-starter-data-redis -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<version>2.6.4</version>
</dependency>
- 引入 spring-session 和 redis 的整合,使得自动将 session 存储到 redis 中:
spring-session-data-redis依赖用于将 HTTP 会话(HttpSession)数据存储到 Redis 中
其中request.getSession().setAttribute(LOGIN_USER_KEY, safetyUser);虽然存放的都是同一个键,但是其实redis真正存放数据的结构是,键是会话ID,值是Httpsession对象,其中Httpsession中有个Map用来存放数据,键是LOGIN_USER_KEY,值是存放的对象。

<!-- session-data-redis -->
<!-- https://mvnrepository.com/artifact/org.springframework.session/spring-session-data-redis -->
<dependency>
<groupId>org.springframework.session</groupId>
<artifactId>spring-session-data-redis</artifactId>
<version>2.6.3</version>
</dependency>
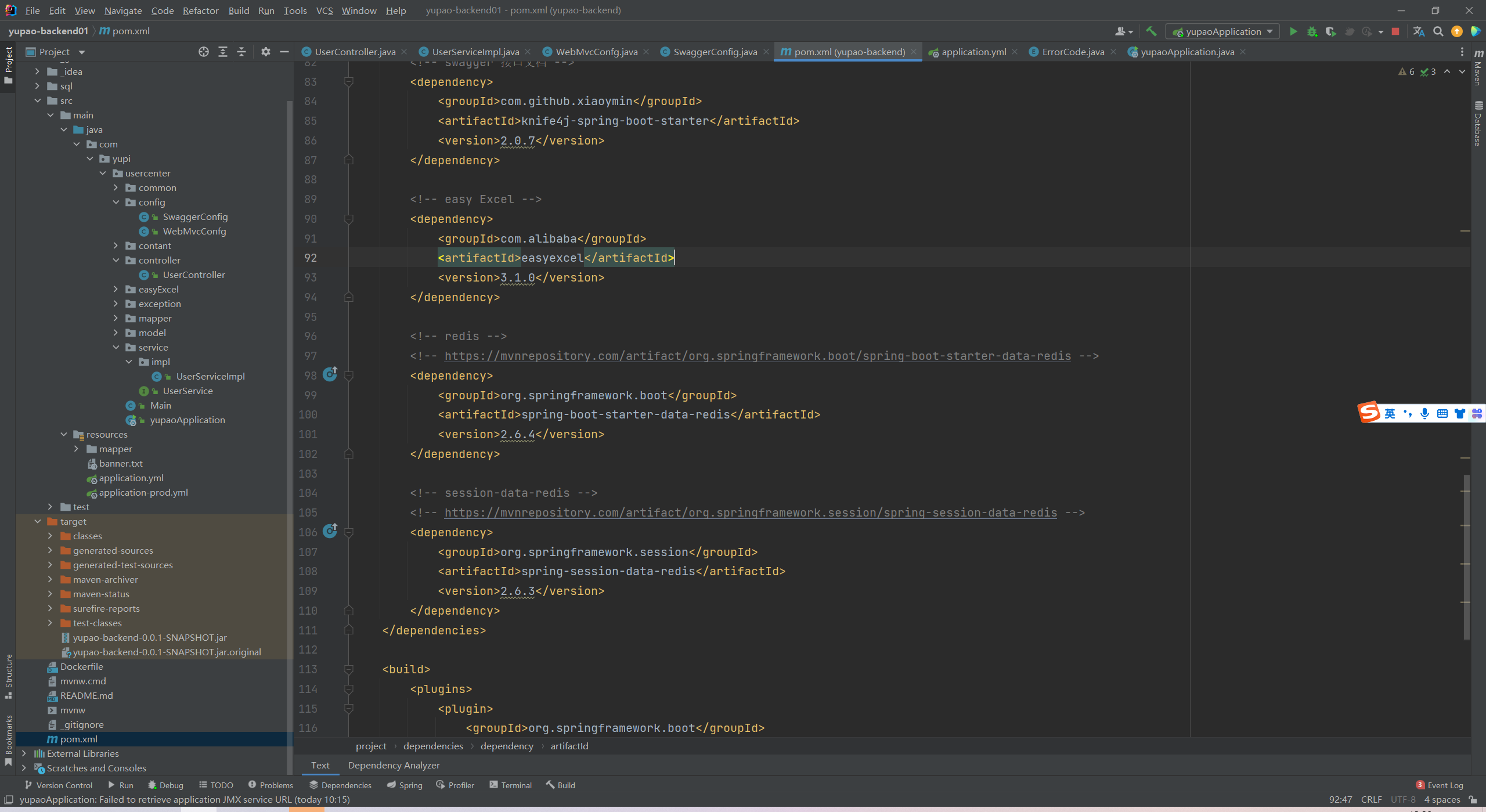
- 修改 spring-session 存储配置 spring.session.store-type
默认是 none,表示存储在单台服务器
store-type: redis,表示从 redis 读写 session

打包并分开运行。
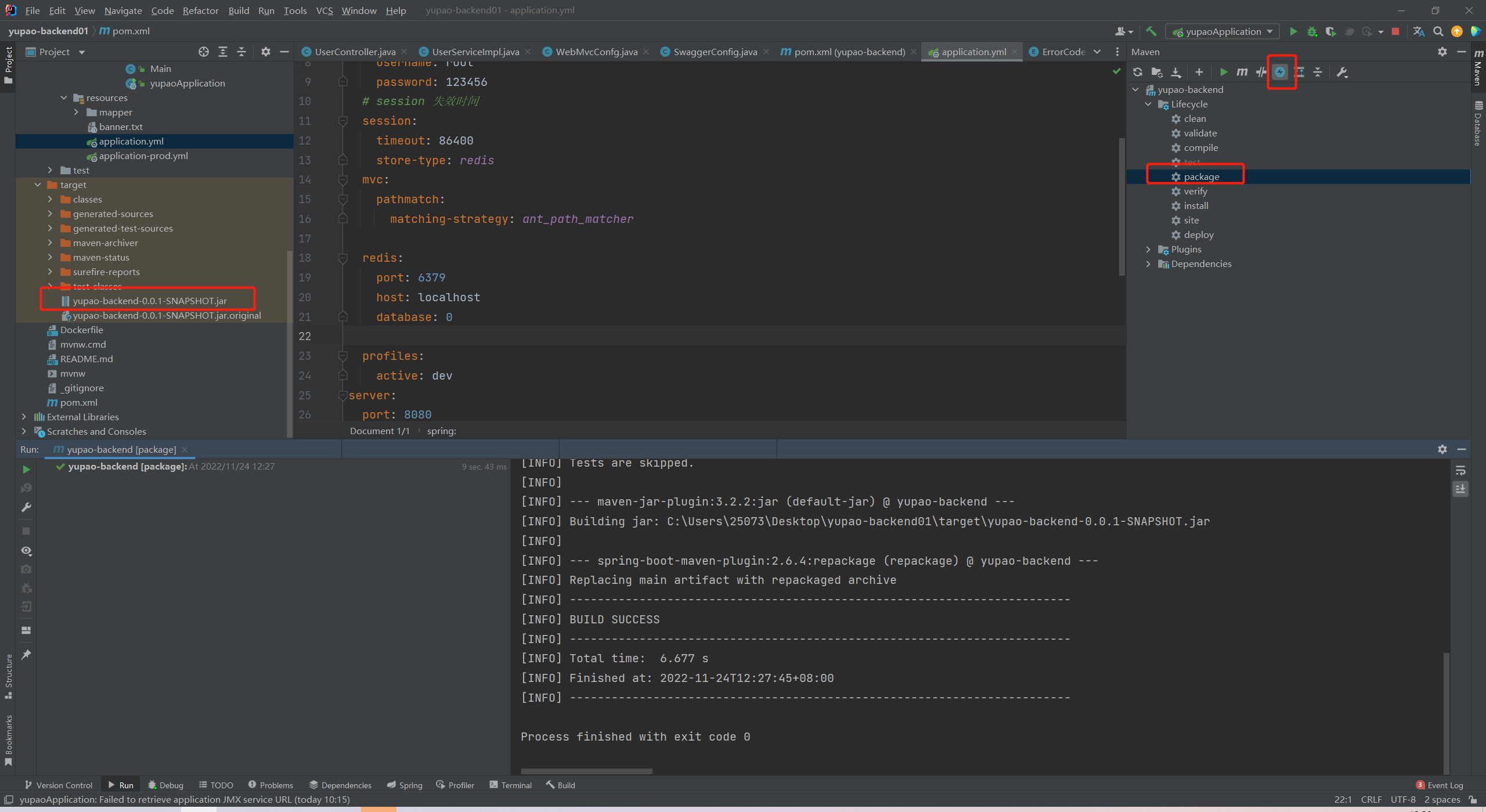
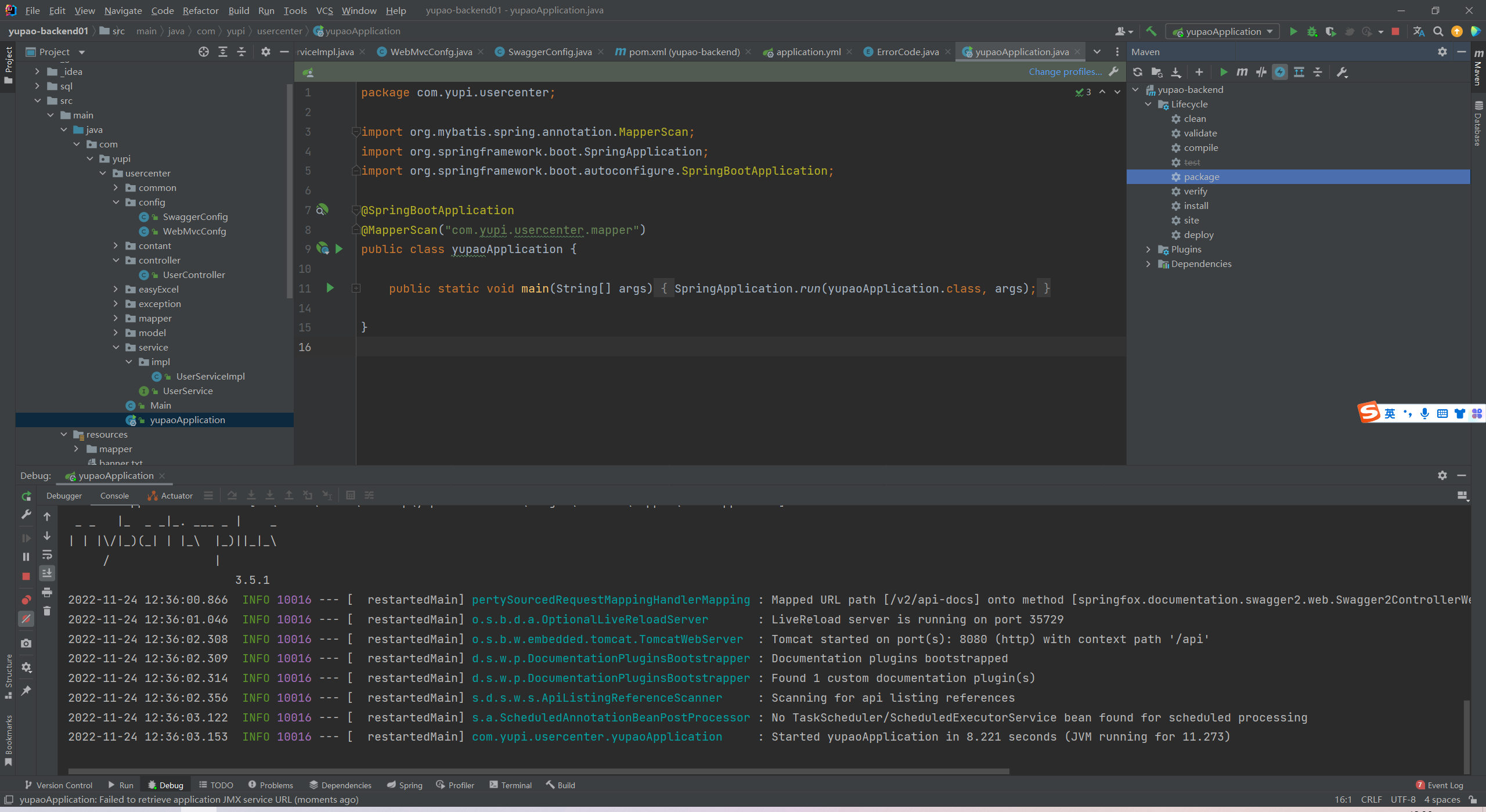
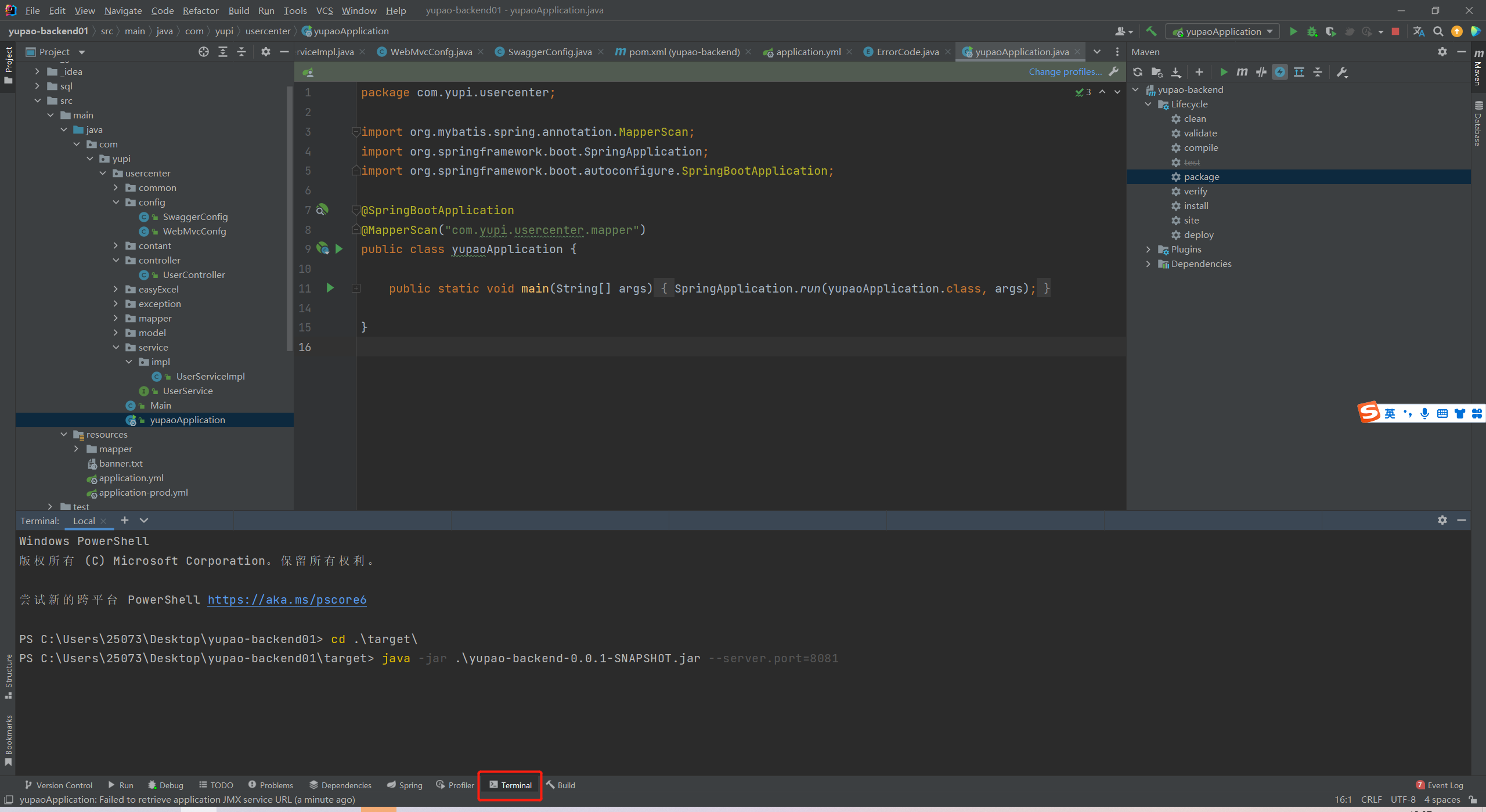
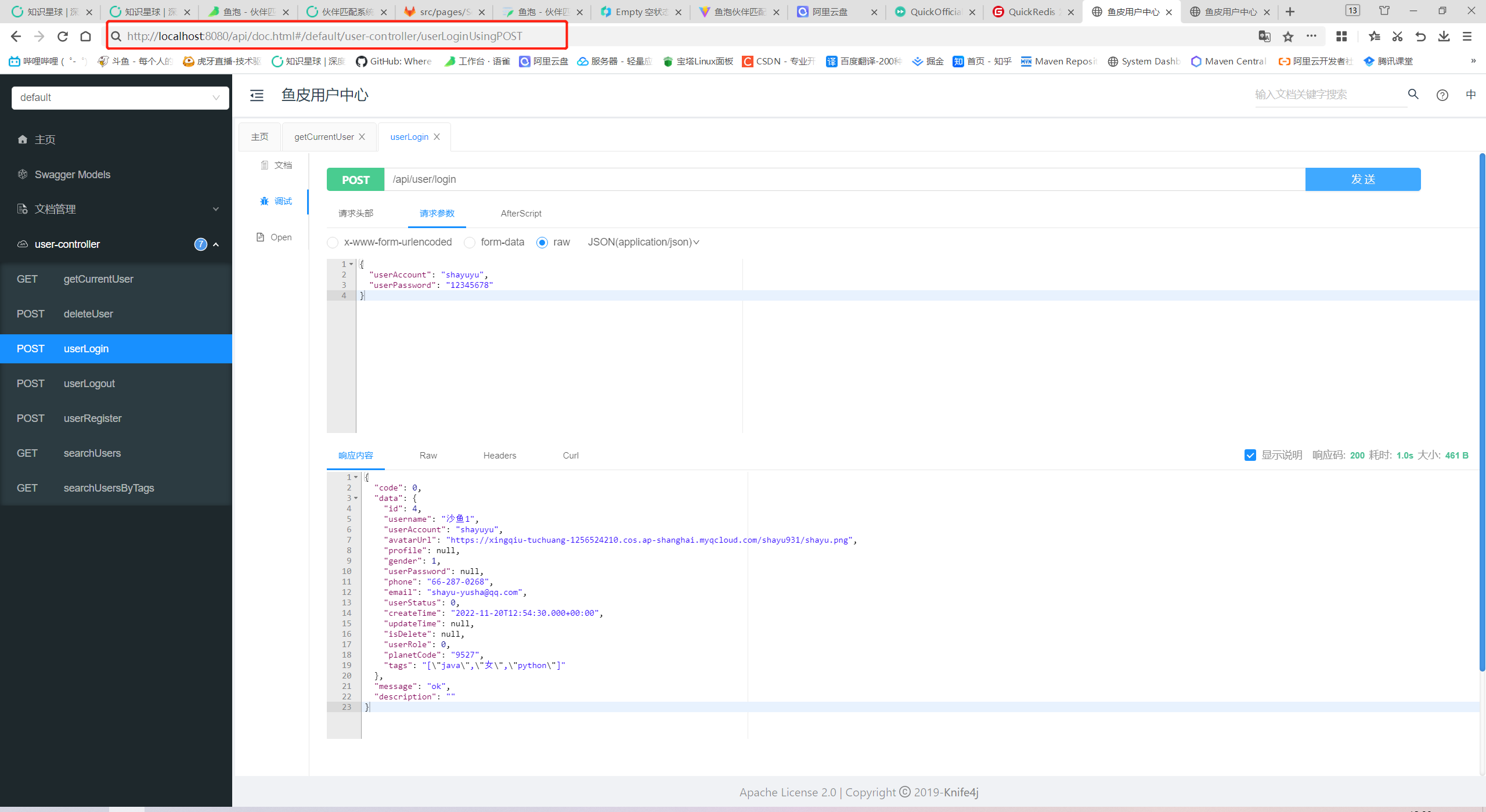
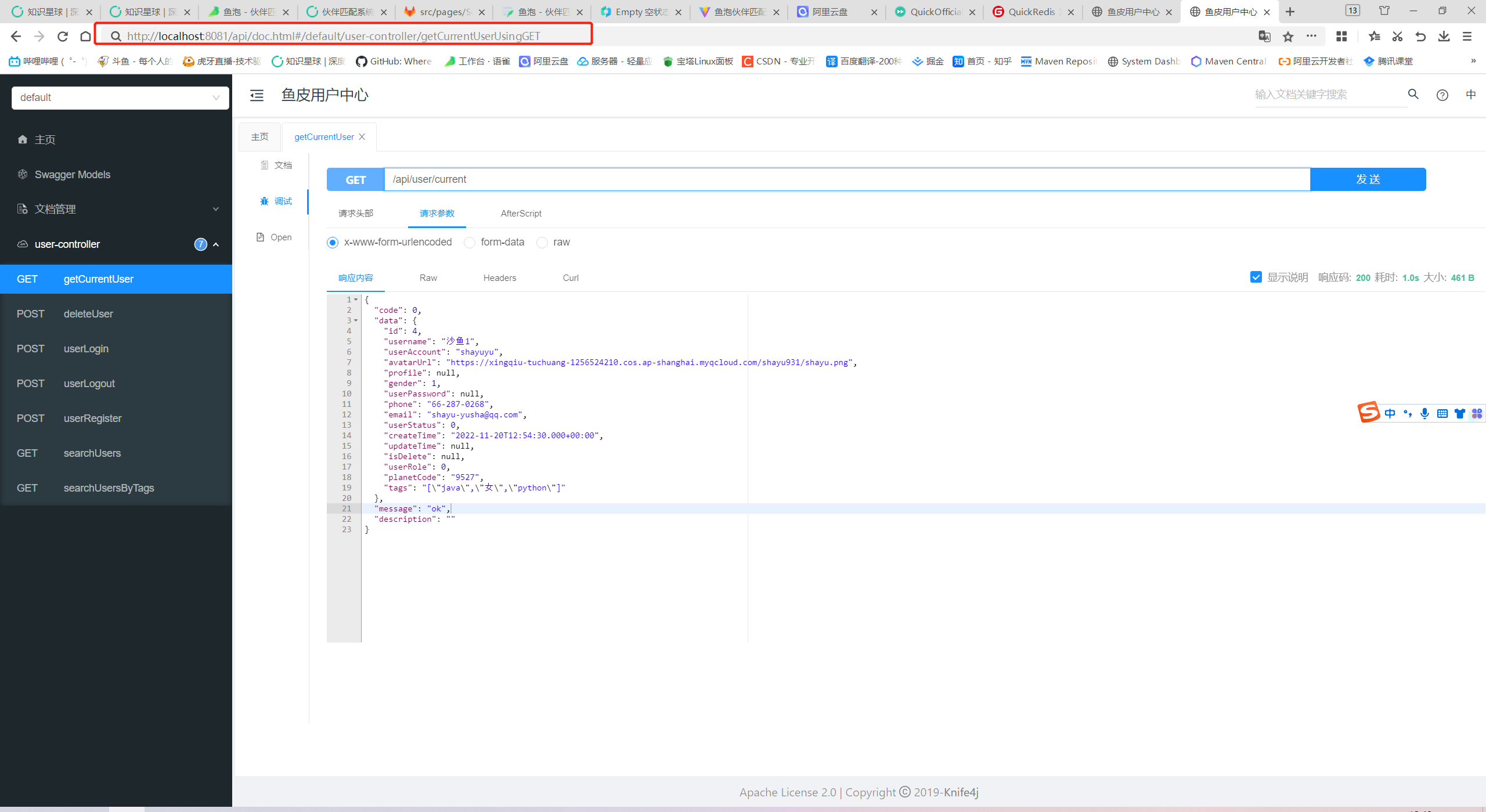
再去他们对应的swagger-ui接口测试。
在8080端口登录了,可以在8081端口获取到用户信息。
JWT 的优缺点:https://zhuanlan.zhihu.com/p/108999941
(整体来说就跨域时出现了一点点小的问题,不知道是直播时漏掉了,还是用户中心源码没有更新。其他一切都还好。)
定时任务
- 开启定时任务;注解。

