




一、最小二乘法
最小二乘法(Least Squares Method)是一种数学优化技术,核心思想是通过最小化误差的平方和来找到数据的最佳拟合模型,广泛应用于回归分析、曲线拟合等场景。
核心目标
假设有一批观测数据(比如多个 (x, y) 点),我们希望用一个模型(比如线性函数 y = wx + b)来拟合这些数据。模型的预测值与真实观测值之间会存在误差(残差),最小二乘法的目标是:找到模型参数(如 w 和 b),使得所有误差的平方和最小。
数学表达
假设观测数据为 (x₁, y₁), (x₂, y₂), ..., (xₙ, yₙ),模型的预测值为 ŷᵢ = f(xᵢ; θ)(θ 是模型参数,如 θ = (w, b))。误差(残差)定义为 eᵢ = yᵢ - ŷᵢ(真实值减去预测值)。
最小二乘法的优化目标是:minθ∑i=1nei2=minθ∑i=1n(yi−f(xi;θ))2
为什么用 “平方和”?
- 数学易处理:平方运算使误差函数成为连续可导的凸函数,方便用求导等方法找到最小值(解析解或数值解)。
- 放大较大误差:平方会对较大的误差赋予更大的权重,迫使模型更关注偏离较大的点,减少极端值的影响(相比绝对值误差,平方更 “严厉”)。
- 概率意义:当误差服从正态分布时,最小二乘法等价于最大似然估计(统计学中最合理的估计方法)。
举例:线性回归中的最小二乘法
最经典的应用是线性回归(假设数据符合线性关系 y = wx + b)。此时误差平方和为:∑i=1n(yi−(wxi+b))2
通过对参数 w 和 b 求导并令导数为 0,可直接得到解析解(无需迭代):w=n∑xi2−(∑xi)2n∑xiyi−∑xi∑yi,b=yˉ−wxˉ(其中 \bar{x} 和 \bar{y} 是 x 和 y 的平均值)。
线性回归是 “用直线(或高维超平面)拟合数据的回归任务”,最小二乘法是 “找到这条直线(或超平面)最优参数的核心数学方法”—— 前者是要解决的问题,后者是解决问题的关键工具。
总结
最小二乘法是一种 “让模型尽可能贴近数据” 的优化方法,通过最小化误差平方和求解最优参数。它的优势是简单、可解释性强,且在很多场景下(如线性模型)能直接得到解析解,是数据分析和机器学习的基础工具之一。
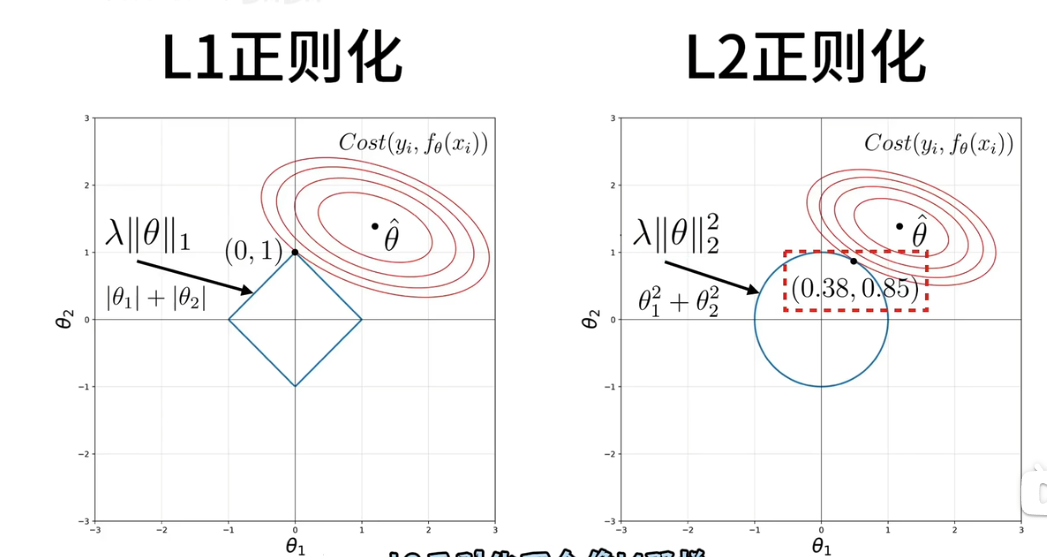
二、L1/L2正则化
L1 正则化和 L2 正则化是机器学习中常用的正则化技术,用于防止模型过拟合(即模型在训练数据上表现过好,但泛化到新数据时性能下降)。它们的核心思想是通过在损失函数中添加额外的 “惩罚项”,限制模型参数的大小,从而简化模型。

1. 损失函数的基本形式
在未添加正则化时,模型的训练目标是最小化预测误差(损失函数),例如均方误差(MSE)或交叉熵损失。添加正则化后,损失函数变为:总损失 = 预测误差 + 正则化惩罚项
2. L1 正则化(L1 Regularization)
- 惩罚项形式:对模型参数的绝对值求和,再乘以正则化系数 λ(λ≥0,控制惩罚强度)。公式:
L1惩罚项 = λ * Σ|w_i|(其中 w_i 是模型的参数,如权重)。 - 作用:
- 会使部分参数变为 0(“稀疏化” 参数),相当于自动选择重要特征,实现特征选择的效果。
- 例如,在线性回归中,L1 正则化对应的模型称为 “Lasso 回归”。
- 直观理解:L1 惩罚项在参数空间中形成 “菱形” 约束区域,与损失函数的等高线相交时,更容易落在坐标轴上(参数为 0)。
3. L2 正则化(L2 Regularization)
- 惩罚项形式:对模型参数的平方求和,再乘以 λ/2(除以 2 是为了求导后简化计算)。公式:
L2惩罚项 = (λ/2) * Σ(w_i²)。 - 作用:
- 会使参数值整体变小(但不会为 0),让模型更 “平滑”,减少过拟合风险。
- 例如,在线性回归中,L2 正则化对应的模型称为 “Ridge 回归”(岭回归)。
- 直观理解:L2 惩罚项在参数空间中形成 “圆形” 约束区域,与损失函数的等高线相交时,参数更可能落在靠近原点的区域(值较小)。
