







目录
8 Level 3: 模型是任务统一的参与者,协同作用体现在C和G之间
9 Level 4: 模型是任务统一的参与者,协同作用跨越C和G
10 Level 5: 模型是任务统一的参与者,协同作用跨越C、G和L
0 完整Tutorial内容
本文为"⭐⭐MLLM Tutorial⭐⭐——多模态大语言模型最新教程"——第六部分的学习笔记,完整内容参见:
⭐⭐MLLM Tutorial⭐⭐——多模态大语言模型最新教程-优快云博客

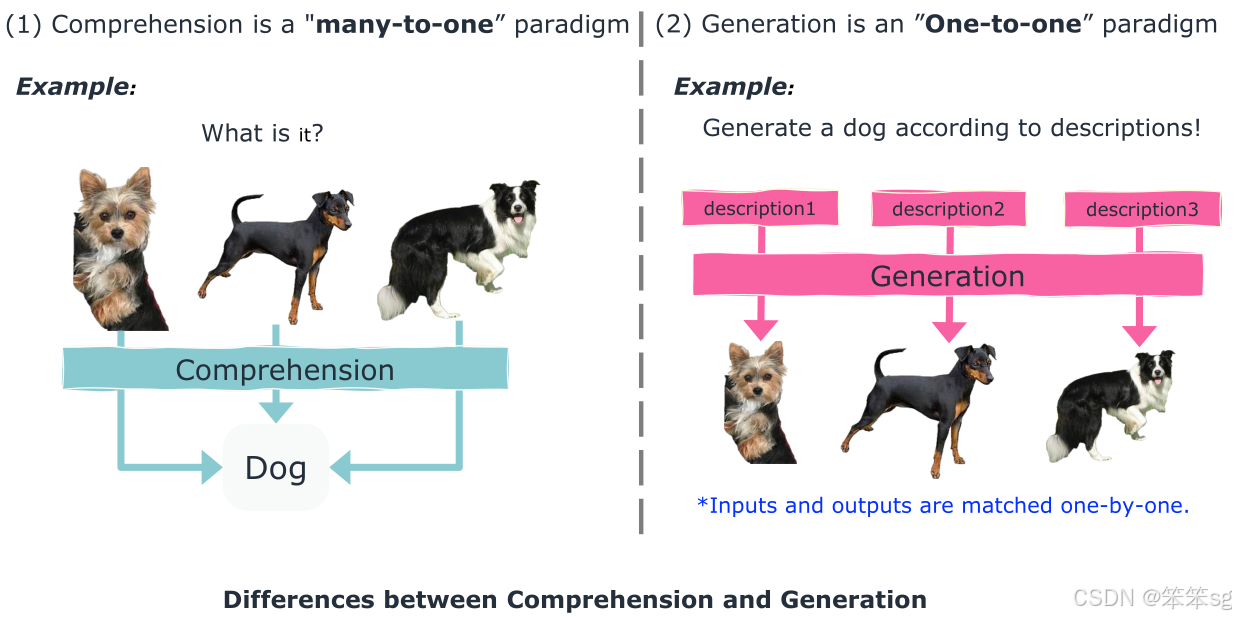
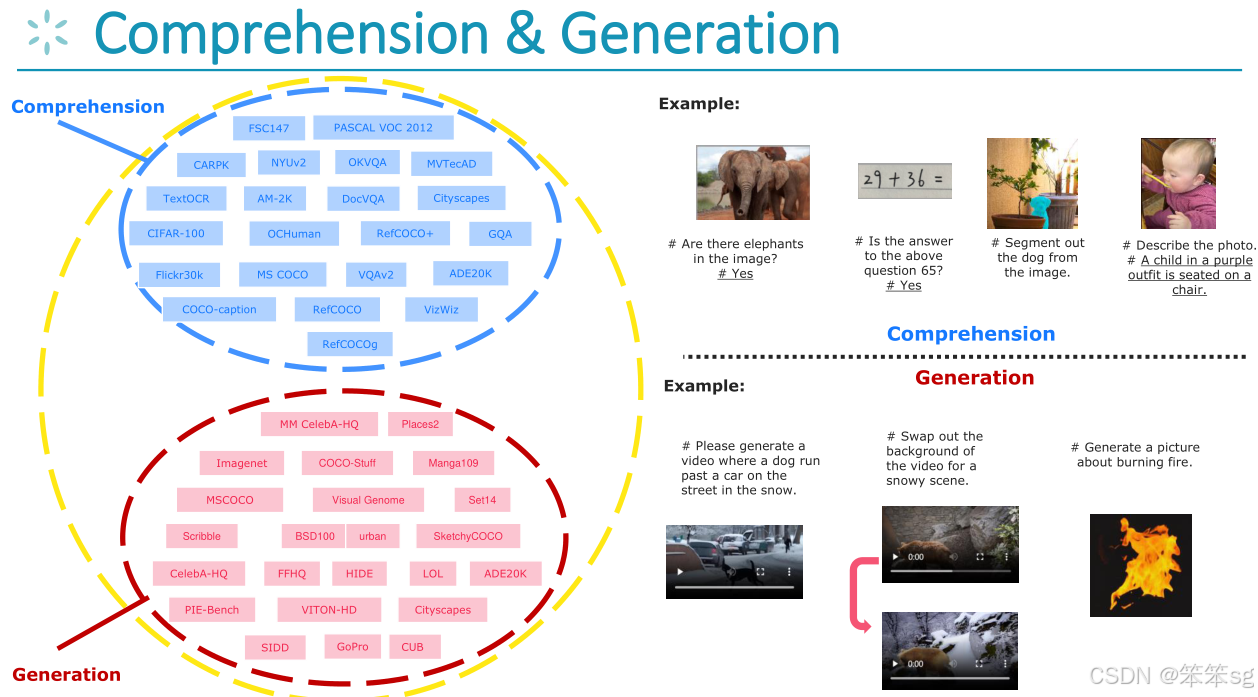
1 多模态任务的分类:
- 理解任务(Comprehension):模型的输入是图像,输出是语言。例如,图像分类就是理解任务的一个经典例子。在这种任务中,模型需要忽略输入图像的细节,将其抽象成符号。是多对一的理解过程。
- 生成任务(Generation):例如稳定扩散(Stable Diffusion)、MidJourney等图像生成任务,模型根据语言描述或视觉指令生成图像。这里的目标是精确生成与输入描述一致的图像,强调一对一的生成过程,不能丢失任何视觉细节。
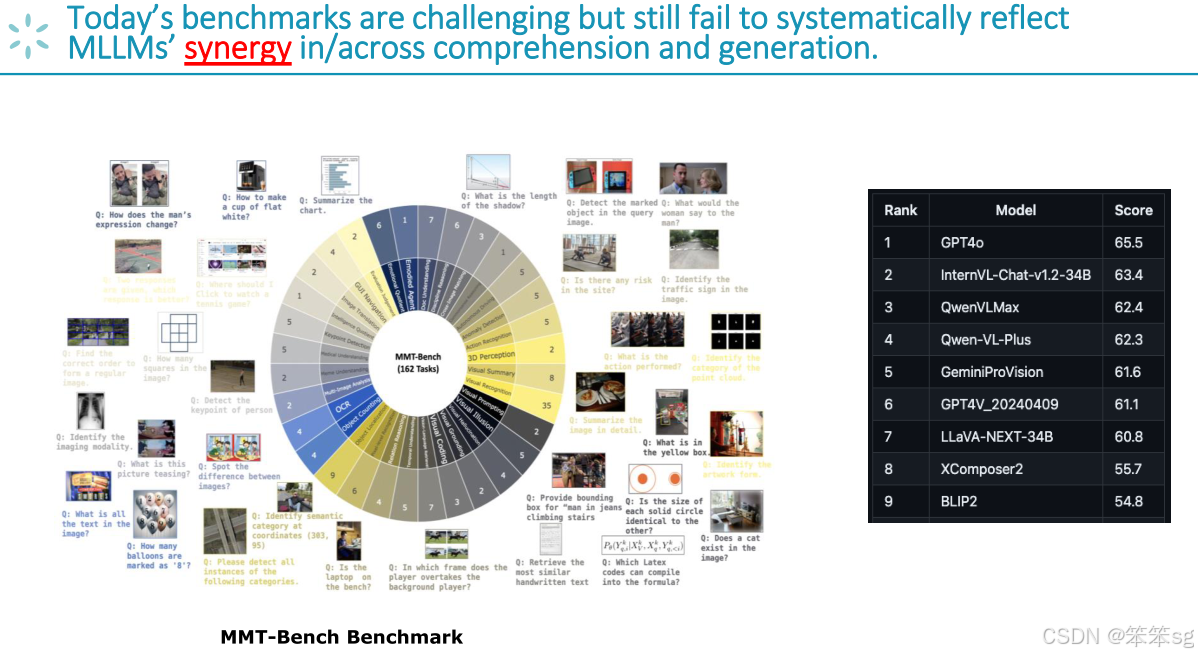
2 现有的多模态评估框架问题:
- 当前的评估大多只关注理解或生成任务,缺乏对这两种任务的协同作用的关注。
- 目前的评估框架只注重单独任务的性能,而忽略了跨任务的协同作用。理想的多模态语言模型应当能够在理解和生成任务之间取得良好的协同效果。
3 协同作用(Synergy)的定义:
- 协同作用意味着模型在多个任务中的表现加和应大于单独任务的表现。例如,如果模型能在图像描述任务中超过专门的图像描述模型,那么就说明模型有良好的协同作用。
- 协同作用不仅仅体现在单一任务上,而是要跨多个任务(如理解与生成任务),让多个任务的表现相互促进。
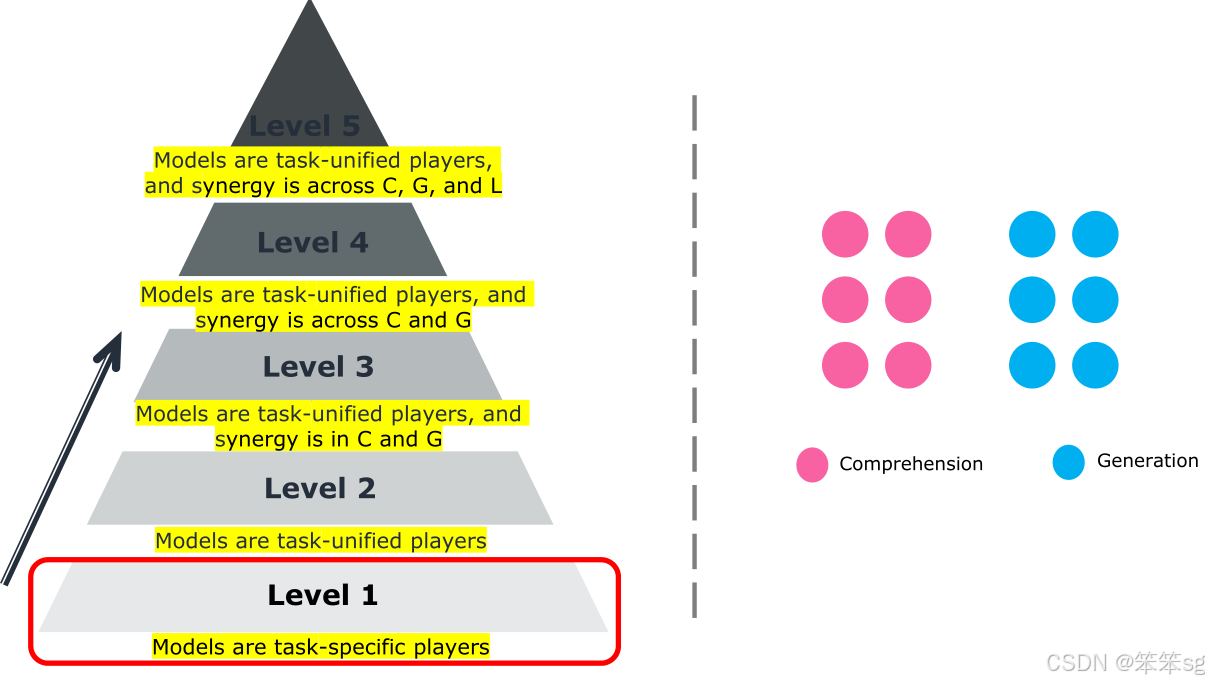
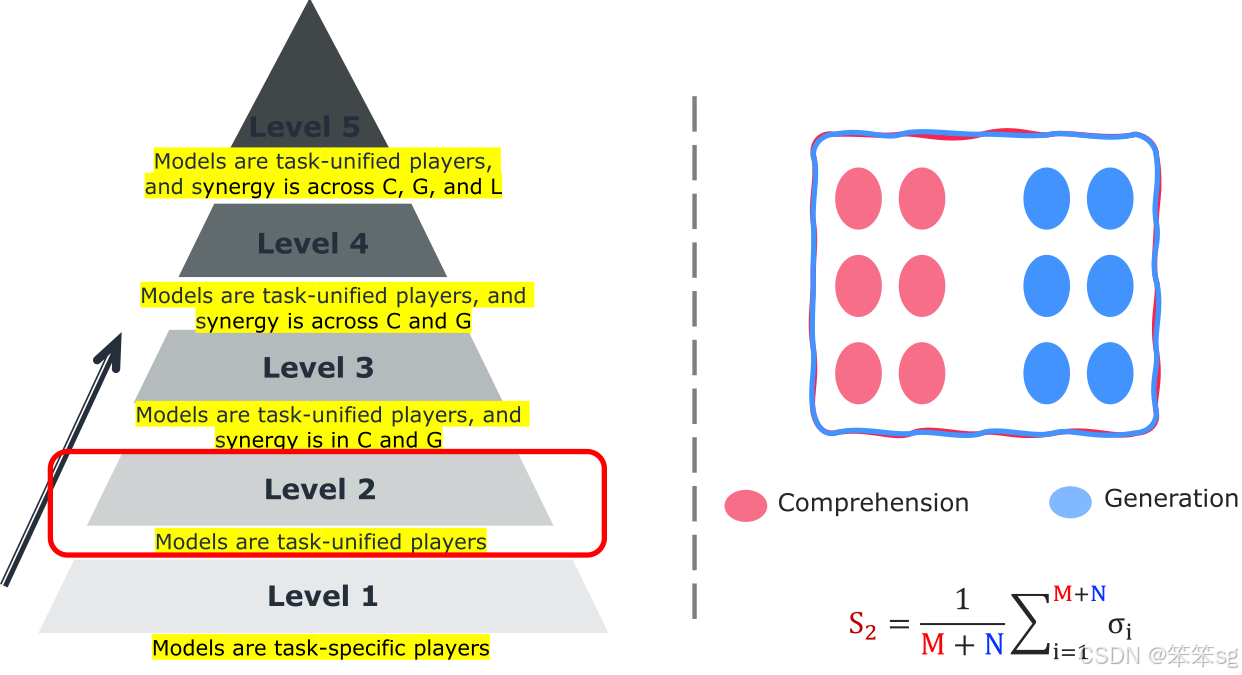
4 L5评估矩阵:
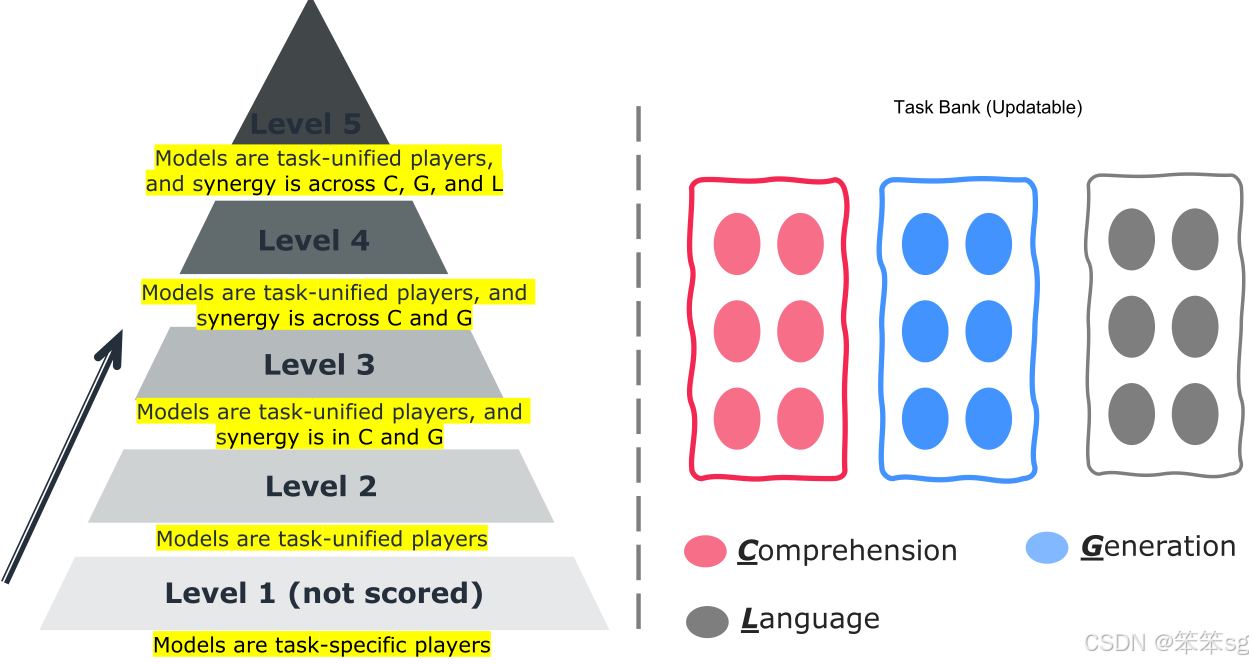
- Level 1:任务特定的参与者,只关注模型在单个任务上的表现。评估任务包括理解任务(如图像字幕生成、VQA)和生成任务(如图像生成、视频生成)等。
- Level 2:专注于评估多模态语言模型是否能完成更多任务。模型能完成的任务越多,得分越高,但不关注协同作用。
- Level 3:开始关注协同作用,评估模型是否能在理解任务(如图像描述)上超越专门的任务模型。这意味着模型在某些任务上的表现超越了传统的专门化模型。