- 新建InsertUser.java(鱼皮是在once文件夹,我这个是之前命名是起的,都可以无所谓的,自己记得就好。)

插件(idea里搜的)

- 编写定时任务代码并进行测试(这里的定时取巧,尽量别用,注释掉。)

- 编写定时任务测试
package com.yupi.usercenter.easyExcel;
import java.util.Date;
import com.yupi.usercenter.mapper.UserMapper;
import com.yupi.usercenter.model.domain.User;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
import org.springframework.util.StopWatch;
import javax.annotation.Resource;
/**
* @author: shayu
* @date:
* @ClassName: yupao-backend01
* @Description:
*/
@Component
public class InsertUsers {
@Resource
private UserMapper userMapper;
/**
* 循环插入用户
*/
// @Scheduled(initialDelay = 5000,fixedRate = Long.MAX_VALUE )
public void doInsertUser() {
StopWatch stopWatch = new StopWatch();
stopWatch.start();
final int INSERT_NUM = 1000;
for (int i = 0; i < INSERT_NUM; i++) {
User user = new User();
user.setUsername("假沙鱼");
user.setUserAccount("yusha");
user.setAvatarUrl("shanghai.myqcloud.com/shayu931/shayu.png");
user.setProfile("一条咸鱼");
user.setGender(0);
user.setUserPassword("12345678");
user.setPhone("123456789108");
user.setEmail("shayu-yusha@qq.com");
user.setUserStatus(0);
user.setUserRole(0);
user.setPlanetCode("931");
user.setTags("[]");
userMapper.insert(user);
}
stopWatch.stop();
System.out.println( stopWatch.getLastTaskTimeMillis());