4. 核心区别
| 特性 | L1 正则化 | L2 正则化 |
|---|---|---|
| 参数影响 | 使部分参数为 0(稀疏性) | 使参数值整体缩小(不稀疏) |
| 特征选择 | 自动实现特征选择 | 不具备特征选择能力 |
| 计算效率 | 惩罚项不可导(需特殊优化) | 惩罚项可导(优化更简单) |
| 适用场景 | 特征维度高、需降维时 | 避免参数过大导致过拟合 |
5. 总结
- 两者均通过惩罚参数大小降低模型复杂度,缓解过拟合。
- L1 适合需要简化模型、筛选关键特征的场景(如高维数据)。
- L2 适合希望参数平滑分布、避免极端值的场景,且计算更稳定。
- 实际应用中,还可结合两者(如 Elastic Net),兼顾稀疏性和平滑性。
6.补充
问:这个约束条件不是固定的啊 我加正则项的损失函数 是要同时处理 原始损失函数和 正则化项的问题 而不是给定一个固定的范围去限制 |w1| + |w2| > C这个C的大小 他是动态变化的 我认为要是给定了这个C的值 那么最优解一定是交点 但是这个C是没有给定的 所以我对这个结论表示怀疑
答:
两种视角的本质是 “同一问题的不同表述”
带正则化的损失函数(无约束优化):min_w [ Loss(w) + λ·L1(w) ]
等价于约束优化问题(对任意 λ,存在唯一 C 与之对应):min_w Loss(w) s.t. L1(w) ≤ C
这里的关键是:C 不是预先给定的固定值,而是由 λ 和优化结果共同决定的动态值。具体来说,当我们求解无约束优化时,最优解 w * 会自动满足:
- 若 λ=0,则 C→∞(约束消失),w * 就是无正则化的最优解;
- 若 λ>0,w会使得 “Loss 的下降” 与 “惩罚项的上升” 达到平衡,此时对应的 C 就是 L1 (w)(即最优解恰好落在约束边界上,L1 (w*)=C)。
三、常见的分类与回归损失总结:
一、分类任务常用损失函数
分类任务的核心是让模型输出的 “类别概率 / 得分” 与真实标签一致,损失越小,分类准确性越高。
1. 交叉熵损失(Cross-Entropy Loss)
- 核心逻辑:衡量 “模型预测的概率分布” 与 “真实标签的概率分布” 的差异,差异越小,损失越小。是分类任务的 “通用损失”。
- 公式:
- 二分类(真实标签 y∈{0,1},预测正类概率 y^∈[0,1]):L=−N1∑i=1N[yilny^i+(1−yi)ln(1−y^i)]
- 多分类(真实标签为独热向量 yi∈{0,1}C,C 为类别数,预测概率 y^i,c):L=−N1∑i=1N∑c=1Cyi,clny^i,c
- 适用场景:几乎所有分类任务(如图像分类、文本分类),需搭配 Sigmoid(二分类)、Softmax(多分类)激活函数输出概率。
- 特点:对 “预测与真实偏差大” 的样本惩罚更严厉,梯度更新高效,是工业界最常用的分类损失。
2. 铰链损失(Hinge Loss)
- 核心逻辑:为支持向量机(SVM)设计,目标是让 “正确类别得分” 比 “错误类别得分” 高至少一个 “间隔(Margin)”,间隔内样本无损失(模型对分类有足够信心)。
- 公式:
- 二分类(真实标签 y∈{−1,1},模型预测得分 s=w⋅x+b):L=N1∑i=1Nmax(0,1−yisi)
- 多分类(正确类别得分 si,c,错误类别得分 si,k):L=N1∑i=1N∑k=cmax(0,si,k−si,c+1)
- 适用场景:支持向量机(SVM)、需 “分类边界鲁棒性” 的任务(如高维数据分类)。
- 特点:仅惩罚 “分类错误” 或 “间隔不足” 的样本,易得到稀疏解(仅关注支持向量),对噪声数据有一定抗干扰能力。
3. Focal Loss(焦点损失)
- 核心逻辑:解决 “类别不平衡” 问题(如正负样本 1:1000),通过降低 “易分类样本权重”,让模型优先学习 “难分类样本”(少数类、边界样本)。
- 公式(基于交叉熵改进,二分类为例):L=−N1∑i=1Nαyi(1−y^i)γlny^i
- α:平衡类别权重(少数类 α 大,多数类 α 小);
