






基础概念是无趣却又不可缺少的
以下内容来自这位老哥的博客(写的真的很好,万分感谢),加上一点点自己的理解:
kafka学习之路(一)
还有后面的学习之路可以自行百度,本篇是我自己一个小小的记录
还有想直接知道咋搭建单机版的戳这里:
win10搭建一个单机版的kafka(kafka踩坑二)
kafka是什么
Kafka是最初由Linkedin公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式日志系统(也可以当做MQ系统)
kafka的特点(设计目标)
- 高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个topic可以分多个partition, consumer group 对partition进行consume操作。
- 可扩展性:kafka集群支持热扩展
- 持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
- 容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
- 高并发:支持数千个客户端同时读写
消息系统的分类
- 点对点传递模式:生产者发送一条消息到queue,只有一个消费者能收到
- 发布-订阅模式:发布者发送到topic的消息,只有订阅了topic的订阅者才会收到消息
kafka就属于发布-订阅模式的消息系统——
消息被持久化到一个topic中,消费者可以订阅一个或多个topic,消费者可以消费该topic中所有的数据,同一条数据可以被多个消费者消费,数据被消费后不会立马删除。
kafka的优点
- 解耦:消息系统在处理过程中间插入了一个隐含的、基于数据的接口层,两边的处理过程都要实现这一接口。因此接口两边可以独立开发或扩展生产者和消费者的处理过程
- 冗余:消息在被确认已经处理完毕之前不会被删除,确保数据直到使用完毕之前的完整,减少数据丢失风险
- 扩展性:在解耦的基础上,增大消息入队的频率和处理,只需要增加处理方法即可
- 灵活性&峰值处理能力:消息队列使得在访问量剧增的情况下仍能够正常运行
- 可恢复性:在消息队列的帮助下,部分组件失效时,不会影响整个系统运行,即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理
- 顺序保证:消息队列的排序
- 缓冲:消息队列通过一个缓冲层来帮助任务最高效率的执行———写入队列的处理会尽可能的快速
- 异步通信:入队的消息可以不立即进行处理,可以等到使用者需要的时候再去处理
kafka的术语
要理解术语需要从一张关系图开始(老哥的方法很好的帮助我理解这些术语)
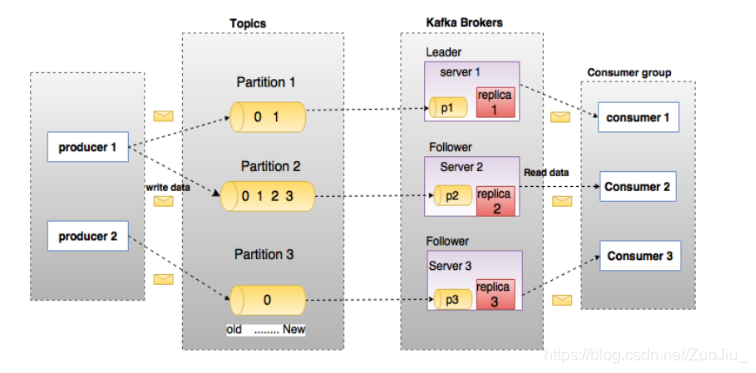
上图中一个topic配置了3个partition。Partition1有两个offset:0和1。Partition2有4个offset。Partition3有1个offset。副本的id和副本所在的机器的id恰好相同。
如果一个topic的副本数为3,那么Kafka将在集群中为每个partition创建3个相同的副本。集群中的每个broker存储一个或多个partition。多个producer和consumer可同时生产和消费数据。
-
broker:Kafka 集群包含一个或多个服务器,broker就是服务器的节点,broker用以存储topic的数据。
如果某topic有N个partition,集群有N个broker,那么每个broker存储该topic的一个partition。
如果某topic有N个partition,集群有(N+M)个broker,那么其中有N个broker存储该topic的一个partition,剩下的M个broker不存储该topic的partition数据。
如果某topic有N个partition,集群中broker数目少于N个,那么一个broker存储该topic的一个或多个partition。在实际生产环境中,尽量避免这种情况的发生,这种情况容易导致Kafka集群数据不均衡。 -