}
}
分页查询配置
重启项目,前端主页用户信息会刷不出来,因为数据量过大。
(注意一下这里page的依赖是mybatis的)

添加mybatis,注意扫描的包要修改(如果启动类已经添加就不需要添加了)。

首页查询时候会进行redis分页查询配置
定时任务/数据预热(Redis版本)
问题:第一个用户访问还是很慢(加入第一个老板),也能一定程度上保护数据库
缓存预热的优点:
- 解决上面的问题,可以让用户始终访问很快
缺点:
- 增加开发成本(你要额外的开发、设计)
- 预热的时机和时间如果错了,有可能你缓存的数据不对或者太老
- 需要占用额外空间
怎么缓存预热?
- 定时
- 模拟触发(手动触发)
实现
用定时任务,每天刷新所有用户的推荐列表
注意点:
- 缓存预热的意义(新增少、总用户多)
- 缓存的空间不能太大,要预留给其他缓存空间
- 缓存数据的周期(此处每天一次)
定时任务实现
- Spring Scheduler(spring boot 默认整合了)
- Quartz(独立于 Spring 存在的定时任务框架)
- XXL-Job 之类的分布式任务调度平台(界面 + sdk)
第一种方式:
- 主类开启 @EnableScheduling
- 给要定时执行的方法添加 @Scheduling 注解,指定 cron 表达式或者执行频率
不要去背 cron 表达式!!!!!去查找!!!!