- γ:调节难样本权重(γ>0,易分类样本权重降低)。
- 适用场景:类别不平衡任务(如目标检测小目标识别、医学影像罕见病诊断)。
- 特点:避免传统交叉熵被多数类样本 “主导”,显著提升少数类样本的分类性能。
二、回归任务常用损失函数
回归任务的核心是让模型预测的 “连续数值” 与真实值接近,损失越小,数值预测越精准。
1. 均方误差(Mean Squared Error, MSE)
- 核心逻辑:计算 “预测值与真实值的平方差平均值”,通过平方放大极端误差,迫使模型优先降低大偏差。
- 公式:L=N1∑i=1N(y^i−yi)2(常加 1/2 简化求导,即 L=2N1∑(y^i−yi)2,本质一致)
- 适用场景:无异常值的回归任务(如房价预测、温度预测、销量预测)。
- 特点:数学性质好(连续可导、凸函数,易优化),但对异常值敏感(极端误差会大幅拉高总损失)。
2. 平均绝对误差(Mean Absolute Error, MAE)
- 核心逻辑:计算 “预测值与真实值的绝对差平均值”,对误差的惩罚是线性的,不放大异常值影响,更稳健。
- 公式:L=N1∑i=1N∣y^i−yi∣
- 适用场景:数据含较多异常值的回归任务(如股价预测、客流量预测,常出现突发波动)。
- 特点:对异常值稳健,但在预测值 = 真实值处不可导(需用次梯度优化,如 XGBoost、LightGBM 的处理方式)。
3. Huber 损失
- 核心逻辑:结合 MSE 和 MAE 的优点 ——“误差小时用 MSE(可导、优化快),误差大时用 MAE(抗异常值)”,通过阈值 δ 区分误差大小。
- 公式:$$$L = \frac{1}{N}\sum_{i=1}^N \begin{cases}\frac{1}{2}(\hat{y}_i - y_i)^2 & |\hat{y}_i - y_i| \leq \delta \\delta(|\hat{y}_i - y_i| - \frac{1}{2}\delta) & |\hat{y}_i - y_i| > \delta\end{cases} $$$$$
- 适用场景:需平衡 “优化效率” 和 “抗异常值” 的任务(如工业设备故障预测,数据含少量传感器噪声)。
- 特点:兼顾 MSE 的易优化性和 MAE 的稳健性,是工业界处理 “轻度异常值” 的常用选择。
4. 分位数损失(Quantile Loss)
- 核心逻辑:用于 “分位数回归”,目标是预测真实值的某一分位数(如中位数、90% 分位数),而非均值,可量化预测不确定性。
- 公式(预测分位数 τ,如 τ=0.5 对应中位数):$$$L = \frac{1}{N}\sum_{i=1}^N \begin{cases}\tau (\hat{y}_i - y_i) & \hat{y}_i \geq y_i \(1 - \tau)(y_i - \hat{y}_i) & \hat{y}_i < y_i\end{cases} $$$$$
- 适用场景:需 “区间预测” 的任务(如物流时效预测 “95% 订单 3 天内送达”、金融风险预测 “最坏损失”)。
- 特点:可通过不同 τ 构建预测区间(如 τ=0.1 和 τ=0.9 得到 10%-90% 区间),直接量化预测的不确定性。
三、分类与回归损失核心对比表
| 任务类型 | 损失函数 | 核心优势 | 适用场景 |
|---|---|---|---|
| 分类 | 交叉熵损失 | 通用、惩罚偏差大的样本、梯度高效 | 图像 / 文本分类、需概率输出的场景 |
| 分类 | 铰链损失 | 最大化分类间隔、抗噪声 | SVM、高维数据分类 |
| 分类 | Focal Loss | 解决类别不平衡、聚焦难分类样本 | 小目标检测、罕见病诊断 |
| 回归 | MSE | 易优化、凸函数 | 无异常值的回归(房价 / 温度预测) |
| 回归 | MAE | 抗异常值、稳健 | 含异常值的回归(股价 / 客流量预测) |
| 回归 | Huber 损失 | 平衡优化效率与抗异常值 | 轻度异常值的工业预测 |