- Level 4:协同作用不仅限于理解任务和生成任务之间,还要求两者之间的协同,增强理解任务(如图像字幕生成)对生成任务(如图像生成)的支持。
- Level 5:要求跨理解、生成和原始语言任务实现全面的协同作用。此级别评估模型在多模态理解和生成任务的协同作用,同时不牺牲原始语言任务的表现。
协同作用的挑战:模型通常需要针对视觉任务进行微调(fine-tuning),这可能会导致其语言任务性能下降。Level 5的评估旨在确保模型在语言任务上的表现不因多模态任务的微调而受到负面影响。
5 任务调度器(Task Dispatcher):
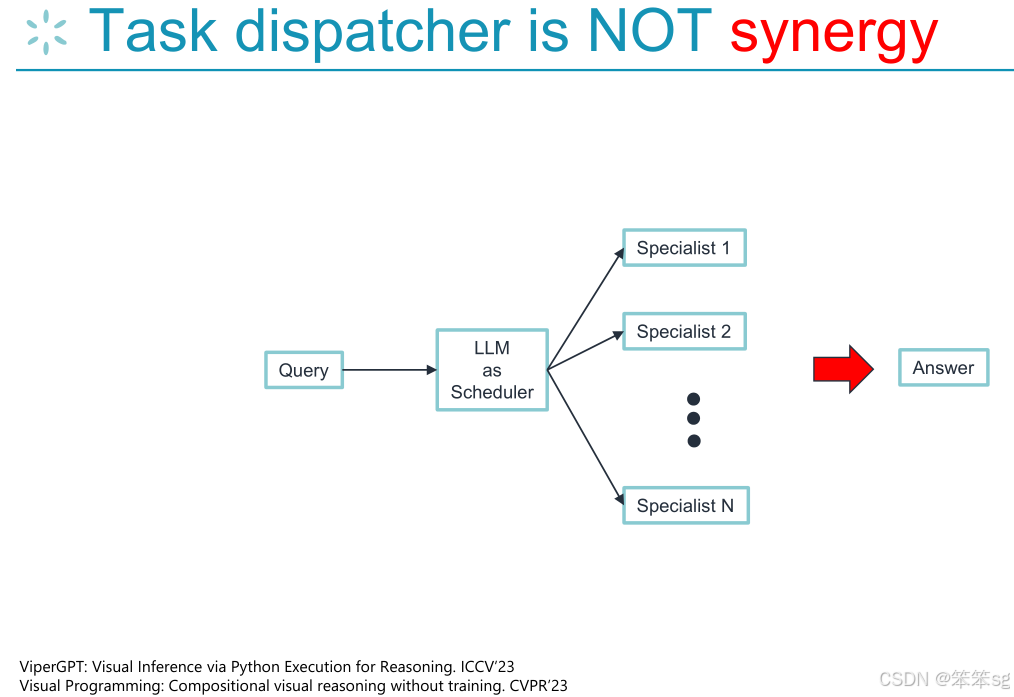
Hanan提到,像VIPER GPT这样的视觉编程模型,其本质上是一个任务调度器,它将任务分配给专门的模型来执行,因此这些模型无法实现真正的协同作用,因为它们仅依赖于单个任务的专门化。
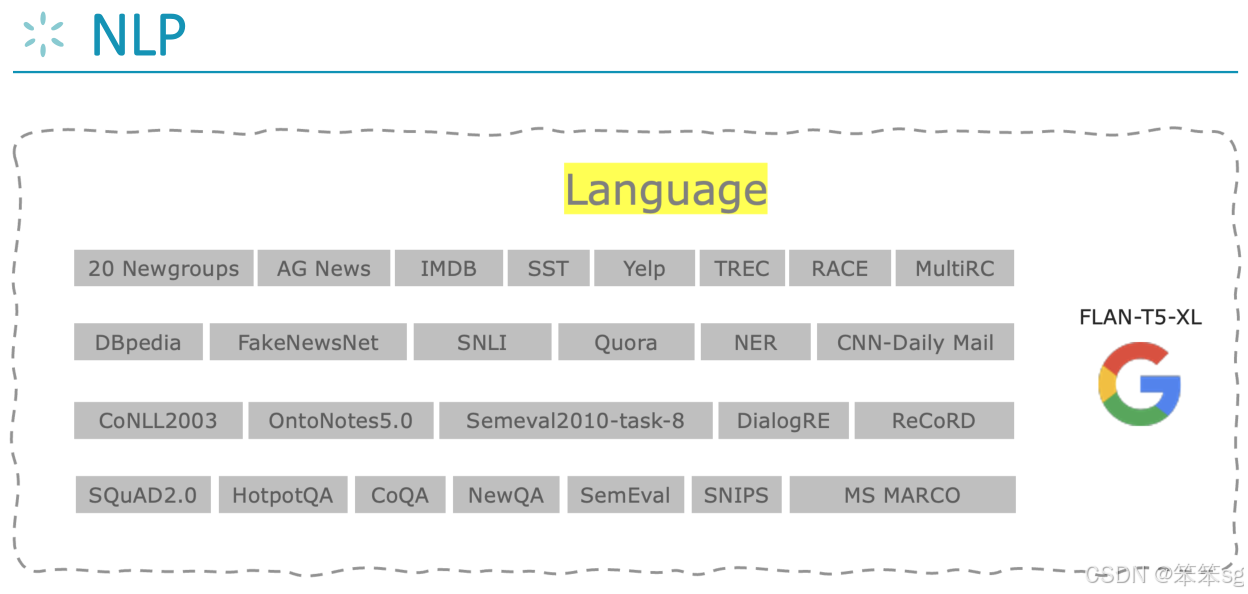
关于这两种任务的数据集如下图所示:
Google的T5是目前在这些评估中表现最好的模型。
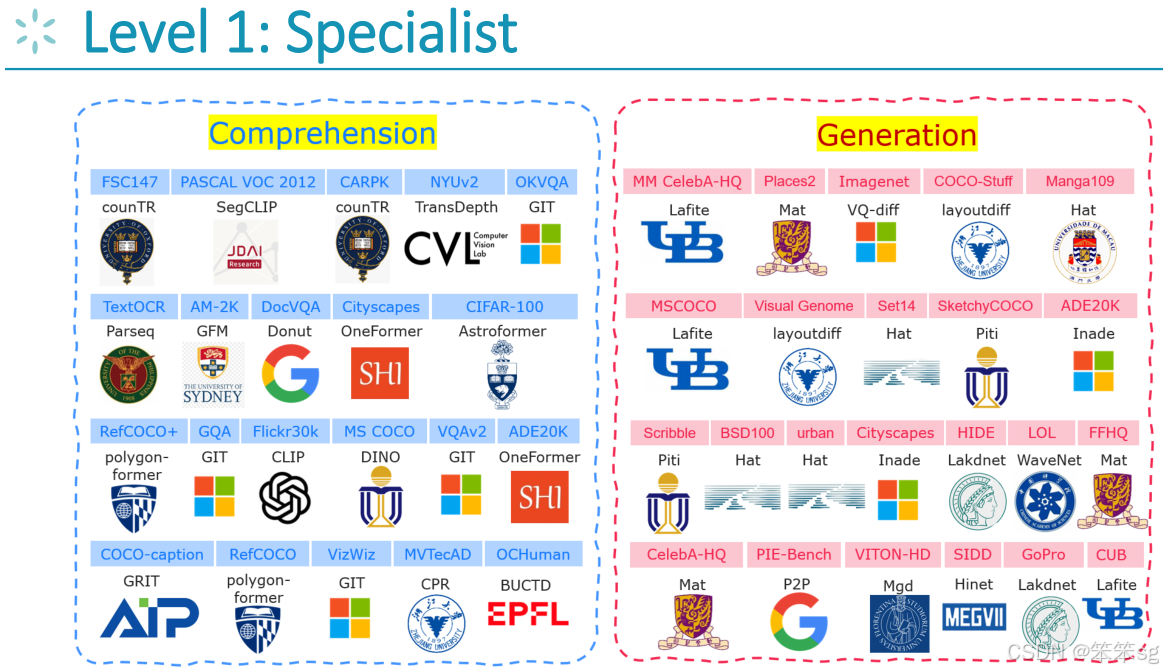
6 Level 1: 模型是任务特定的参与者
在Level 1中,评估只关注任务特定的专家模型(SOA Specialist)。也就是说,评估的重点是每个任务的专门化模型,而不涉及多模态协同作用。