- https://cron.qqe2.com/
- https://www.matools.com/crontab/
新建文件夹新建文件。之前就写个的,就不具体写出来了。

定时任务会遇见的问题
控制定时任务的执行(为啥?)
- 浪费资源,想象 10000 台服务器同时 “打鸣”
- 脏数据,比如重复插入
**要控制定时任务在同一时间只有 1 个服务器能执行。(**怎么做?)
- 分离定时任务程序和主程序,只在 1 个服务器运行定时任务。成本太大
- 写死配置,每个服务器都执行定时任务,但是只有 ip 符合配置的服务器才真实执行业务逻辑,其他的直接返回。成本最低;但是我们的 IP 可能是不固定的,把 IP 写的太死了
- 动态配置,配置是可以轻松的、很方便地更新的(代码无需重启),但是只有 ip 符合配置的服务器才真实执行业务逻辑。问题:服务器多了、IP 不可控还是很麻烦,还是要人工修改
-
- 数据库
- Redis
- 配置中心(Nacos、Apollo、Spring Cloud Config)
- 分布式锁,只有抢到锁的服务器才能执行业务逻辑。坏处:增加成本;好处:不用手动配置,多少个服务器都一样。
单机就会存在单点故障。
锁
有限资源的情况下,控制同一时间(段)只有某些线程(用户 / 服务器)能访问到资源。
Java 实现锁:synchronized 关键字、并发包的类
问题:只对单个 JVM 有效
分布式锁
为啥需要分布式锁?
