




Disentangled Causal Embedding With Contrastive Learning For Recommender System

摘要
推荐系统通常依赖观察到的用户交互数据来构建个性化推荐模型,并假设这些观察数据能够反映用户的兴趣。然而,用户与某一物品的交互也可能是由于从众心理,即跟随热门物品的需求所导致的。大多数现有研究忽略了用户的从众心理,并将其与兴趣混为一谈,这可能导致推荐系统无法提供令人满意的结果。因此,从因果关系的视角来看,解耦这些交互原因是一个关键问题。这对于解决训练数据和测试数据分布不一致(OOD)的问题也有所帮助。然而,由于缺乏区分兴趣和从众心理的信号,加之纯粹因果数据的稀疏性以及物品长尾问题的存在,解耦因果嵌入变得非常具有挑战性。
为了解决这些问题,本文提出了一种名为 DCCL 的框架,它通过对兴趣和从众心理分别进行样本增强,结合对比学习来解耦这两种原因。此外,DCCL 是模型无关的,能够轻松部署到任何工业级在线系统中。
引言
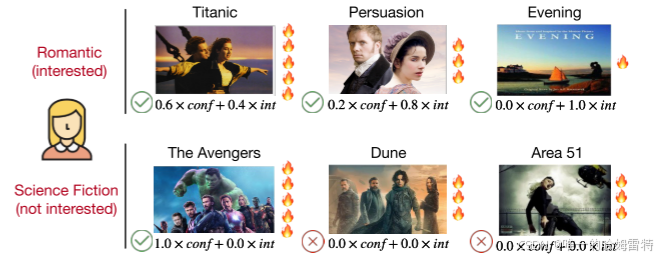
主要对浪漫电影感兴趣的女孩也打算观看最受欢迎的电影之一复仇者联盟。虽然她对科幻小说不感兴趣,但这吸引了她去弄清楚为什么复仇者联盟能受到如此多的关注。此外,她的每一个选择都是由兴趣和从众心理组成的,并且在不同的电影中分布不同。这个例子表明,一致性也是一种内在的需要,值得充分关注和兴趣。
以往的研究大多忽略了从众的价值
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 692
692

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