强调不要限制模型只能使用传统的架构(如FCN或MN),特别是在2024年,使用更强大的大模型(如大语言模型)是更合适的。
通过微调(fine-tuning),大型模型可以针对特定任务进行优化,从而提升在该任务中的表现。例如,在分割任务或文本到图像的下游任务(如视觉编辑)中,微调可以显著提高模型的任务适应性。
对于一些特定任务,如图像分割,可以使用像Pixel-to-Pixel的微调方法,或者使用稳定扩散(Stable Diffusion)等技术来调整大型模型。
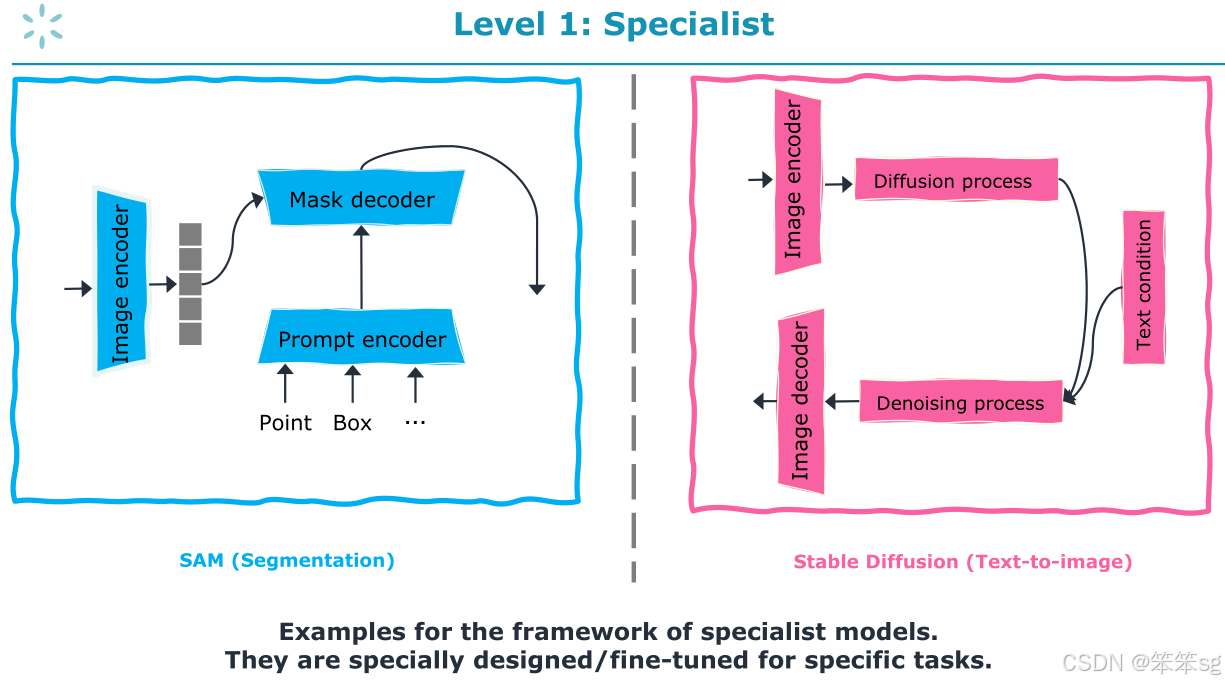
微调大型模型有助于确保它们在每个特定任务中达到SOTA(State-of-the-art)表现,因此可以在每个单独的任务中获得最佳的性能。
例如,在六个月前的实验中,微调后的大型模型成功在各自的特定任务中超越了当前的SOTA,成为一个基准模型。
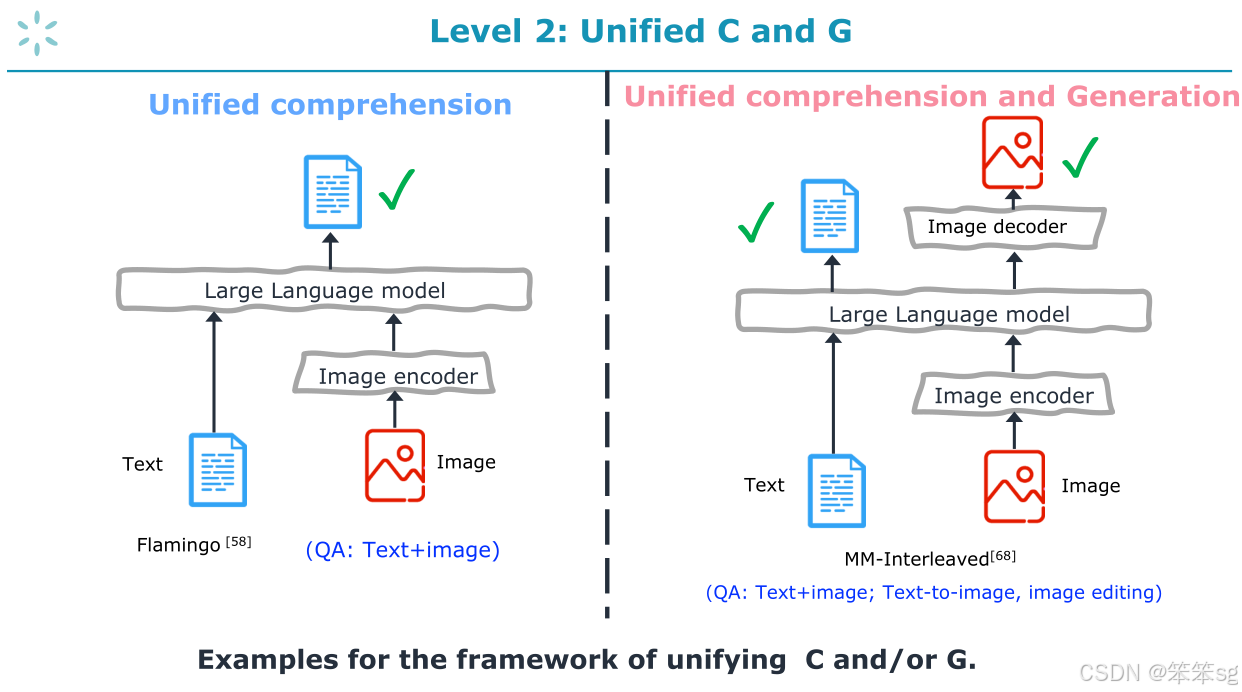
7 Level 2: 模型是任务统一的参与者
在Level 2中,评估的关键是模型能够完成多少任务,完成的任务越多,得分越高。
这里不考虑不同任务之间的协同效应(Synergy),仅关注模型在多个任务中的表现。
左侧是像GPT-4o这样的仅用于“理解”任务的大型语言模型,右侧则是最新的可调节大型语言模型(例如Vitron、Emu2),能够同时处理生成和理解任务。