| 回归 | 分位数损失 | 预测分位数、量化不确定性 | 物流时效 / 金融风险的区间预测 |
四、最大似然估计
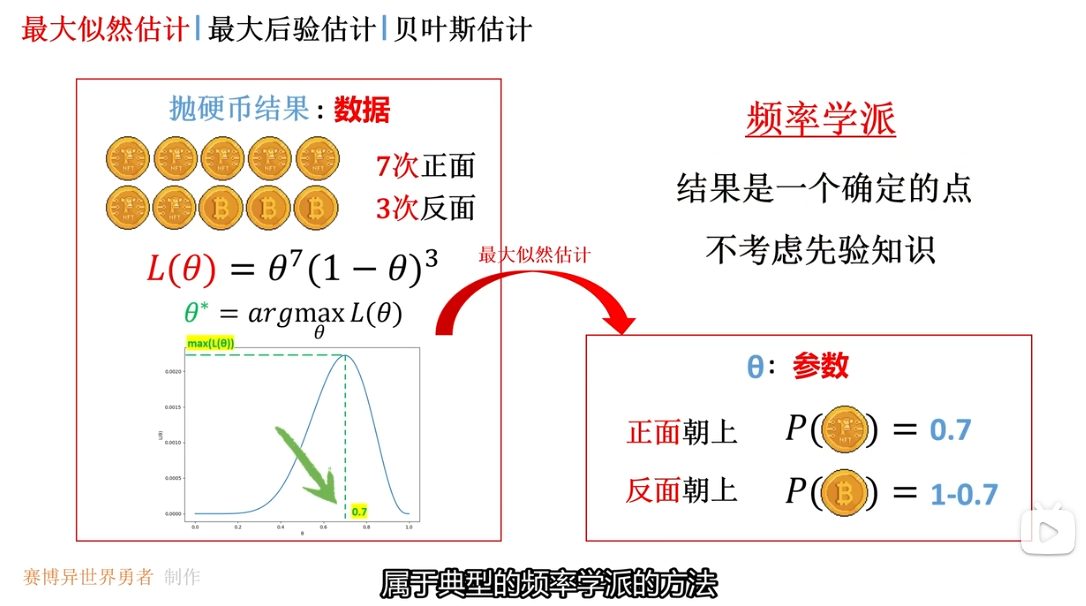
最大似然估计(Maximum Likelihood Estimation, MLE)是统计学中最常用的参数估计方法之一,核心思想非常朴素:找到一组参数,使得 “当前观测到的这组数据恰好出现” 的概率最大。它认为参数是 “固定但未知的”,目标是通过已有的数据,反推最可能生成这组数据的参数值。
一、用生活例子理解:从结果反推 “最可能的原因”
我们先抛开公式,用一个简单场景理解其逻辑:假设你抛了 10 次硬币,结果是 7 次正面、3 次反面(这是 “观测数据”)。现在要估计这枚硬币抛出正面的概率p(这是 “待估参数”)。
- 直觉上,你会觉得 “正面概率p=0.7” 最合理 —— 因为如果p=0.7,抛出 7 正 3 反的概率比p=0.5(公平硬币)或p=0.3(反面倾向)都要大。
- 这个 “找最可能参数” 的过程,就是最大似然估计的核心逻辑:数据已经发生,我们找让这组数据发生概率最大的参数。
二、数学逻辑:从 “似然函数” 到 “最大化”
MLE 的数学实现分两步:定义 “似然函数”,再通过最大化似然函数找到最优参数。
1. 关键概念:似然函数(Likelihood Function)
似然函数是 MLE 的核心,它描述 “在给定参数θ的情况下,观测到当前数据X的概率”,记为L(θ∣X)。
- 注意区分 “似然” 和 “概率”:
- 概率:已知参数θ,预测数据X发生的可能性(如已知硬币p=0.5,求抛 10 次得 5 正的概率);
- 似然:已知数据X,反推参数θ的可能性(如已知抛 10 次得 7 正,求p=0.7的可能性)。
对于独立同分布的样本(如每次抛硬币独立),似然函数是每个样本概率的乘积:L(θ∣X)=∏i=1nP(Xi∣θ)其中n是样本数,P(Xi∣θ)是单个样本Xi在参数θ下的概率(如抛硬币单次得正面的概率p)。
2. 最大化似然函数:找到最优参数θ^MLE
直接最大化乘积形式的似然函数计算复杂(易出现数值下溢),因此通常对似然函数取自然对数,将乘积转为求和(对数是单调递增函数,最大化对数似然等价于最大化原似然),得到 “对数似然函数”:lnL(θ∣X)=∑i=1nlnP(Xi∣θ)
之后通过 “求导找极值” 的方式,找到使对数似然函数最大的参数θ^MLE:
- 对对数似然函数lnL(θ∣X)关于参数θ求导;
- 令导数等于 0,解方程组得到参数的估计值θ^MLE。
三、实战案例:抛硬币问题的 MLE 计算
回到 “10 次抛硬币得 7 正 3 反” 的案例,具体计算正面概率p的 MLE 估计值:
1. 定义似然函数
抛硬币单次结果服从伯努利分布,单次得正面的概率为p,得反面为1−p。10 次观测中,7 次正面、3 次反面的似然函数为:L(p∣X)=P(7正3反∣p)=(710)p7(1−p)3其中(710)是组合数(从 10 次中选 7 次正面的方式数),与p无关,最大化时可忽略。
2. 取对数似然
对似然函数取自然对数,简化计算:lnL(p∣X)=ln(710)+7lnp+3ln(1−p)
3. 求导找极值
对lnL(p∣X)关于p求导,并令导数为 0:dpdlnL(p∣X)=p7−1−p3=0
解这个方程:p7=1−p3⟹7(1−p)=3p⟹7−7p=3p⟹p=0.7
最终得到p^MLE=0.7,与直觉一致 —— 这就是 “最可能生成 7 正 3 反数据的正面概率”。
四、MLE 的核心特点
- 无需先验知识:仅依赖观测数据,不需要提前假设参数的分布(与贝叶斯估计的核心区别);
- 大样本性质好:当样本量足够大时,MLE 估计值会 “趋近于” 参数的真实值(满足 “一致性”),且估计精度高;
- 适用范围广:可用于任何已知概率分布的参数估计(如正态分布的均值和方差、二项分布的成功概率、泊松分布的率参数等);
- 小样本可能有偏差:样本量较小时,MLE 可能出现极端估计(如抛 1 次得正面,MLE 会估计p=1,显然不符合实际),此时需结合先验知识修正(如用贝叶斯估计)。