Topic:每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)类似于数据库的表名
-
Partition(每一个partition都是一个主从模式的架构):topic中的数据分割为一个或多个partition。每个topic至少有一个partition。每个partition中的数据使用多个segment文件存储。partition中的数据是有序的,不同partition间的数据丢失了数据的顺序。如果topic有多个partition,消费数据时就不能保证数据的顺序。在需要严格保证消息的消费顺序的场景下,需要将partition数目设为1
-
Producer:生产者即数据的发布者,该角色将消息发布到Kafka的topic中。broker接收到生产者发送的消息后,broker将该消息追加到当前用于追加数据的segment文件中。生产者发送的消息,存储到一个partition中,生产者也可以指定数据存储的partition
-
Consumer:消费者可以从broker中读取数据。消费者可以消费多个topic中的数据。
-
Consumer Group:每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group),同一Topic的一条消息只能被同一个Consumer Group内的一个Consumer消费,但多个Consumer Group可同时消费这一消息
-
Leader:每个partition有多个副本,其中有且仅有一个作为Leader,Leader是当前负责数据的读写的partition
-
Follower(与leader类似集群主从):Follower跟随Leader,所有写请求都通过Leader路由,数据变更会广播给所有Follower,Follower与Leader保持数据同步。如果Leader失效,则从Follower中选举出一个新的Leader。当Follower与Leader挂掉、卡住或者同步太慢,leader会把这个follower从“in sync replicas”(ISR)列表中删除,重新创建一个Follower
然后我们再来重新看看一次流程:
首先,topic中有很多个类型,Producer(生产者)将消息传入topic中的某一个Partition(类型)当中,消息随着Partition中的Leader(当前的Partition)存储在对应的broker(节点)当中,完成生产者的传入。
然后,Consumer Group中的Consumer(消费者)从broker(节点)中读取所需要的topic或者说其中某一个Partition(类型)中的数据进行消费。
部分术语的联系
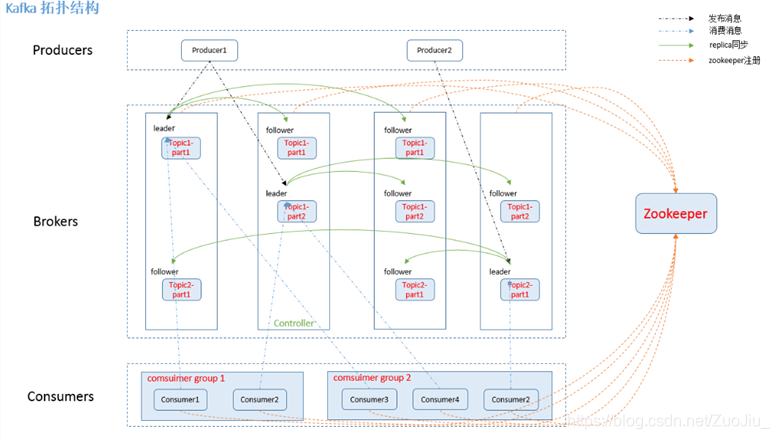
一个典型的Kafka集群中包含若干Producer,若干broker(Kafka支持水平扩展,一般broker数量越多,集群吞吐率越高),若干Consumer Group,以及一个Zookeeper集群。Kafka通过Zookeeper管理集群配置,选举leader,以及在Consumer Group发生变化时进行rebalance。Producer使用push模式将消息发布到broker,Consumer使用pull模式从broker订阅并消费消息。
- Topic和Partition:Topic在逻辑上可以被认为是一个queue,每条消费都必须指定它的Topic,可以简单理解为必须指明把这条消息放进哪个queue里。为了使得Kafka的吞吐率可以线性提高,物理上把Topic分成一个或多个Partition,每个Partition在物理上对应一个文件夹,该文件夹下存储这个Partition的所有消息和索引文件。因为每条消息都被append到该Partition中,属于顺序写磁盘,因此效率非常高。
- Partition的主从:Leader(当前正在使用的Partition),Follower(防止Leader失效的Partition),保证数据在Partition中的正常运行。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