生成任务(one-to-one)与理解任务(many-to-one)存在一定冲突。
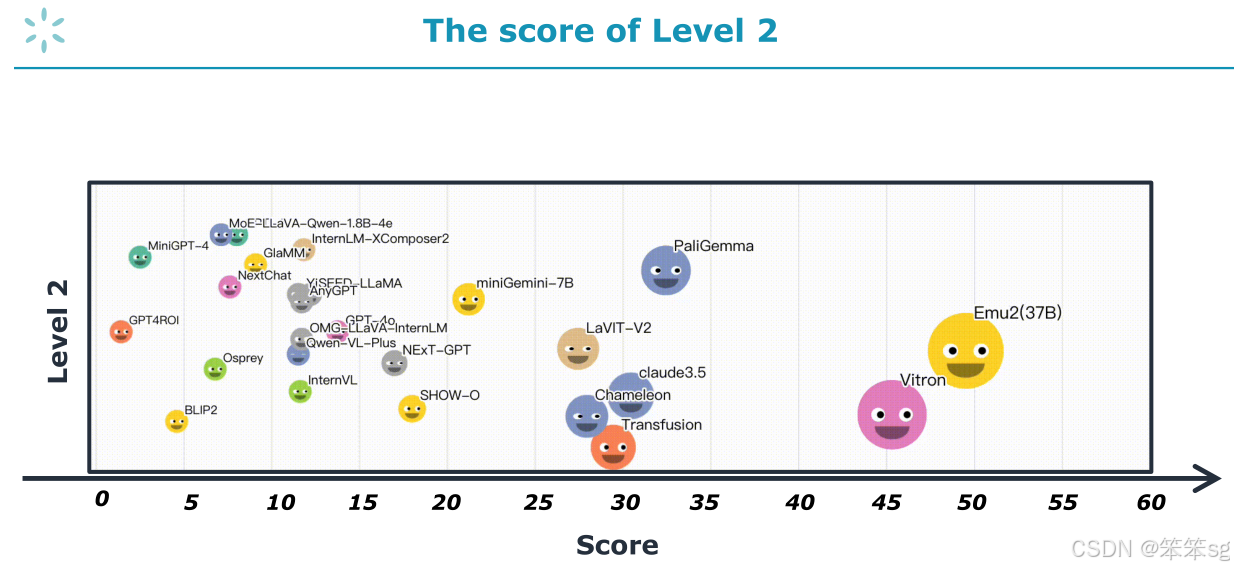
评估矩阵(Matrix)展示了任务模型的表现。例如,GPT-4o只能执行理解任务,因此其得分位于中间的某个位置,而像Vitron、Emu2这样的模型(尽管我们没有足够时间进行完整评估)则位于得分较高的位置。
8 Level 3: 模型是任务统一的参与者,协同作用体现在C和G之间
在Level 3中,如果一个大型多模态语言模型(MLLM)无法超越一个专业任务的表现,那么它将被评分为零。
评估的目标是:模型越能超越专家任务,得分越高。
这意味着很多模型在Level 3的评估中将会被“踢出”,并且它们的得分会显著下降。
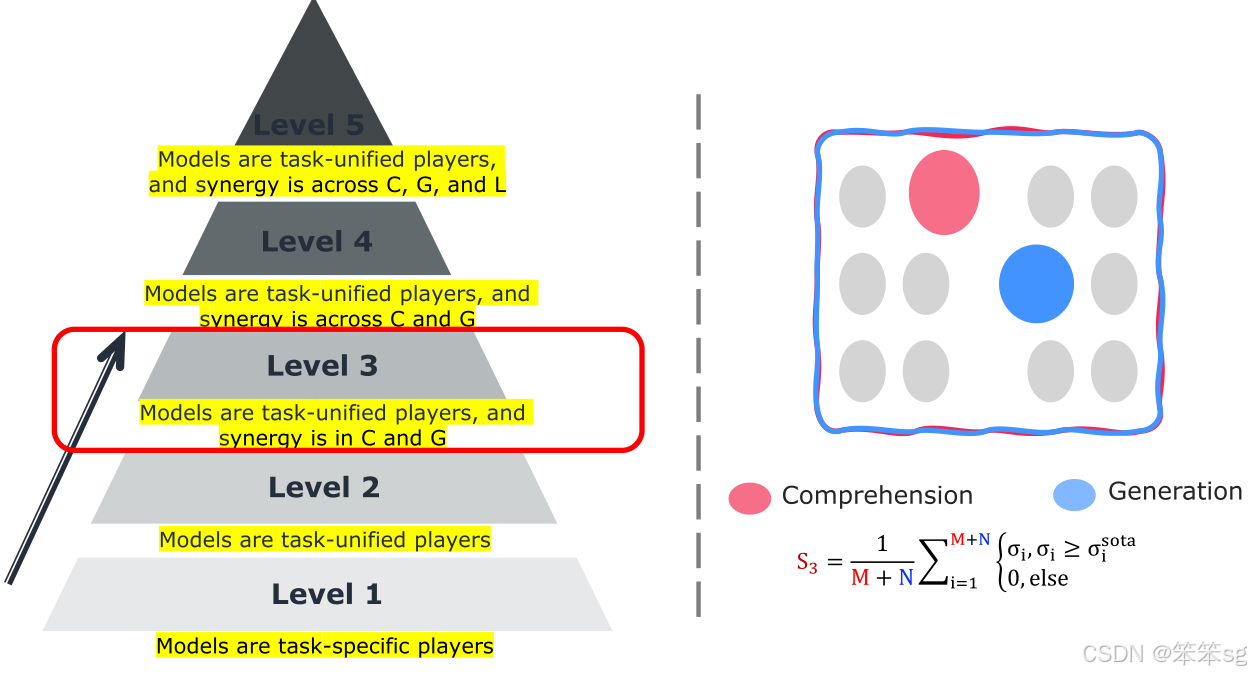
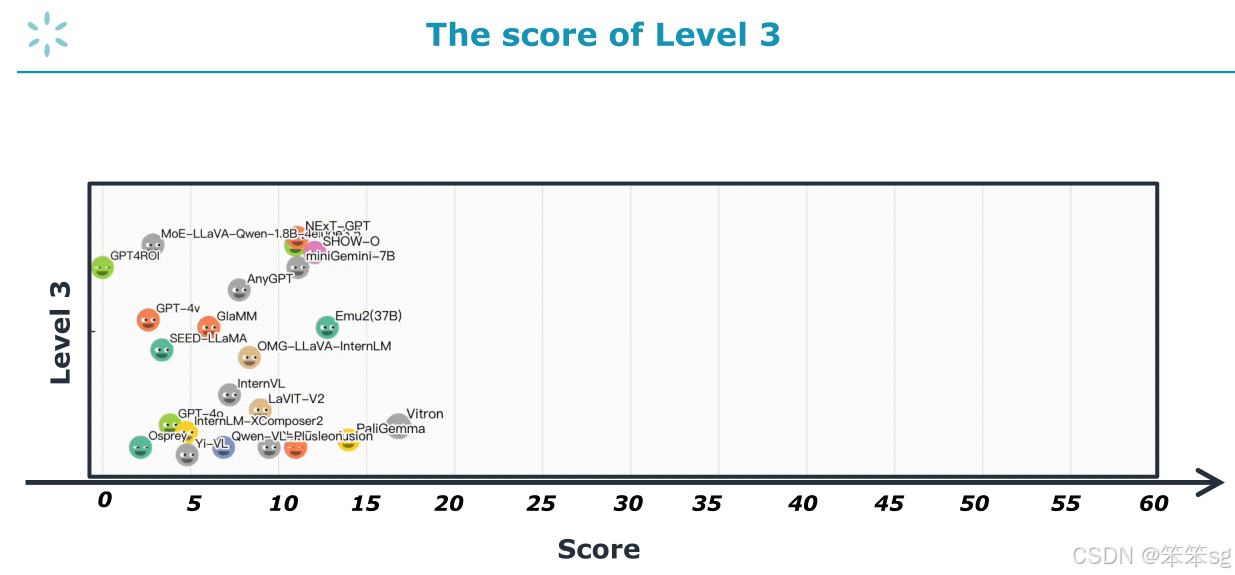
只有那些能够在多个任务上超越专门化模型的MLLM,才能在Level 3中获得较高的分数。
9 Level 4: 模型是任务统一的参与者,协同作用跨越C和G
Level 4评估中,鼓励理解和生成任务之间的协同效应,使用调和平均数来平衡这两种能力。
如果一个模型在理解任务上表现非常好,但在生成任务上表现不佳(例如,GPT-4o只擅长理解任务),它的得分将会是零,因为它无法在生成任务中表现出色。