总结
最大似然估计的本质是 “从结果反推最可能的原因”:已知数据已经发生,通过构建似然函数描述 “参数生成数据的可能性”,再通过最大化似然函数找到最优参数。它是统计学和机器学习的基础工具,从简单的抛硬币概率估计,到复杂的神经网络参数优化(如逻辑回归的参数估计),都能看到 MLE 的身影。
要不要我再用 “正态分布均值的 MLE 估计” 案例做补充?比如已知一组数据服从正态分布,如何通过 MLE 推导均值的估计值,进一步巩固对似然函数和最大化过程的理解。
五、贝叶斯公式和贝叶斯估计
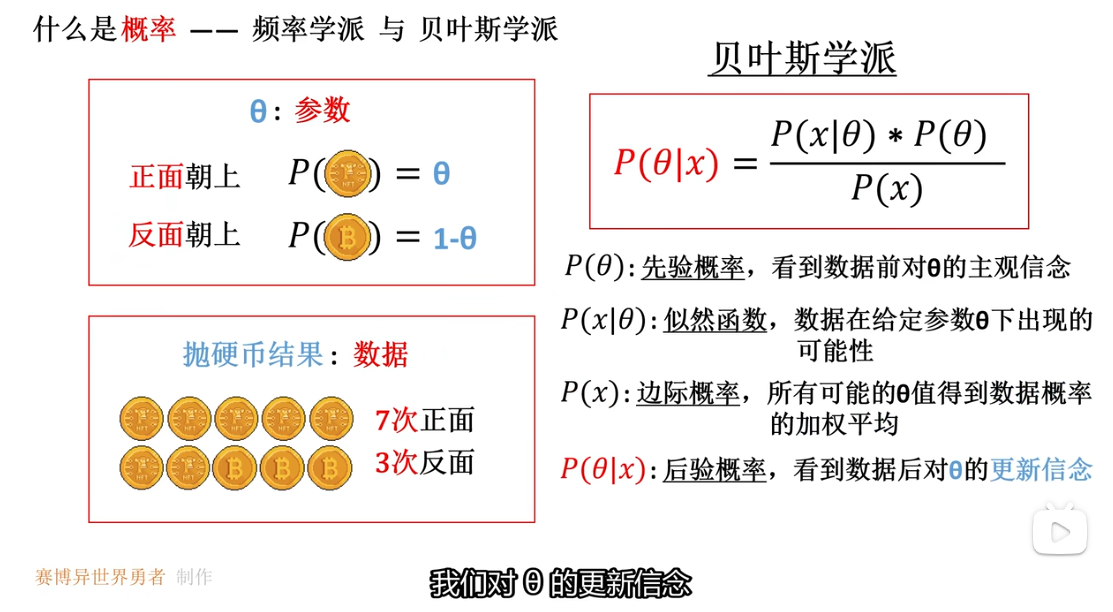
贝叶斯公式是贝叶斯学派进行推断的核心工具 其核心思想是通过已有的知识和新获得的证据来推断某个参数取值或事件发生的可能性

对比频率学派和贝叶斯学派:
1、频率学派要逼近真实数值需要大量的样本数据 然而面对无法获取足够样本数据的场景 频率学派难以获取较好的结果 而贝叶斯学派可以通过整合先验医学知识和检测结果更准确 可解释的做出更稳健的不确定性的预测 而不是被样本波动牵着走
2、不确定性建模 贝叶斯学派有着天然的优势 会多次采样 得到期望值和方差
3、贝叶斯学派可以逐步更新新知识 ———— 贝叶斯学派天然支持 先验-后验-先验 的递归更新机制 适合信息逐步积累 及时调整信念的场景 频率学派则更多依赖固定样本和批量估计 不易实现连续更新
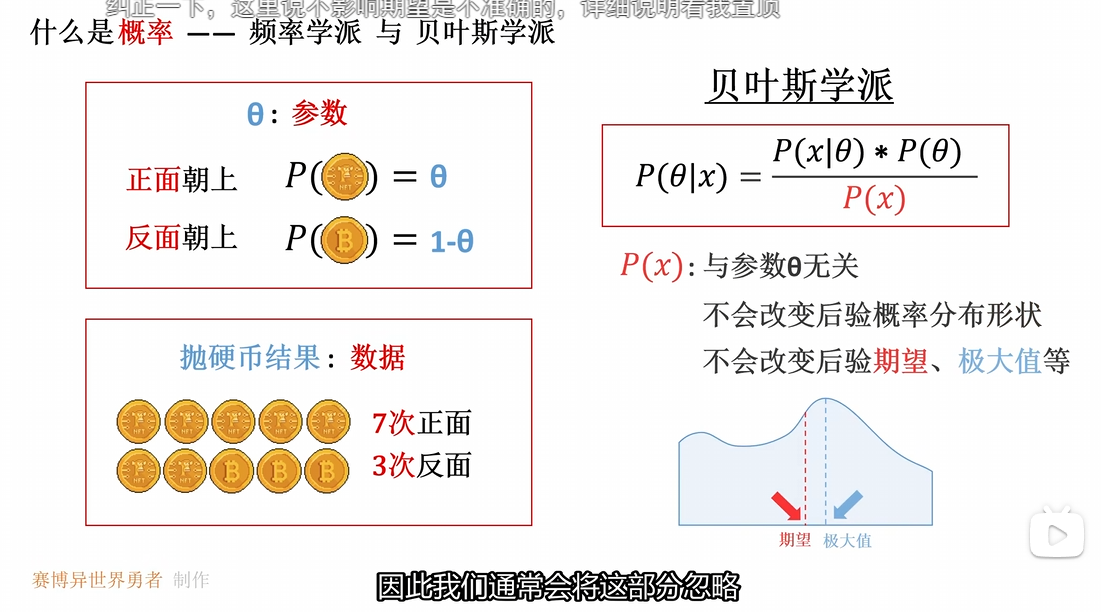
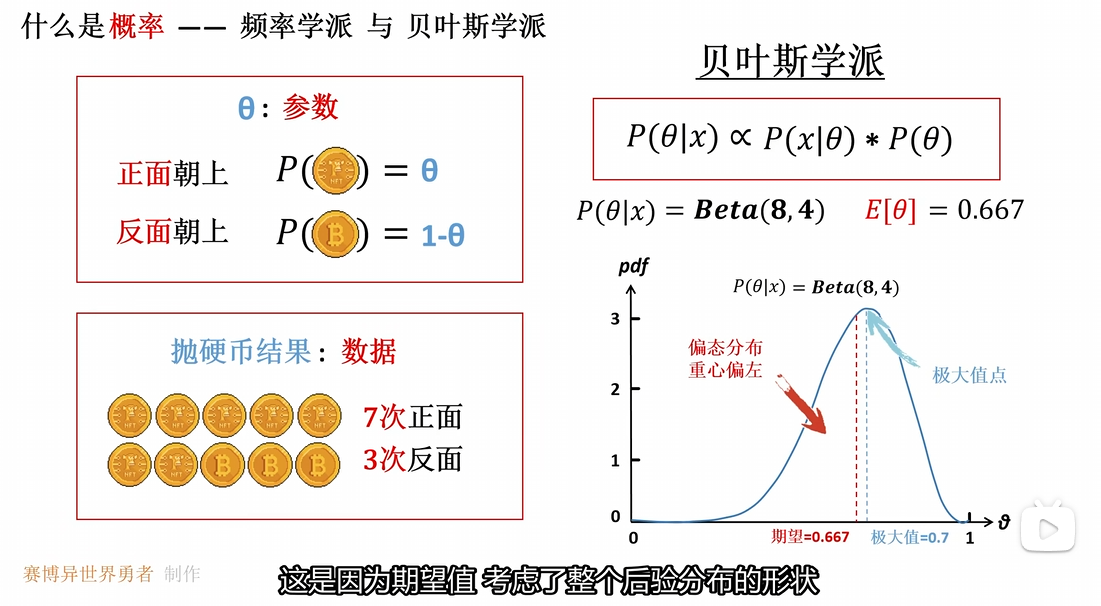
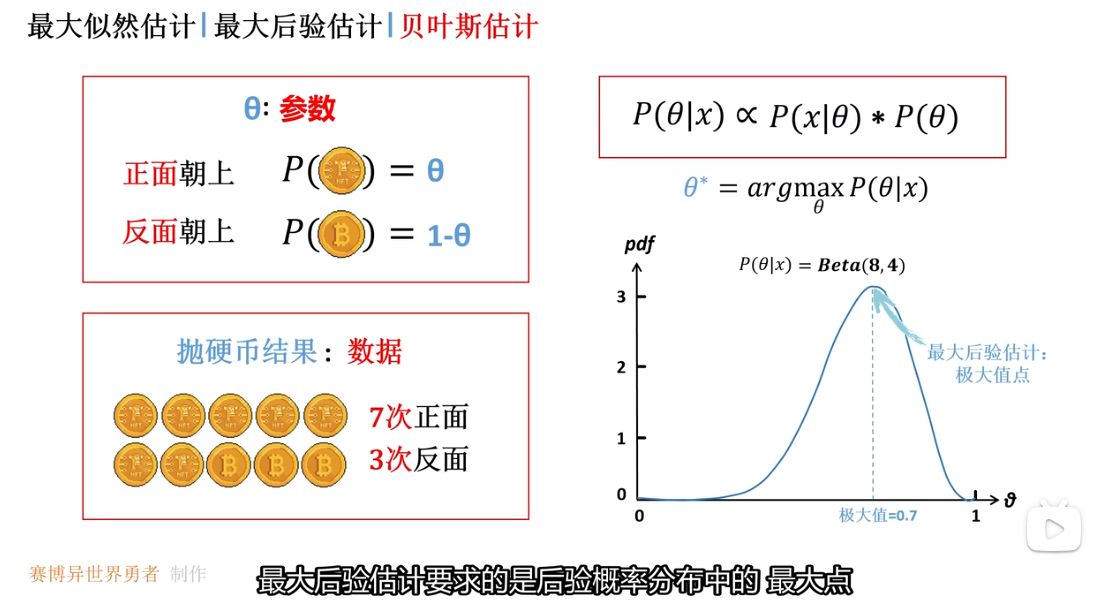
贝叶斯估计并没有取到后验概率分布的最大值数 而是使用了期望值 这是因为期望值考虑了整个后验分布的形状 当前后验分布是一个偏态分布 最大值点偏向边缘 因此使用期望值可以更好地表征后验概率分布
如何理解贝叶斯估计 对于Θ的取值可以有非常多
对比 最大似然估计 最大后验估计 贝叶斯估计
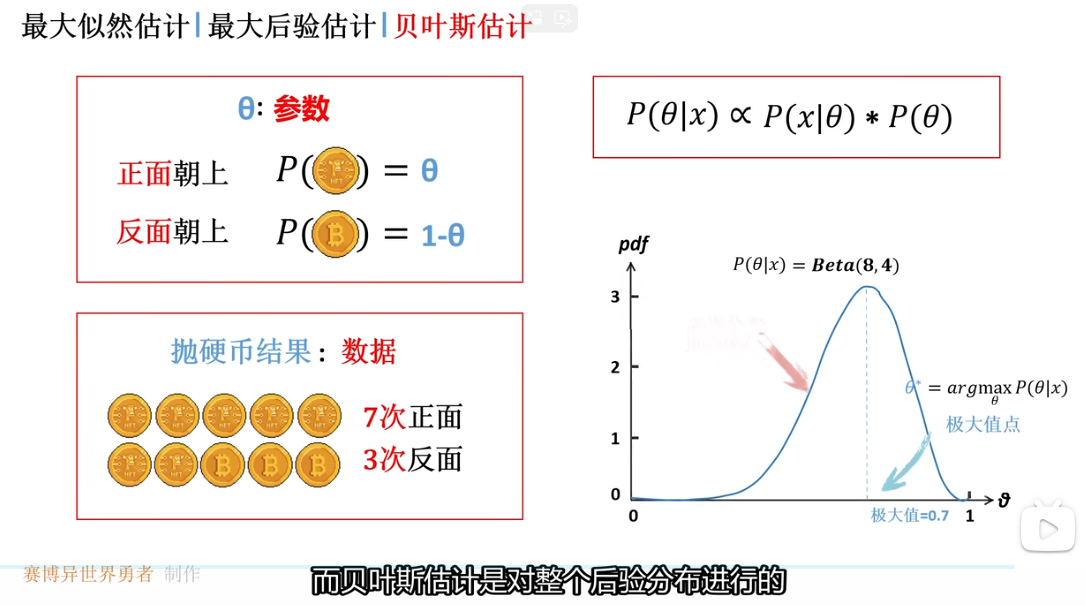
不确定性评估 其通过期望、方差等数值对后验分布进行量化
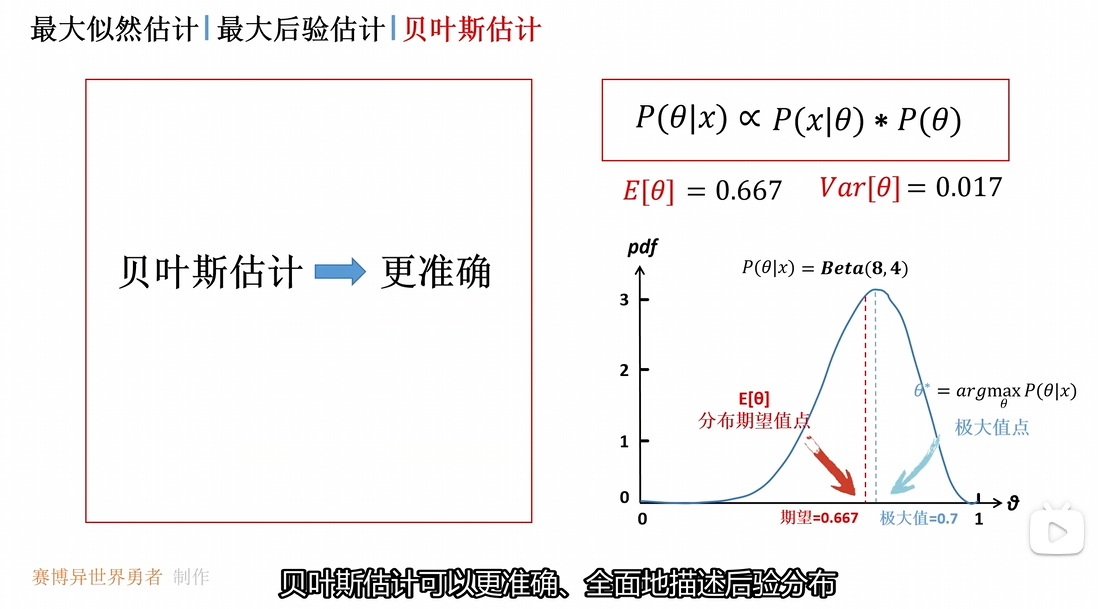
贝叶斯估计需要求得后验概率分布的均值 因此会涉及到后验概率分布的积分运算 计算较为困难
因此在工程上使用最大后验估计的可行性更高 将最大后验估计看作是 近似贝叶斯估计的实用方案 使用后验分布的极大值点 替换贝叶斯估计中的期望值 并且可以通过梯度下降更方便的进行求解
六、交叉熵损失
信息量:衡量的是系统中单个事件的不确定性
信息熵:衡量的是整个系统的不确定性 整个系统的平均信息量是信息熵 是系统所有事件信息量的期望
交叉熵:在真实分布为P的情况下 用预测编码Q编码数据时 所需要的平均学习量
也就是使用预测分布 Q 表达真实分布 P 时 要花费的总比特数

1、根据吉布斯不等式 H(P,Q)≥H(P) 当且仅当 P = Q 时 等号成立 此时使用Q编码P的损失为0
2、P与Q差异越大 H(P,Q)越大 使用Q近似P的信息损失越多

KL散度:交叉熵关注的是实际代价 其编码成本来源于两个方面 第一个是真实分布P自身的内在不确定性(就是信息熵)第二个是源于模型Q与真实P之间的差异 这部分才是模型预测 偏离真实分布而产生的 额外的编码代价 KL散度就是交叉熵 排除掉真实分布P自身的信息熵 得到的仅表征预测模型分布Q和真实分布P之间差异的结果

因为交叉熵与KL散度只相差了一个真实分布的信息熵(常数) 所以最小化交叉熵就等价于最小化两个分布之间的KL散度
7、Canny边缘匹配的步骤
Canny 边缘检测是一种经典的边缘检测算法,以 “低错误率、高定位精度、单边缘响应” 为设计目标,能在去除噪声的同时,提取出清晰、连续的边缘。其完整流程分为5 个核心步骤,每个步骤环环相扣,最终从原始图像得到精准的边缘结果。
步骤 1:高斯滤波(去噪声)