-
有限资源的情况下,控制同一时间(段)只有某些线程(用户 / 服务器)能访问到资源。
-
单个锁只对单个 JVM 有效。
分布式锁实现的关键
抢锁机制
怎么保证同一时间只有 1 个服务器能抢到锁?
核心思想 就是:先来的人先把数据改成自己的标识(服务器 ip),后来的人发现标识已存在,就抢锁失败,继续等待。
等先来的人执行方法结束,把标识清空,其他的人继续抢锁。
MySQL 数据库:select for update 行级锁(最简单)
(乐观锁)
✔ Redis 实现:内存数据库,读写速度快 。支持 setnx、lua 脚本,比较方便我们实现分布式锁。
setnx:set if not exists 如果不存在,则设置;只有设置成功才会返回 true,否则返回 false。
注意事项
1. 用完锁要释放(腾地方)√
2. **锁一定要加过期时间 √**
3. 如果方法执行时间过长,锁提前过期了?问题:
4. 1. 连锁效应:释放掉别人的锁
2. 这样还是会存在多个方法同时执行的情况
解决方案:续期
boolean end = false;
//线程
new Thread(() -> {
//判断状态
if (!end)}{
续期
})
end = true;
1. 释放锁的时候,有可能先判断出是自己的锁,但这时锁过期了,最后还是释放了别人的锁
// 原子操作
if(get lock == A) {
// set lock B
del lock
}
1. Redis 如果是集群(而不是只有一个 Redis),如果分布式锁的数据不同步怎么办?
Redis + lua 脚本实现
https://blog.youkuaiyun.com/feiying0canglang/article/details/113258494
RedisTemplate和RedissonClient的区别?
RedisTemplate:用于基本的 Redis 数据操作,提供类型安全和序列化支持。RedissonClient:用于实现高级的分布式功能,如分布式锁、队列等,适用于需要分布式协调的应用场景。
Redisson 如何实现分布式锁
Java 客户端,数据网格
实现了很多 Java 里支持的接口和数据结构
Redisson 是一个 java 操作 Redis 的客户端,提供了大量的分布式数据集来简化对 Redis 的操作和使用,可以让开发者像使用本地集合一样使用 Redis,完全感知不到 Redis 的存在。
spring boot starter 引入(不推荐,版本迭代太快,容易冲突)https://github.com/redisson/redisson/tree/master/redisson-spring-boot-starter
实现如下:
1. 直接引入: Quick start(快速开始)
2. 添加依赖,编写RedissonConfig文件。

/**
* Redisson 配置 => 作用是,用java作为客户端连接redis
*/
@Configuration
public class RedissionConfig {
@Value("${spring.redis.host}")
private String host;
@Value("${spring.redis.port}")
private String port;
@Value("${spring.redis.password}")
private String password ;
@Bean
public RedissonClient redissonClient(){
// 1. Create config object
Config config = new Config();
String address = "redis://" + host + ":" + port;
// 没有密码设置这个
if (StringUtils.isBlank(password)){
config.useSingleServer().setAddress(address);
}else{
config.useSingleServer().setAddress(address).setPassword(password);
}
// 2. Create Redisson instance(创建实例)
// 返回redisson对象
RedissonClient redisson = Redisson.create(config);
return redisson;
}
}
分布式锁的实现
定时任务 + 锁
- waitTime 设置为 0,只抢一次,抢不到就放弃
- 注意释放锁要写在 finally 中
@Component
@Slf4j
/**
* 实现数据定期缓存
*/
// 定时任务,每天在 23:59:59 执行
@Scheduled(cron = "59 59 23 * * *")
public void preCacheJob() {
// 获取 RedisTemplate 的 ValueOperations 实例,用于执行基本的 CRUD 操作
ValueOperations<String, Object> redis = redisTemplate.opsForValue();
// 从 RedissonClient 获取一个名为 "lock:pre:xuyuan" 的分布式锁实例
RLock lock = redissonClient.getLock("lock:pre:xuyuan");
try {
// 尝试获取锁,等待时间为 0 ms(即立即返回),并且锁的超时时间为 30 秒
if ( lock.tryLock(0, 30000L, TimeUnit.MILLISECONDS)) {
// 遍历所有用户的 ID 列表
for (Long userId : mainUserList) {
// 构建 Redis 中键的名称,格式为 "yupao:user:recommend:$s"
// 注意这里应该使用 userId 而不是 "$s"
String key = String.format("yupao:user:recommend:%s", userId);
// 如果 Redis 中不存在该键,则从数据库中查询数据
LambdaQueryWrapper<User> lqw = new LambdaQueryWrapper<>();
Page<User> page = new Page<>(1, 20); // 设置分页参数,当前页为 1,每页记录数为 20
Page<User> pageList = userService.page(page, lqw); // 查询数据库
// 尝试将查询到的数据存入 Redis
try {
// 将查询结果存入 Redis,过期时间为 1 分钟
redis.set(key, pageList, 1, TimeUnit.MINUTES);
} catch (Exception e) {
// 记录错误日志
log.info("redis set key: error {}", e);