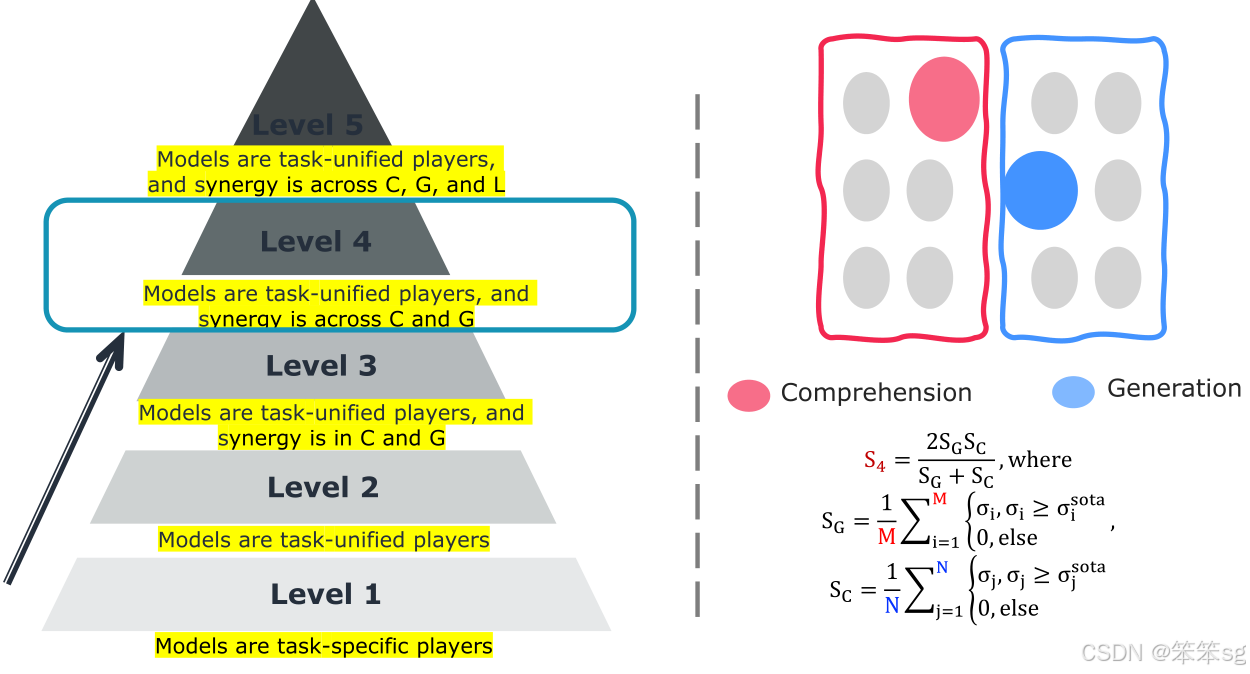
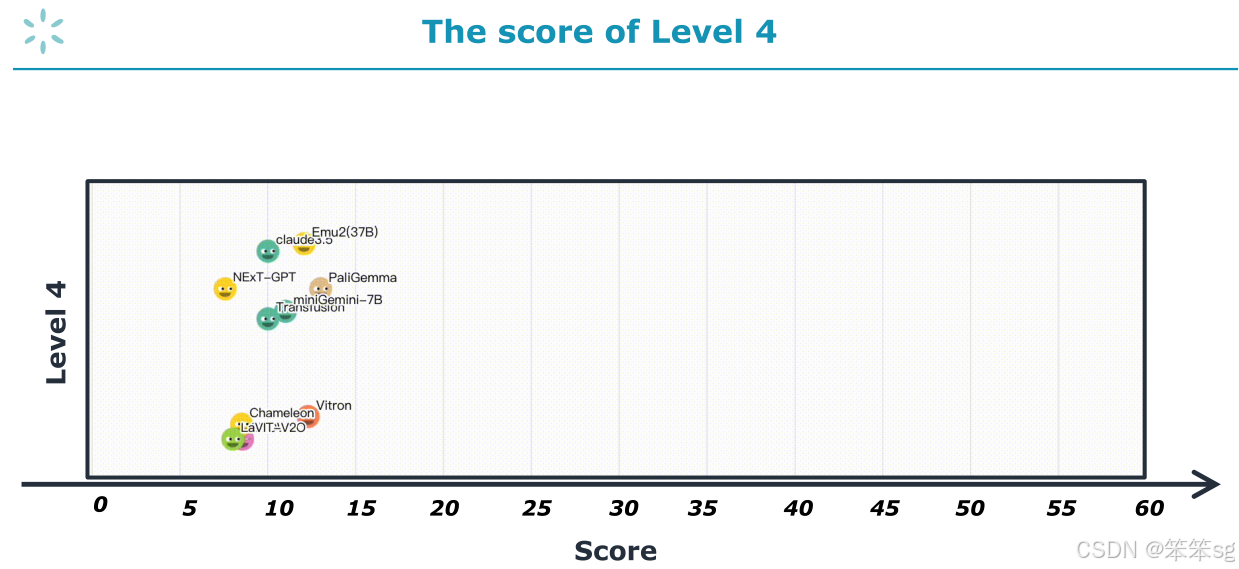
如果一个模型在理解任务上表现得很好(例如GPT-4o在理解任务上能达到100%的得分),但在生成任务上得分为零,那么它在Level 4的得分就会被判定为零,因此GPT-4o将会被淘汰。
在Level 4,只有不到10个模型能够存活下来。
10 Level 5: 模型是任务统一的参与者,协同作用跨越C、G和L
Level 5的评估进一步严格,因为它要求模型在多模态理解与生成之间保持平衡,同时还要求在传统的语言任务中表现优异。
因为大部分多模态语言模型在优化多模态能力时,通常会在纯语言任务上有所退化,目前没有模型能够在Level 5存活。
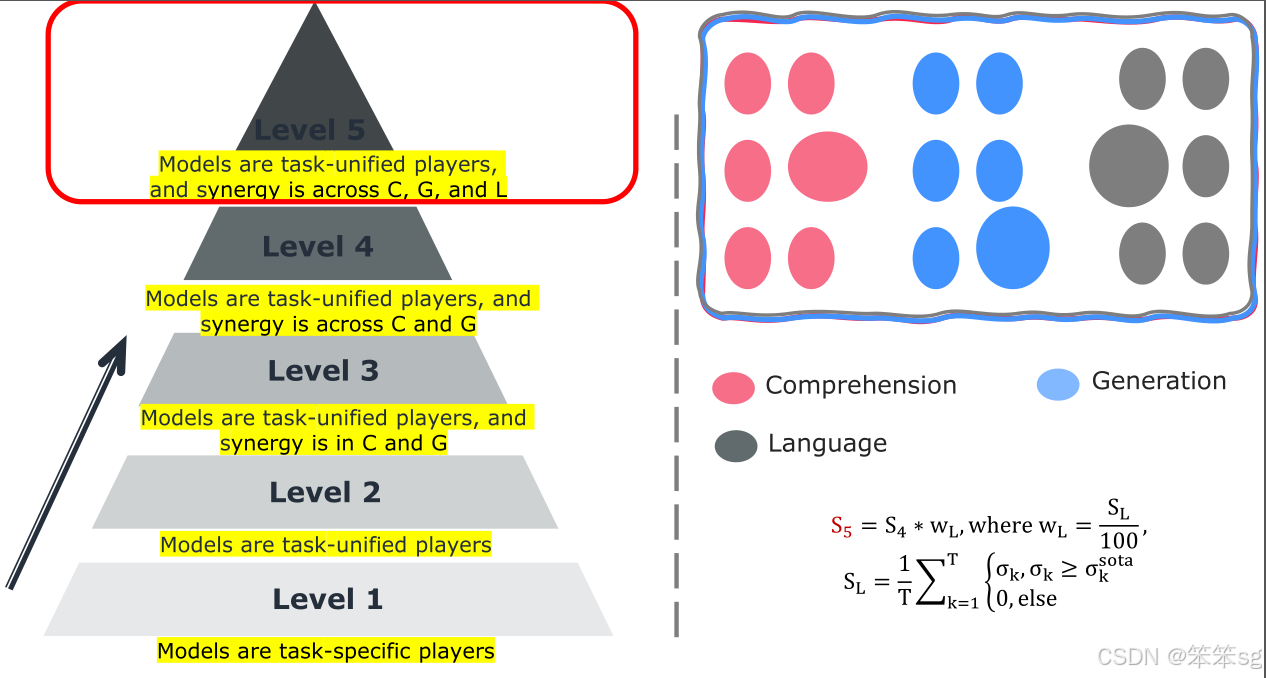
对于大型多模态语言模型(MRM)而言,最终目标是超越各个领域的专家,在每个模态、领域和特定任务中都能取得优异表现。
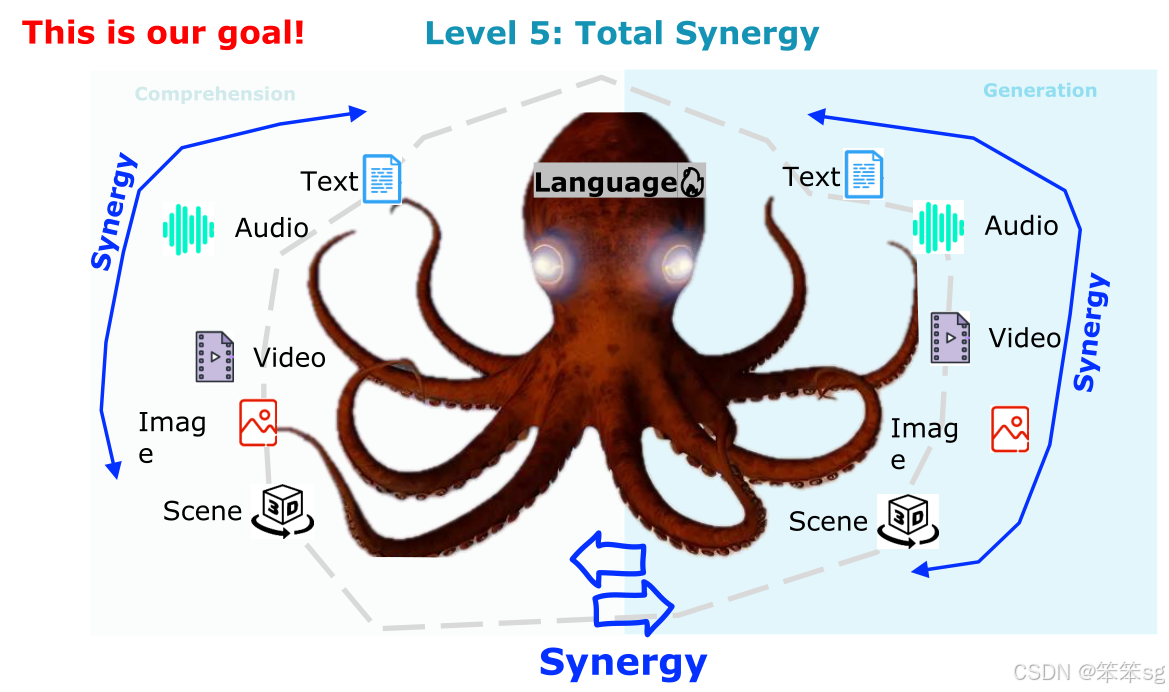
Level Five(第五级)是当前的目标,但没有模型能够达到这一水平。

11 从L3到L5的攀升:理解与生成的不一致性