目的:边缘检测对噪声非常敏感(噪声会被误判为边缘),高斯滤波的作用是平滑图像,削弱高频噪声(如椒盐噪声、随机斑点),为后续梯度计算提供更稳定的输入。
具体操作:
- 用一个高斯核(Gaussian Kernel) 与原始图像做卷积运算。高斯核是一个对称的矩阵,中心像素权重最高,向四周逐渐降低(符合 “越近的像素影响越大” 的规律)。
- 常见的高斯核大小为 3×3、5×5 等,例如 3×3 的高斯核(σ 为标准差,控制平滑程度,σ 越大平滑越强):
plaintext
[1 2 1] [2 4 2] * (1/16) (归一化系数,保证卷积后像素值范围不变) [1 2 1] - 卷积后,图像中的尖锐噪声被模糊,而真实边缘(变化较缓慢的区域)得以保留。
步骤 2:计算梯度(获取边缘强度与方向)
目的:边缘本质是图像中像素值突变的区域(如明暗交界处),梯度能量化这种 “突变程度”—— 梯度越大,说明该区域越可能是边缘。同时,梯度方向能指示边缘的走向(如水平、垂直)。
具体操作:
-
计算水平和垂直方向梯度:用 Sobel 算子(一种离散微分算子)分别计算图像在水平方向(Gx)和垂直方向(Gy)的梯度。
- 水平 Sobel 算子(检测垂直边缘):
plaintext
[-1 0 1] [-2 0 2] [-1 0 1] - 垂直 Sobel 算子(检测水平边缘):
plaintext
[-1 -2 -1] [0 0 0] [1 2 1]
对图像每个像素,用两个算子做卷积,得到 Gx(水平方向梯度值)和 Gy(垂直方向梯度值)。
- 水平 Sobel 算子(检测垂直边缘):
-
计算梯度强度(幅值):每个像素的梯度强度是 Gx 和 Gy 的 “合强度”,公式为:
梯度强度 M = sqrt(Gx² + Gy²)(为简化计算,也常用近似值M = |Gx| + |Gy|,精度略低但速度快)。梯度强度越高,该像素越可能是边缘点。 -
计算梯度方向:梯度方向是边缘的 “法线方向”(垂直于边缘走向),公式为:
梯度方向 θ = arctan(Gy / Gx)为简化后续处理,通常将 θ 归为 4 个方向之一(0°、45°、90°、135°),分别对应水平、对角线、垂直、反对角线方向的边缘。
步骤 3:非极大值抑制(NMS,细化边缘)
目的:经过梯度计算得到的边缘往往是 “宽边缘”(多个相邻像素都有较高梯度),NMS 的作用是将宽边缘细化为 “单像素宽度” 的边缘,精确定位边缘的中心位置。
具体操作:对每个像素,根据其梯度方向,比较它与 “梯度方向上相邻像素” 的梯度强度,只保留 “局部最大值”:
-
对当前像素(x,y),根据其梯度方向 θ,确定两个 “对比邻域像素”(沿梯度方向的前后像素):
- 若 θ≈0°(水平梯度,边缘垂直走向):对比左(x-1,y)和右(x+1,y)像素;
- 若 θ≈90°(垂直梯度,边缘水平走向):对比上(x,y-1)和下(x,y+1)像素;
- 若 θ≈45°:对比左上(x-1,y-1)和右下(x+1,y+1)像素;
- 若 θ≈135°:对比右上(x+1,y-1)和左下(x-1,y+1)像素。
-
比较当前像素与两个邻域像素的梯度强度:
- 若当前像素的梯度强度 大于两个邻域像素 → 保留(是边缘中心);
- 否则 → 抑制(置梯度强度为 0,不是边缘中心)。
经过 NMS 后,宽边缘被 “瘦身” 为单像素线条,边缘定位更精准。
注意:
但 Canny 算法中 NMS 的处理顺序不会影响最终结果—— 核心原因是 NMS 的 “抑制规则” 是 “基于局部梯度强度的客观比较”,而非 “处理顺序的主观优先级”,每个像素是否被抑制,只取决于它与 “梯度方向邻域像素” 的强度关系,与处理先后无关。
一、先明确 Canny 中 NMS 的 “抑制逻辑”:不是 “主动抑制邻域”,而是 “判断自身是否为局部最大值”
很多人会误解 NMS 是 “先处理的像素主动把邻域像素置 0”,但实际 Canny 的 NMS 是对每个像素独立做 “资格判断”,流程是这样的:
- 提前保存 “完整的梯度强度图和梯度方向图”(这两张图在 NMS 过程中完全不变,不会被实时修改);