}
}
}
} catch (InterruptedException e) {
// 记录获取锁过程中出现的异常
log.info("获取锁,出现异常");
} finally {
// 在 finally 块中释放锁
// 判断当前线程是否持有锁,如果是则解锁
if (lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
}
匹配算法
最短距离算法
* 编辑距离算法(用于计算最相似的两组标签)
这里给一个题目的描述:给定两个单词 word1 和 word2,计算出将 word1 转换成 word2 所使用的最少操作数 。你可以对一个单词进行如下三种操作。
- 插入一个字符
- 删除一个字符
- 替换一个字符
* 原理:https://blog.youkuaiyun.com/DBC_121/article/details/104198838
新建文件夹utils 编写距离算法AlgorithmUtils
模块分析
许苑模块主要分为7个模块:
-
用户模块
-
队伍模块
-
聊天模块
-
上传文件模块
-
粉丝关注模块
-
博客模块
-
AI模块
聊天室(Websocket技术)
- 导入依赖
<!--websocket-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-websocket</artifactId>
</dependency>
-
配置类WebSocketConfig,并将ServerEndpointExporter类注册成bean对象
-
/** * WebSocket配置 * 其实是创建这个配置类去扫描含有@ServerEndpoint注解 * 通过在配置类中声明一个ServerEndpointExporter bean,Spring Boot * 应用将在启动时自动扫描所有的@ServerEndpoint注解, * 并将它们注册为有效的WebSocket端点。 * 这意味着你无需在Servlet容器中手动配置WebSocket端点, * Spring会帮你完成这项工作。 */

- 创建WebSocket对象,
WebSocket类通过@ServerEndpoint注解指定了HttpSessionConfig作为配置器,从而确保每次 WebSocket 连接建立时都能正确地配置 HTTP 会话信息。

- 创建配置类,重写modifyHandshake方法,在这个方法中,通过
request.getHttpSession()获取了当前 HTTP 会话,并将其保存到ServerEndpointConfig的getUserProperties()方法Map中。

- 这样做的目的是将 HTTP 会话信息关联到 WebSocket 连接上,使得 WebSocket 连接可以访问 HTTP 会话中的信息。
/**
* 编写http会话配置类,用于获取HttpSession对象
*
* @author xuyuan
*/
@Component
public class HttpSessionConfig extends ServerEndpointConfig.Configurator implements ServletRequestListener {
/**
* 请求初始化
*
* @param sre 行为
*/
@Override
public void requestInitialized(ServletRequestEvent sre) {
//获取HttpSession,将所有的请求都获得HttpSession
HttpSession httpSession = ((HttpServletRequest) sre.getServletRequest()).getSession();
}
/**
* 修改握手
*
* @param sec
* @param request 请求
* @param response 响应
*/
@Override
public void modifyHandshake(ServerEndpointConfig sec, HandshakeRequest request, HandshakeResponse response) {
// 获取HttpSession
HttpSession httpSession = (HttpSession) request.getHttpSession();
if (httpSession != null) {
// session放入serverEndpointConfig
sec.getUserProperties().put(HttpSession.class.getName(), httpSession);
}
super.modifyHandshake(sec, request, response);
}
}
总结
websocket技术就是实现了客户端发送消息给服务端,然后经过服务端转发给对应会话的客户端。
一些疑惑性问题
Request URL: http://mate.xuyuan.asia:8082/api/user/recommend?currentPage=2&username=
Request Method: GET
其中后端方法参数@GetMapping(“/recommend”) public Result<Page> recommendUser(long currentPage, String username ,HttpServletRequest httpServletRequest),为什么参数是不需要加@RequestParam而且@GetMapping(“/recommend”)也不需要加路径符,这是为什么?
在 Spring MVC 中,当你定义了一个 GET 映射的方法来处理 HTTP GET 请求时,可以通过方法参数直接接收请求参数而不需要显式地使用
@RequestParam注解。这是因为 Spring MVC 默认会尝试将请求中的查询参数映射到控制器方法的相应参数上。只要控制器方法的参数名称与请求 URL 中的查询参数名称匹配,Spring MVC 就能自动绑定这些值。
如果不匹配:
@GetMapping("/user")
public String getUserInfo(@RequestParam("currentPage") String currentPage,
@RequestParam("username") int username) {
// 处理逻辑
return "userInfo";
}
同时可以添加注解@RequestParam进行映射。
Request URL: http://mate.xuyuan.asia:8082/api/user/24
Request Method: POST

对于URL的路径符号则需要对应的注解**@PathVariable**进行参数的映射。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