要从 Level 3(L3)攀升到 Level 5(L5),我们面临的主要挑战是理解(Comprehension)和生成(Generation)任务之间的 不一致性。以下是从这两个方面的挑战展开的详细分析:

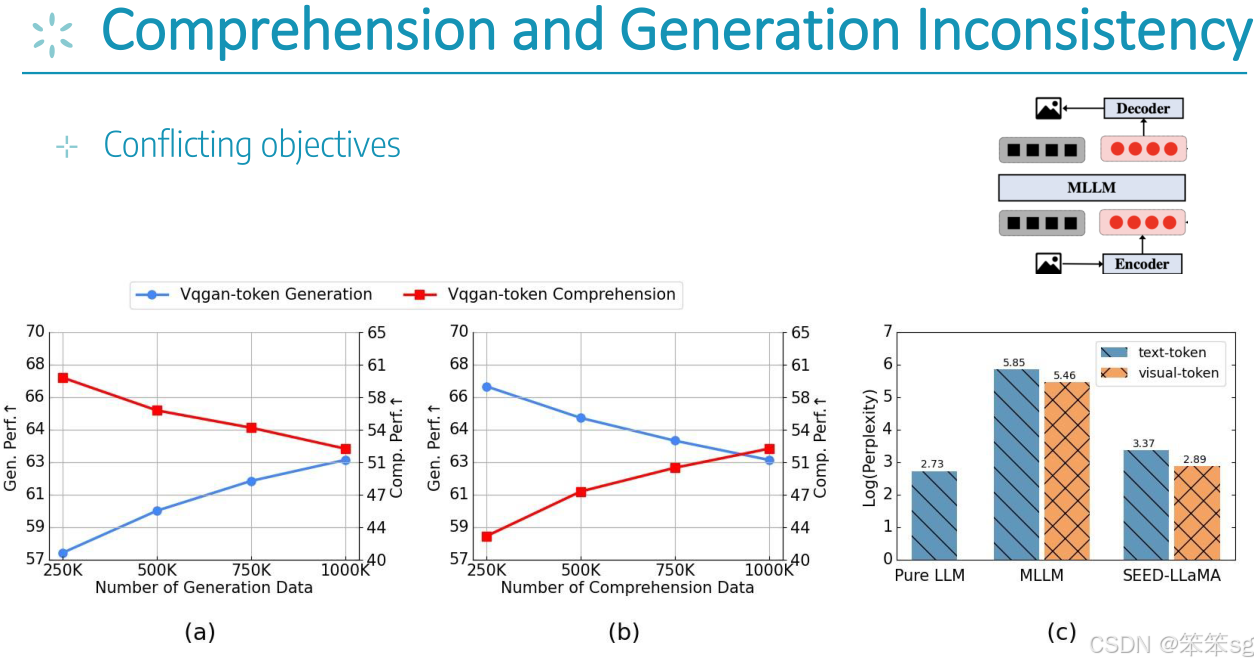
11.1 挑战1:语言(V)≠ 语言(L)

- 视觉语言与文本语言的差异:
- 语言(L) 通常指的是 文本语言,这是一种递归结构的语言,具有丰富的语法和语义规则。在计算语言学中,语言被认为是 递归的,即可以不断地扩展和嵌套,增加更多的复杂性。
- 视觉语言(V) 是针对视觉输入的 图像或视频数据,它的 token化 更加简单和直接,通常通过空间位置(patches)表示视觉信息。视觉数据不像文本语言那样具备递归性,而是局部性的、固定格式的图像块。因此,视觉语言并不具备与文本语言相同的递归结构,这使得其在与文本语言结合时,会带来困难。
- 解决方案的挑战:
- 为了实现 L3 到 L5 的提升,需要将视觉语言与文本语言的差异进行统一,尤其是在处理多模态输入时,如何将视觉数据转化为与文本语言一致的、可递归的结构,是一个关键问题。换句话说,我们需要使 视觉语言 更具 递归性,以便与文本语言的特点匹配。
- 视觉token的表达能力仍然需要提升,使其能够捕捉到更复杂的语义和推理关系,从而更好地与文本语言的表达方式融合。
11.2 挑战2:生成(V)≠ 生成(L)
