




#本篇只是随笔小记
试了一下,拿正弦位置编码直接做自注意力,如果手算注意力权重,应该是这样的:
attention_scores = torch.matmul(pos_x, pos_x.T)/512**0.5 # (seq_len, seq_len)
# 应用 softmax 来获得注意力权重
attention_weights = torch.softmax(attention_scores, dim=-1)可视化的效果是这样的:
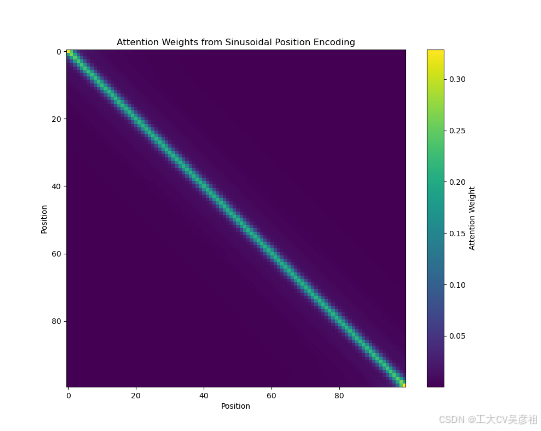
如果用nn.MultiheadAttention返回注意力权重矩阵,应该是这样的:
q = torch.tensor(pos_x)
q = q.reshape(100,512)
q = q[:,None,:]
print(q.shape)
self_attn = nn.MultiheadAttention(num_pos_feats, num_heads=2)
# 手动设置权重和偏置为单位矩阵和零
#identity = torch.eye(512)
#self_attn.in_proj_weight.data = torch.cat([identity, identity, identity])
#self_attn.in_proj_bias.data = torch.zeros(3 * 512)
temp = self_attn(q, q, q)[1]
print(temp)
temp = temp.squeeze().detach().numpy()
#temp = temp.detach().numpy()
print(temp.shape)可视化结果是这样的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7789
7789

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