- 遍历所有像素(顺序可以是从左到右、从上到下,或任意顺序);
- 对当前遍历到的像素 P:
- 根据梯度方向找到它的两个对比邻域像素 Q1、Q2(从 “固定不变的梯度图” 中读取 Q1、Q2 的强度);
- 比较 P 的强度与 Q1、Q2 的强度:若 P 是三者中的最大值,则保留 P 的强度;否则,将 P 的强度临时标记为 0(不修改原始梯度图,只生成新的 “NMS 后梯度图”);
- 所有像素遍历完成后,新生成的 “NMS 后梯度图” 就是最终结果。
二、为什么处理顺序不影响结果?因为 “原始梯度信息是固定的”
关键在于:NMS 过程中,所有像素的 “原始梯度强度” 都是预先确定且不被修改的。无论先处理哪个像素,判断时用到的 “邻域像素强度” 都是 “原始值”,而非 “被前序像素修改后的值”—— 这和目标检测中 “先处理高概率框、再删除重叠框” 的 NMS(会实时修改候选框列表)完全不同。
Canny 的 NMS 是 “基于固定信息的独立判断”,与顺序无关
Canny 的 NMS 和目标检测的 NMS 有本质区别:
- 目标检测 NMS:实时修改候选集(删除重叠框),处理顺序(按概率降序)会影响结果(先保留高概率框,再删低概率重叠框);
- Canny 的 NMS:不修改原始梯度信息,每个像素的判断都是 “基于原始强度的独立比较”,处理顺序只是 “遍历顺序”,不改变 “谁强谁弱” 的客观事实,因此最终结果完全一致。
这也是 Canny 算法能保证 “结果稳定性” 的重要设计 —— 无论遍历顺序如何,最终得到的 “单像素边缘” 都是唯一且精准的。
步骤 4:双阈值检测(区分强 / 弱边缘)
目的:通过两个阈值(高阈值 H、低阈值 L,通常 H=2×L),将边缘像素分为 “强边缘”“弱边缘” 和 “非边缘”,初步筛选出可靠的边缘候选。
具体操作:
- 梯度强度 > H → 强边缘(Strong Edge):确定为边缘,可靠性高;
- 梯度强度 < L → 非边缘:直接排除;
- L ≤ 梯度强度 ≤ H → 弱边缘(Weak Edge):可能是边缘(受噪声影响),也可能不是,需进一步验证。
阈值的选择需根据图像特点调整:H 过高会漏检边缘,H 过低会保留过多噪声。
步骤 5:边缘连接(滞后阈值,合并弱边缘)
目的:弱边缘可能是真实边缘的一部分(如被噪声干扰的边缘延伸部分),也可能是噪声。通过 “滞后阈值” 规则,只保留与强边缘相连的弱边缘,剔除孤立的弱边缘(噪声),最终形成完整的边缘。
具体操作:
- 所有强边缘直接保留,作为 “种子边缘”;
- 遍历所有弱边缘,判断其是否与强边缘 “连通”(即存在相邻的强边缘像素):
- 若连通 → 视为真实边缘的一部分,保留;
- 若孤立(周围无强边缘) → 视为噪声,剔除;
- 最终保留的强边缘 + 连通的弱边缘,构成完整的 Canny 边缘结果。
总结:Canny 边缘检测的核心逻辑
从 “去噪声” 到 “精准边缘”,5 个步骤层层递进:
- 高斯滤波 → 消除噪声干扰;
- 梯度计算 → 定位可能的边缘区域;
- NMS → 细化边缘为单像素宽度;
- 双阈值 → 初步筛选可靠边缘;
- 边缘连接 → 合并完整边缘,剔除孤立噪声。
最终输出的边缘图像具有 “定位准、无冗余、连续性好” 的特点,是后续图像分割、目标识别等任务的重要预处理步骤。
8、NMS算法
非极大值抑制(NMS)的核心目的是 “去除冗余、保留最优”,通过筛选同一目标区域内响应最强的候选(如边缘点、目标检测框),消除重复或次要信息,最终得到精准且唯一的结果。不同场景(如边缘检测、目标检测)的 NMS 步骤略有差异,下面先从最基础的Canny 边缘检测中的 NMS讲起,再延伸到更常用的目标检测 NMS,帮你彻底理解。
一、Canny 边缘检测中的 NMS:精准定位边缘
Canny 中的 NMS 作用是 “将模糊的梯度边缘细化为单像素宽度的清晰边缘”,步骤围绕 “梯度方向” 和 “梯度强度对比” 展开,共 3 步:
1. 准备基础数据:梯度强度图 + 梯度方向图