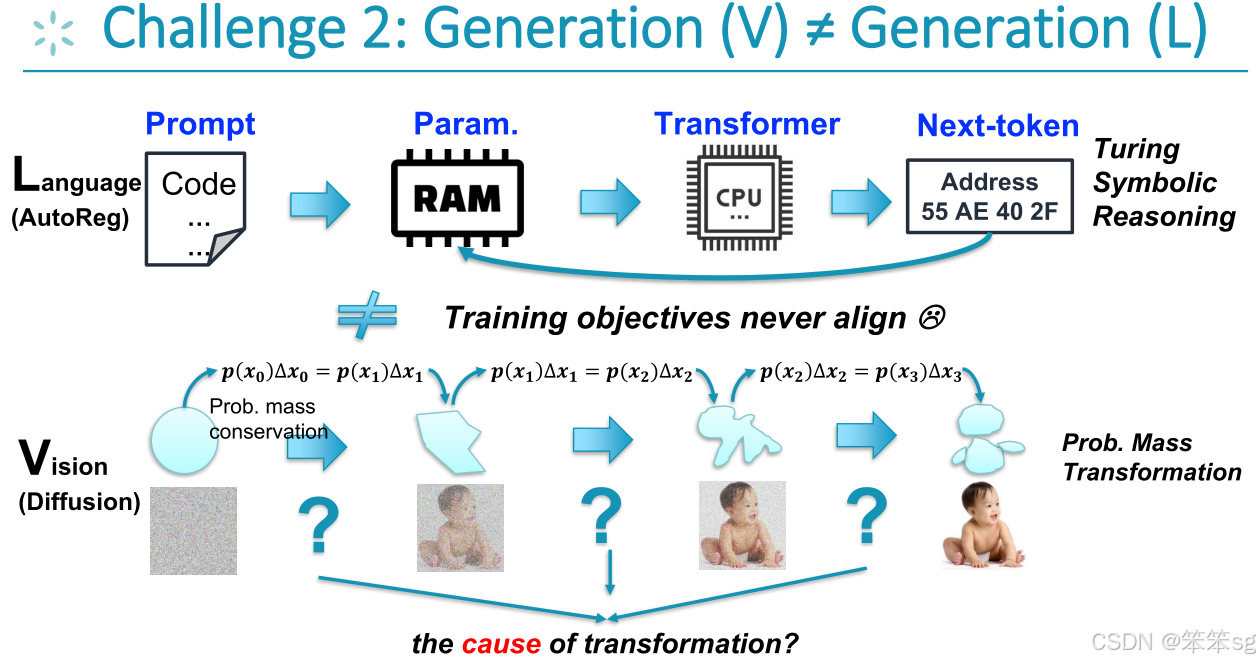
-
生成任务的本质差异:
- 文本生成(L):大多数文本生成模型(如 GPT 系列)采用 自回归(autoregressive)方法。每次生成时,模型根据上一个生成的token来预测下一个token。这种方法依赖于顺序和上下文一致性,具有递归的生成过程。
- 视觉生成(V):视觉生成任务(如图像生成、扩散模型)采用的是 扩散过程(diffusion process)或者 对抗生成网络(GANs)等方法。这些方法通过从简单的随机噪声逐步恢复图像的细节,非递归地生成最终的图像。这个过程与文本生成的自回归方式完全不同,因其更关注 图像细节的逐步调整和生成,而非语言中信息的逐步累积和推理。
-
解决方案的挑战:
- 在从 L3 到 L5 的过程中,生成任务之间的差异必须得到解决。如果模型在视觉生成上表现优秀,但在文本生成上却无法保持语言一致性(反之亦然),则无法实现多模态生成的协同效果。
- 要解决这一问题,视觉生成与语言生成的模型架构需要更加统一,使得生成过程既能在视觉生成任务中进行精细化调整,也能在语言生成任务中保持一致性。例如,可以通过设计一种联合生成框架,使得模型能够同时处理视觉与文本的生成任务,并且能够在这两种任务之间进行无缝切换。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









