




 distribute by是Hive中控制数据在Map端分发到Reduce端的策略,常用于解决分区文件大小不均的问题。通过结合rand()函数和调整spark.sql.shuffle.partitions,可以有效地控制分区下的文件数。文章介绍了两种场景:一是静态分区,通过distribute by rand()结合分区限制文件数量;二是动态分区,利用distribute by和sort by组合确保数据有序并平衡文件大小。此外,文章还简单提到了cluster by的作用,它结合了distribute by和sort by的功能。
distribute by是Hive中控制数据在Map端分发到Reduce端的策略,常用于解决分区文件大小不均的问题。通过结合rand()函数和调整spark.sql.shuffle.partitions,可以有效地控制分区下的文件数。文章介绍了两种场景:一是静态分区,通过distribute by rand()结合分区限制文件数量;二是动态分区,利用distribute by和sort by组合确保数据有序并平衡文件大小。此外,文章还简单提到了cluster by的作用,它结合了distribute by和sort by的功能。
distribute by是控制在map端如何拆分数据给reduce端的。hive会根据distribute by后面列,对应reduce的个数进行分发,默认是采用hash算法.
大部分情况都用于解决Map输出的文件大小不均,Reduce输出文件大小不均,小文件过多,文件超大等情况.
背景:
1.在很多情况下,使用spark sql insert overwrite 表时,由于spark.sql.shuffle.partitions的限定导致分区文件数过多的情况
2.动态分区过多,个别分区下文件大小不均,例如数据延迟等情况,如何控制不同分区下文件的个数
第一种情况: 采用下面方式可以控制此分区下文件个数,具体由业务决定
insert overwrite table temp partition(day)
select c.* from
(select a.*, cast(rand() * 10 as int) as fileNum
(select * from user ) a
left join
(select * from test) b
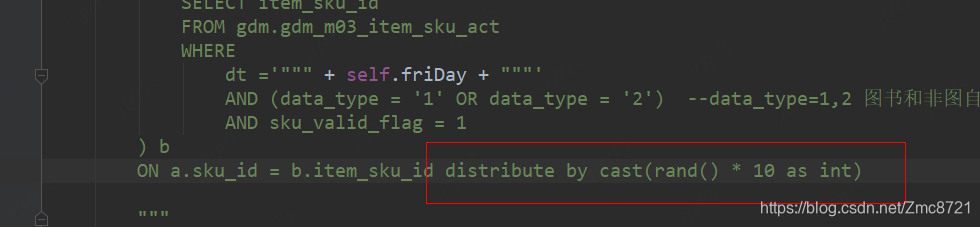
on a.user_id =b.user_id ) c distribute by fileNum
如 :
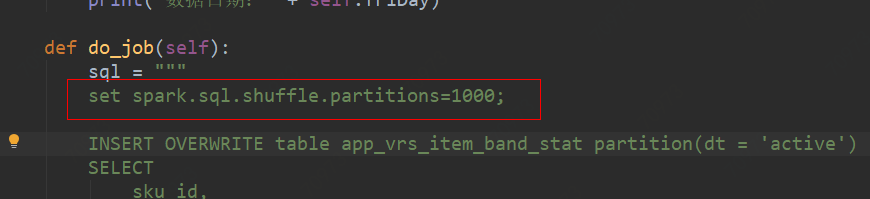
 原本小文件有1000个,加上distribue by 后 ,只有12个小文件。
原本小文件有1000个,加上distribue by 后 ,只有12个小文件。
第二种情况:由于面对多个分区,每个分区下数据大小不一致,代码中往往是在创建临时表时重分区控制最终的文件数,但并不能满足所有分区.
解决方式:distribute by rand() 将对数据进行打散,打散的数据会根据spark.sql.shuffle.partitions=
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6903
6903

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