- 先通过 Sobel 算子计算图像每个像素的梯度强度(反映该点是否为边缘的 “可能性”,值越大越可能是边缘)和梯度方向(反映边缘的 “走向”,如水平、垂直、45°、135°,通常简化为这 4 个方向)。
- 得到两张图:
梯度强度图(每个像素存强度值)、梯度方向图(每个像素存所属方向)。
2. 确定 “对比邻域”:沿梯度方向找 2 个对比像素
梯度方向决定了 “边缘的延伸方向”,因此需要沿梯度方向的正、反两个方向,找当前像素的 “相邻像素”(即可能与当前像素竞争 “边缘资格” 的候选),规则如下:
| 梯度方向 | 对比邻域(当前像素的哪个邻居) |
|---|---|
| 水平(0°) | 左侧像素、右侧像素 |
| 垂直(90°) | 上方像素、下方像素 |
| 45° | 左上像素、右下像素 |
| 135° | 右上像素、左下像素 |
- 例:若当前像素梯度方向是 45°,则需对比它 “左上” 和 “右下” 两个像素的梯度强度。
3. 非极大值抑制:保留局部最大值,抑制其他像素
对每个像素执行判断:
- 若当前像素的梯度强度 大于 其 “对比邻域” 两个像素的梯度强度 → 说明当前像素是该边缘方向上的 “局部最强响应”,保留其梯度强度(视为有效边缘点)。
- 若当前像素的梯度强度 小于或等于 任意一个邻域像素的强度 → 说明当前像素不是 “最强响应”,将其梯度强度置为 0(抑制,视为非边缘点)。
最终,模糊的宽边缘会被细化成 “单像素宽度” 的清晰边缘,为后续双阈值检测做准备。
二、目标检测中的 NMS:去除重复检测框
目标检测(如 YOLO、Faster R-CNN)中,模型会输出大量 “目标检测框”(每个框包含 “类别概率” 和 “位置坐标”),但同一目标可能被多个框重复检测,NMS 的作用是 “保留每个目标的最优检测框,删除重复框”,步骤共 4 步:
1. 筛选初始候选框:按类别概率过滤
- 先设定一个 “概率阈值”(如 0.5),删除所有 “类别概率 < 阈值” 的检测框 —— 这些框大概率是误检,无需后续处理。
- 剩下的框作为 “候选框”,按 “类别概率” 从高到低排序(概率越高,框越可能是正确检测)。
2. 计算 IoU:衡量两个框的重叠程度
IoU(Intersection over Union,交并比)是判断两个检测框是否 “重复” 的核心指标,计算公式为:IoU = 两个框的交集面积 / 两个框的并集面积
- IoU 范围在 0~1 之间:IoU 越接近 1,说明两个框重叠越多(越可能是同一目标);IoU 接近 0,说明几乎无重叠(不同目标)。
3. 迭代执行抑制:保留最优,删除重叠
按 “类别概率降序” 遍历候选框,每轮处理 1 个 “当前最优框”(概率最高的框),步骤如下:
- 取出当前概率最高的框 A,加入 “最终结果列表”(确定这是一个有效框)。
- 计算框 A 与剩余所有候选框(如 B、C、D...)的 IoU。
- 删除所有 “与 A 的 IoU> IoU 阈值”(如 0.3~0.5)的候选框(这些框与 A 重叠过多,视为重复框)。
- 从剩余候选框中,再取概率最高的框作为新的 “框 A”,重复步骤 1~3,直到所有候选框都被处理(要么加入结果,要么被删除)。
4. 输出最终结果:每个目标对应 1 个最优框
最终 “结果列表” 中的检测框,就是每个目标的唯一、最优检测框,无重复且精度最高。
三、NMS 的核心逻辑总结
无论是边缘检测还是目标检测,NMS 的本质逻辑都是 “局部竞争、优中选优”:
- 先定义 “局部范围”(边缘检测的 “梯度方向邻域”、目标检测的 “重叠框范围”);
- 再设定 “竞争规则”(边缘检测比 “梯度强度”、目标检测比 “类别概率 + IoU”);
- 最后保留 “局部最优”,抑制 “次要冗余”,得到更精准、更简洁的结果。
要不要我帮你整理一份目标检测 NMS 的简化代码(Python 实现)?包含 IoU 计算、候选框排序、迭代抑制的完整逻辑,能直观看到 NMS 如何删除重复框。

















 727
727

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









